
TL / DR
Nous avons discuté de la façon dont AI et WEB3 peuvent chacun se profiter les uns des autres et se compléter mutuellement dans diverses industries verticales telles que les réseaux informatiques, les plateformes proxy et les applications de consommation.En se concentrant sur le domaine vertical des ressources de données, les projets Web émergents offrent de nouvelles possibilités pour l’acquisition, le partage et l’utilisation des données.
-
Les fournisseurs de données traditionnels ont du mal
-
Les solutions Web3 s’efforcent de remodeler l’écosystème de données.Des technologies telles que MPC, la preuve de la connaissance zéro et le notaire TLS assurent l’authenticité et la protection de la confidentialité lorsque les données circulent entre plusieurs sources, tandis que le stockage distribué et l’informatique de bord offrent une plus grande flexibilité et efficacité pour le traitement en temps réel des données.
-
dansRéseau de données décentraliséCette infrastructure émergente a engendré plusieurs projets représentatifs, OpenLayer (modular réel data couche), l’herbe (en utilisant une bande passante inactive de l’utilisateur et les réseaux de nœuds de robot de robot décentralisés) et VANA (réseaux de souveraineté des données utilisateur), avec différent, le chemin technique ouvre de nouveaux prospects pour Formation de l’IA et des champs d’application.
-
Grâce à la capacité de crowdsourcing, à la couche d’abstraction sans confiance et aux mécanismes d’incitation basés sur les jetons, l’infrastructure de données décentralisée peut fournir des solutions plus privées, sécurisées, efficaces et économiques que les fournisseurs de services d’hyperscale Web2, et donner aux utilisateurs la possibilité de les utiliser. , construire un écosystème numérique plus ouvert, sécurisé et interconnecté.
1 et 1La vague de la demande de données
Les données sont devenues un moteur clé de l’innovation et de la prise de décision dans diverses industries.UBS prévoit que le volume mondial des données devrait augmenter de plus de dix fois à 660 ZB entre 2020 et 2030, et d’ici 2025, chaque personne dans le monde générera 463 EB (exaoctets, 1EB = 1 milliard Go) de données par personne par personne par personne jour.Le marché des données en tant que service (DAAS) se développe rapidement et, selon un rapport de Grand View Research, le marché mondial DAAS est évalué à 14,36 milliards de dollars américains en 2023 et devrait croître à un TCAC de 28,1% par 2030, atteignant finalement 768. 100 millions de dollars.Derrière ces chiffres à forte croissance se trouve la demande de données de confiance en temps réel de haute qualité dans plusieurs domaines industriels.
La formation du modèle AI repose sur une grande quantité d’entrée de données pour identifier les modèles et ajuster les paramètres.Après la formation, l’ensemble de données est également nécessaire pour tester les capacités de performance et de généralisation du modèle.De plus, les agents d’IA, en tant que formulaire de demande intelligent émergent prévisible à l’avenir, nécessitent des sources de données en temps réel et fiables pour assurer une prise de décision et une exécution de tâches précises.
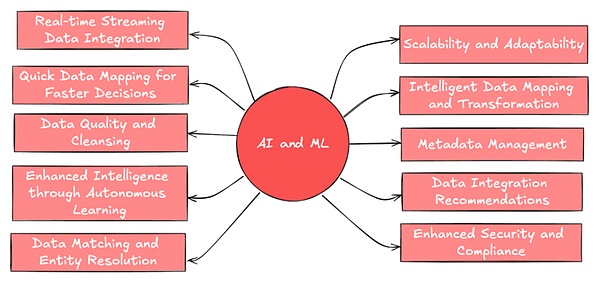
(Source: Leewayhertz)
La demande d’analyse commerciale devient également diversifiée et étendue, et est devenue l’outil de base pour stimuler l’innovation des entreprises.Par exemple, les plateformes de médias sociaux et les sociétés d’études de marché ont besoin de données de comportement des utilisateurs fiables pour formuler des stratégies et un aperçu des tendances, intégrer plusieurs données de plusieurs plateformes sociales et créer un portrait plus complet.
Pour l’écosystème Web3, des données fiables et réelles sont également nécessaires sur la chaîne pour prendre en charge de nouveaux produits financiers.Au fur et à mesure que de plus en plus de nouveaux actifs sont tokenisés, des interfaces de données flexibles et fiables sont nécessaires pour soutenir le développement et la gestion des risques de produits innovants, permettant à des contrats intelligents d’être exécutés en fonction des données vérifiables en temps réel.
En plus de ce qui précède, il y a des recherches scientifiques, l’Internet des objets (IoT), etc.De nouveaux cas d’utilisation La demande de données diverses en temps réel dans diverses industries augmente, tandis que les systèmes traditionnels peuvent avoir du mal à faire face à des volumes de données croissants et à des demandes changeantes.
2. Limites et problèmes de l’écologie des données traditionnelles
Un écosystème de données typique comprend la collecte de données, le stockage, le traitement, l’analyse et l’application.Le modèle centralisé est caractérisé par la collecte et le stockage des données centralisés, la gestion et le fonctionnement et la maintenance par l’équipe informatique de base de base, et un contrôle d’accès strict est mis en œuvre.
Par exemple, l’écosystème de données de Google couvre plusieurs sources de données, des moteurs de recherche, Gmail aux systèmes d’exploitation Android, et utilise ces plateformes pour collecter des données utilisateur, la stocker dans son centre de données distribué à l’échelle mondiale, puis utiliser des algorithmes pour traiter et analyser pour prendre en charge diverses Développement et optimisation des produits et services.
Par exemple, sur le marché financier, les données et les infrastructures LSEG (anciennement raffiniv) utilisent des données en temps réel et historiques pour obtenir des échanges mondiaux, des banques et d’autres institutions financières importantes, et utilise son propre réseau d’information Reuters pour collecter les nouvelles et l’utilisation liées au marché Ses algorithmes et modèles propriétaires génèrent des données analytiques et une évaluation des risques comme produits supplémentaires.
(Source: Kdnugget.com)
Les architectures de données traditionnelles sont efficaces dans les services professionnels, mais les limites des modèles centralisées deviennent de plus en plus évidentes.En particulier, les écosystèmes de données traditionnels sont confrontés à des défis en termes de couverture, de transparence et de protection de la confidentialité des utilisateurs des sources de données émergentes.Voici quelques exemples:
-
Couverture de données inadéquate: Les fournisseurs de données traditionnels ont des difficultés à capturer et à analyser rapidement les sources de données émergentes telles que le sentiment des médias sociaux, les données de l’appareil IoT.Les systèmes centralisés sont difficiles à acquérir et à intégrer efficacement les données « à longue queue » de nombreuses sources à petite échelle ou sans flux.
Par exemple, l’incident de GameStop en 2021 révèle les limites des fournisseurs de données financières traditionnels lors de l’analyse du sentiment des médias sociaux.Le sentiment des investisseurs sur des plateformes tels que Reddit a rapidement changé la tendance du marché, mais les terminaux de données comme Bloomberg et Reuters n’ont pas réussi à capturer ces dynamiques en temps opportun, ce qui entraîne un décalage des prévisions de marché.
-
L’accessibilité des données est limitée: Le monopole limite l’accessibilité.De nombreux fournisseurs traditionnels ouvrent certaines de leurs données via des services API / Cloud, mais les coûts d’accès élevés et les processus d’autorisation complexes augmentent toujours la difficulté de l’intégration des données.
Il est difficile pour les développeurs en chaîne d’accéder rapidement à des données hors chaîne fiables, et les données de haute qualité sont monopolisées par quelques géants, et le coût d’accès est élevé.
-
Problèmes de transparence et de crédibilité des données: De nombreux fournisseurs de données centralisés manquent de transparence dans leurs méthodes de collecte et de traitement des données et manquent de mécanismes efficaces pour vérifier l’authenticité et l’intégrité des données à grande échelle.La vérification des données en temps réel à grande échelle reste un problème complexe, et la nature de la centralisation augmente également le risque de données falsifiées ou manipulées.
-
Protection de la vie privée et propriété des données: Les grandes entreprises technologiques ont utilisé des données d’utilisateurs à grande échelle.En tant que créateurs de données privées, il est difficile pour les utilisateurs d’obtenir les récompenses qu’ils méritent.Les utilisateurs ne savent souvent pas comment leurs données sont collectées, traitées et utilisées, et il est également difficile de déterminer la portée et le moyen d’utiliser les données.La surexploitation et l’utiliser conduisent également à de sérieux risques de confidentialité.
Par exemple, l’incident de Cambridge Analytica de Facebook a exposé d’énormes vulnérabilités dans la façon dont les fournisseurs de données traditionnels peuvent utiliser la transparence et la confidentialité.
-
Île de données: De plus, les données en temps réel provenant de différentes sources et formats sont difficiles à intégrer rapidement, ce qui affecte la possibilité d’une analyse complète.Beaucoup de données sont souvent verrouillées dans une organisation, limitant le partage de données et l’innovation entre les industries et entre les organisations, et l’effet de silo de données entrave l’intégration et l’analyse des données.
Par exemple, dans l’industrie de la consommation, les marques doivent intégrer les données des plateformes de commerce électronique, des magasins physiques, des médias sociaux et des études de marché, mais ces données peuvent être difficiles à intégrer en raison de l’incohérence ou de la quarantaine du format de la plate-forme.Par exemple, des entreprises de voyage partagées comme Uber et Lyft, bien qu’elles collectent toutes les deux une grande quantité de données en temps réel sur le transport, les besoins des passagers et la localisation géographique des utilisateurs, ne peuvent pas être proposées et partagées et intégrées en raison de la concurrence.
De plus, il existe également des problèmes tels que la rentabilité et la flexibilité.Les fournisseurs de données traditionnels répondent activement à ces défis, mais la technologie Web3 émergente offre de nouvelles idées et possibilités pour résoudre ces problèmes.
3 et 3Écosystème de données web3
Depuis la publication de solutions de stockage décentralisées telles que les IPF (système de fichiers interplanétaires) en 2014, une série de projets émergents ont émergé dans l’industrie, déterminé à résoudre les limites de l’écosystème de données traditionnel.Nous voyons que les solutions de données décentralisées ont formé un écosystème interconnecté à plusieurs niveaux couvrant toutes les étapes du cycle de vie des données, y compris la génération de données, le stockage, l’échange, le traitement et l’analyse, la vérification et la sécurité, ainsi que la confidentialité et la propriété.
-
Stockage de données: Le développement rapide de Filecoin et Arweave prouve que le stockage décentralisé (DCS) devient un changement de paradigme dans l’espace de stockage.Le régime DCS réduit le risque de défaillance à un seul point grâce à une architecture distribuée tout en attirant des participants avec une rentabilité plus compétitive.Avec l’émergence d’une série de cas d’applications à grande échelle, la capacité de stockage DCS a montré une croissance explosive (par exemple, la capacité de stockage totale du réseau Filecoin a atteint 22 exabytes en 2024).
-
Traitement et analyse: Les plates-formes de calcul de données décentralisées telles que Fluence améliorent le temps réel et l’efficacité du traitement des données via la technologie informatique Edge, et sont particulièrement adaptés aux scénarios d’application tels que l’Internet des objets (IoT) et l’inférence IA qui nécessitent des performances élevées en temps réel.Le projet Web3 utilise des technologies telles que l’apprentissage fédéré, la confidentialité différentielle, l’environnement d’exécution de confiance et le cryptage entièrement homomorphe pour fournir une protection et des compromis flexibles sur la confidentialité sur la couche informatique.
-
Plateforme de marché des données / d’échange: Afin de promouvoir la quantification et la circulation de la valeur des données, Ocean Protocol a créé des canaux d’échange de données efficaces et ouverts par le biais de mécanismes de tokenisation et de dex, comme aider les sociétés de fabrication traditionnelles (la société mère de Mercedes-Benz Daimler) coopérer pour développer le marché des échanges de données pour les aider à partager des données dans la gestion de la chaîne d’approvisionnement.Streamr, en revanche, a créé un réseau de streaming de données basé sur un abonnement sans autorisation adapté aux scénarios d’analyse IoT et en temps réel, montrant un potentiel exceptionnel dans les projets de transport et de logistique (comme travailler avec des projets finlandais de la ville intelligente).
Avec l’augmentation de la fréquence d’échange et d’utilisation des données, l’authenticité, la crédibilité et la confidentialité des données sont devenues des problèmes clés qui ne peuvent pas être ignorés.Cela a incité l’écosystème Web3 à étendre l’innovation aux domaines de la vérification des données et de la protection de la vie privée, donnant naissance à une série de solutions révolutionnaires.
3.1 Innovation dans la vérification des données et la protection de la confidentialité
De nombreux projets de technologie Web3 et natifs s’efforcent de résoudre l’authenticité des données et les problèmes de protection des données privées.En plus de ZK, MPC et d’autres technologies ont été largement utilisées, parmi lesquelles le Notary Protocole de sécurité de la couche de transport (notaire TLS) est particulièrement digne d’attention en tant que méthode de vérification émergente.
Introduction au notaire TLS
Le protocole de sécurité de la couche de transport (TLS) est un protocole de chiffrement largement utilisé dans les communications réseau, visant à assurer la sécurité, l’intégrité et la confidentialité de la transmission des données entre les clients et les serveurs.Il s’agit d’une norme de chiffrement commune dans la communication réseau moderne et est utilisée dans les HTTP, les e-mails, la messagerie instantanée et d’autres scénarios.
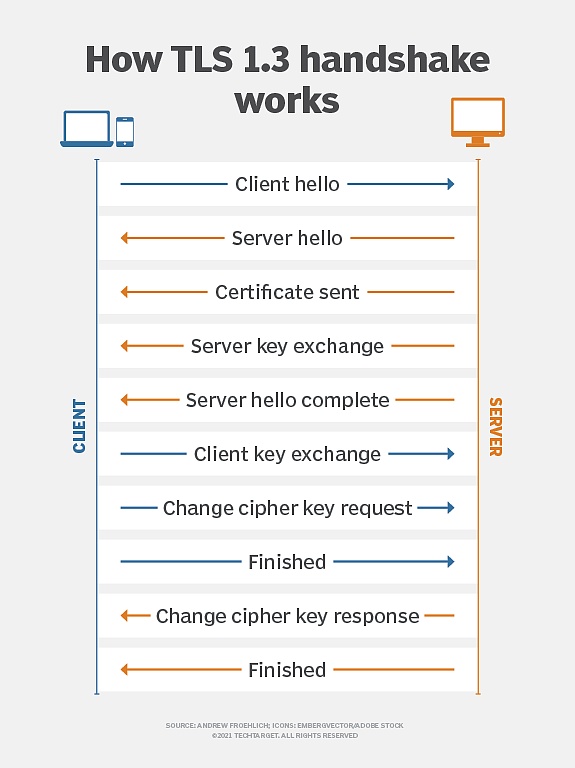
(Principe de cryptage TLS, source: TechTarget)
À sa naissance il y a dix ans, l’objectif initial de TLS Notary était de vérifier l’authenticité des sessions TLS en introduisant des « notaires » tiers en dehors du client (prover) et du serveur.
En utilisant la technologie de segmentation clé, la clé principale de la session TLS est divisée en deux parties, tenues par le client et le notaire.Cette conception permet aux notaires de participer au processus de vérification en tant que tiers de confiance, mais ne peut pas accéder au contenu de communication réel.Ce mécanisme de notarisation est conçu pour détecter les attaques de l’homme au milieu, prévenir les certificats frauduleux, s’assurer que les données de communication ne sont pas falsifiées pendant la transmission et permettre aux tiers de confiance de confirmer la légitimité des communications tout en protégeant la confidentialité de la communication.
Par conséquent, TLS Notary fournit une vérification sécurisée des données et équilibre efficacement les exigences de vérification et la protection de la confidentialité.
En 2022, le projet TLS Notary est reconstruit par le laboratoire de recherche sur l’exploration de la vie privée et de l’extension de la Fondation Ethereum (PSE).La nouvelle version du protocole TLS Notary est réécrite à partir de zéro dans le langage Rust, intègre des protocoles de cryptage plus avancés (tels que MPC). non divulgué de contenu de données.Tout en maintenant la fonction de vérification de notary TLS notary d’origine, elle améliore considérablement les capacités de protection de la confidentialité, ce qui le rend plus adapté aux besoins actuels et futurs de confidentialité des données.
3.2 Variations et extensions du notaire TLS
Ces dernières années, la technologie du notaire TLS a également évolué en permanence et s’est développée sur la base du développement et a produit plusieurs variantes, améliorant davantage les fonctions de confidentialité et de vérification:
-
zktls: Une version améliorée de la confidentialité de TLS Notary, combinée à la technologie ZKP, permet aux utilisateurs de générer des preuves cryptées des données de la page Web sans exposer aucune information sensible.Il convient aux scénarios de communication qui nécessitent une protection contre la confidentialité extrêmement élevée.
-
3P-TLS (TLS tri-partis): Le client, le serveur et l’auditeur sont introduits pour permettre aux auditeurs de vérifier la sécurité de la communication sans divulguer le contenu de communication.Ce protocole est très utile dans les scénarios où la transparence est requise, mais une protection de la vie privée est requise, telles que les examens de conformité ou les audits des transactions financières.
Les projets Web3 utilisent ces technologies de chiffrement pour améliorer la vérification des données et la protection de la confidentialité, briser le monopole des données, résoudre des silos de données et des problèmes de transmission dignes de confiance et permettent aux utilisateurs de prouver leur vie privée sans révéler leurs dossiers d’achat pour les comptes de médias sociaux et les prêts financiers. , Informations professionnelles et de certification académique, telles que:
-
Reclaim Protocol utilise la technologie ZKTLS pour générer des preuves de connaissances zéro du trafic HTTPS, permettant aux utilisateurs d’importer solidement des données d’activité, de réputation et d’identité à partir de sites Web externes sans exposer des informations sensibles.
-
ZKPass combine la technologie 3P-TLS pour permettre aux utilisateurs de vérifier les données privées du monde réel sans fuite.
-
Opacity Network est basé sur ZKTLS, permettant aux utilisateurs de prouver en toute sécurité leur activité sur diverses plates-formes (telles que Uber, Spotify, Netflix, etc.) sans accéder directement aux API de ces plates-formes.Implémentez la preuve d’activité multiplateforme.
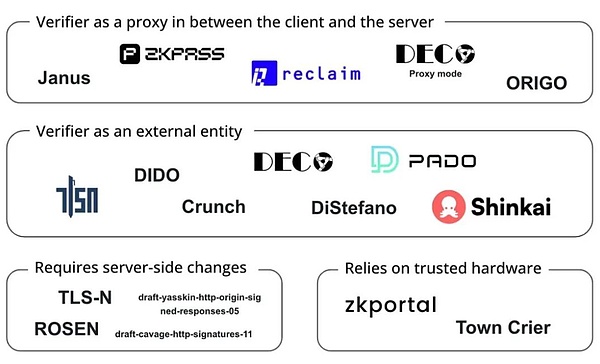
(Projets fonctionnant oN TLS Oracles, Source: Bastian Wetzel)
En tant que lien important dans la chaîne d’écosystème de données, la vérification des données Web3 a de larges perspectives d’application.Cependant, le développement de la technologie de vérification de l’authenticité n’est que le début de la construction d’une nouvelle génération d’infrastructures de données.
4. Réseau de données décentralisé
Certains projets combinent la technologie de vérification des données susmentionnée pour faire des explorations plus approfondies en amont de l’écosystème de données, à savoir la traçabilité des données, la collecte de données distribués et la transmission de confiance.Voici plusieurs projets représentatifs: OpenLayer, Grass et Vana, qui montrent un potentiel unique dans la construction d’une infrastructure de données de nouvelle génération.
4.1 OpenLayer
OpenLaYer est l’un des projets d’accélération de l’entrepreneuriat Crypto A16Z Crypto Spring 2024, en tant que première couche de données réelle modulaire, déterminée à fournir une solution modulaire innovante pour coordonner la collecte, la vérification et la transformation de données pour répondre à la fois Web2 et Web3 dont les entreprises ont besoin.Openlayer a attiré le soutien de fonds bien connus et d’investisseurs providentiels, notamment Geometry Ventures, Longhash Ventures.
Il y a plusieurs défis dans la couche de données traditionnels: le manque de mécanisme de vérification de confiance, la dépendance à l’architecture centralisée conduit à une limitation de l’accès, les données entre différents systèmes manquent d’interopérabilité et de liquidité, et il n’y a pas non plus de mécanisme d’allocation de valeur de données équitable.
Un problème plus concret est que les données de formation de l’IA deviennent de plus en plus rares aujourd’hui.Sur Internet public, de nombreux sites Web ont commencé à utiliser des restrictions anti-frawler pour empêcher les entreprises d’IA de ramper les données à grande échelle.
Et dansDonnées privées et propriétairesD’une part, la situation est plus compliquée.En vertu de ce statu quo, les utilisateurs ne peuvent pas obtenir de prestations directes en toute sécurité en fournissant des données privées et ne sont donc pas disposées à partager ces données sensibles.
Pour résoudre ces problèmes, Openlayer a construit une couche de données authentique modulaire avec la technologie de vérification des données et a coordonné le processus de collecte, de vérification et de conversion des données dans des incitations décentralisées + économiques, pour les sociétés Web2 et Web3. infrastructure.
4.1.1 Les composants centraux de la conception modulaire OpenLayer
OpenLayer fournit une plate-forme modulaire pour simplifier le processus de collecte de données, de vérification et de conversion de confiance:
a) OpenNodes
OpenDodes est le composant central responsable de la collecte de données décentralisées dans l’écosystème OpenLayer.
OpenNodes prend en charge trois types de données principaux pour répondre aux besoins de différents types de tâches:
-
Données Internet accessibles au public (telles que les données financières, les données météorologiques, les données sportives et les flux de médias sociaux)
-
Données privées de l’utilisateur (telles que l’historique de visualisation Netflix, l’historique des commandes Amazon, etc.)
-
Les données autodéclarées provenant de sources sécurisées (telles que les données signées par un propriétaire propriétaire ou vérifiées par un matériel de confiance spécifique).
Les développeurs peuvent facilement ajouter de nouveaux types de données, spécifier de nouvelles sources de données, des exigences et des méthodes de récupération de données, et les utilisateurs peuvent choisir de fournir des données dés-identifiées en échange de récompenses.Cette conception permet au système de se développer en continu pour s’adapter aux nouveaux besoins de données.
b) OpenValidators
OpenValidators est responsable de la vérification des données après la collecte, permettant aux consommateurs de données de confirmer que les données fournies par l’utilisateur sont exactement adaptées à la source de données.Toutes les méthodes de vérification fournies peuvent être vérifiées par chiffrement et les résultats de vérification peuvent être vérifiés par la suite.Pour le même type de preuve, il existe plusieurs fournisseurs différents pour fournir des services.Les développeurs peuvent choisir le fournisseur de vérification le plus approprié en fonction de leurs besoins.
Dans les cas d’utilisation initiaux, en particulier pour les données publiques ou privées de l’API Internet, OpenLayer utilise TLSNotary comme solution de vérification pour exporter les données de toute application Web et prouver l’authenticité des données sans compromettre la confidentialité.
Non limité au tlsnotary, grâce à sa conception modulaire, le système de vérification peut facilement accéder à d’autres méthodes de vérification en fonction de différents types de données et de besoins de vérification, y compris, mais sans s’y limiter:
-
Connexions TLS attestées: utilisez un environnement d’exécution de confiance (TEE) pour établir une connexion TLS certifiée pour assurer l’intégrité et l’authenticité des données pendant la transmission.
-
Enclaves sécurisés: utilisez des environnements d’isolement sécurisés au niveau matériel (tels que Intel SGX) pour traiter et vérifier les données sensibles pour fournir un niveau de protection des données plus élevé.
-
Générateurs de preuve ZK: ZKP intégré, permettant la vérification des propriétés de données ou les résultats de calcul sans révéler les données d’origine.
-
Convertissez les données en format Oracle sur chaîne, ce qui est pratique pour l’utilisation directe des contrats intelligents.
-
Convertissez les données brutes non structurées en données structurées et effectuez le prétraitement pour la formation IA et à d’autres fins.
-
Couche de liquidité de données
-
Couche de portabilité des données
-
Connectome universel
c) OpenConnect
OpenConnect est le module de base de l’écosystème OpenLayer responsable de la conversion des données et de la réalisation de la disponibilité, du traitement des données provenant de diverses sources, de l’interopérabilité des données entre différents systèmes et de la satisfaction des besoins des différentes applications.Par exemple:
Pour les données des comptes privés des utilisateurs, OpenConnect fournit une désensibilisation aux données pour protéger la confidentialité, et fournit également des composants pour améliorer la sécurité pendant le partage de données et réduire les violations et les abus de données.Afin de répondre aux besoins des données en temps réel pour les applications telles que l’IA et la blockchain, OpenConnect prend en charge une conversion efficace de données en temps réel.
À l’heure actuelle, grâce à l’intégration avec Eigenlayer, l’opérateur OpenLayer AVS surveille les tâches de demande de données, est responsable de la rampe de données et de la vérification, puis rapporte les résultats au système pour engager ou redémarrer les actifs via Eigenlayer pour fournir des garanties financières pour son comportement .Si un comportement malveillant est confirmé, vous risquez le risque d’être condamné à une amende et à confisquer les actifs promis.En tant que l’un des premiers AVS (Active Verification Services) sur le réseau principal Eigenlayer, Openlayer a attiré plus de 50 opérateurs et 4 milliards de dollars d’actifs de réapparition.
En général, la couche de données décentralisée construite par Openlayer étend la portée et la diversité des données disponibles sans sacrifier l’aspect pratique et l’efficacité, tout en assurant l’authenticité des données par la technologie de chiffrement et les incitations économiques.Sa technologie propose un large éventail de cas d’utilisation pratiques pour les DAPP Web3 cherchant à obtenir des informations hors chaîne, des modèles d’IA qui nécessitent une entrée réelle pour s’entraîner et déduire, et les entreprises qui souhaitent segmenter et localiser les utilisateurs en fonction de leurs identités et réputations existantes.Les utilisateurs peuvent également valoriser leurs données privées.
4.2 herbe
Grass est un projet phare développé par WYND Network pour créer une plate-forme de données de formation Web décentralisée et de formation sur l’IA.À la fin de 2023, le Grass Project a achevé un tour de semences de 3,5 millions de dollars dirigé par Polychain Capital et Tribe Capital.Immédiatement après, en septembre 2024, le projet a inauguré un financement de série A dirigé par HackVC, avec des établissements d’investissement bien connus tels que Polychain, Delphi, Lattice et Brevan Howard ont également participé.
Nous avons mentionné que la formation d’IA nécessite une nouvelle exposition aux données, et l’une des solutions consiste à utiliser plusieurs IP pour percer les autorisations d’accès aux données et alimenter les données d’IA.L’herbe a commencé pour créer un réseau de nœuds de robottes distribué, dédié à l’utilisation de la bande passante inactive des utilisateurs pour collecter et fournir des ensembles de données vérifiables pour l’entraînement en IA sous la forme d’une infrastructure physique décentralisée.Le nœud achemine les demandes Web via la connexion Internet de l’utilisateur, accède aux sites Web publics et compile des ensembles de données structurés.Il utilise la technologie de l’informatique Edge pour effectuer un nettoyage et une mise en forme préliminaires des données pour améliorer la qualité des données.
L’herbe adopte l’architecture de rollup de données de la couche 2 de Solana, construite sur Solana pour améliorer l’efficacité du traitement.Grass utilise un validateur pour recevoir, vérifier et combler les transactions Web à partir de nœuds, générant des preuves ZK pour assurer l’authenticité des données.Les données vérifiées sont stockées dans le grand livre des données (L2) et liées à la preuve de la chaîne L1 correspondante.
4.2.1 Composants principaux de l’herbe
a) nœud d’herbe
Semblable à OpenNodes, les utilisateurs C-End installent des applications de gazon ou des extensions de navigateur et les exécuter, utilisez une bande passante inactive pour effectuer des opérations de rampage de réseau, les nœuds acheminent les demandes Web via la connexion Internet de l’utilisateur, accédez aux sites Web publics et compilez des ensembles de données structurés et utilisez des comptes Edge Computing de l’utilisateur Technologie à effectuer.Les utilisateurs reçoivent des récompenses en jetons d’herbe en fonction de la bande passante et de la quantité de données contribuées.
b) routeurs
Connectez les nœuds et validateurs de l’herbe, gérez les réseaux de nœuds et relais la bande passante.Les routeurs sont incités à opérer et à recevoir des récompenses, la proportion de proportion de proportion de proportion de proportion de proportion de récompense à la bande passante de vérification totale l’a traversée.
c) Validateurs
Recevoir, vérifier et les transactions Web par lots à partir du routeur, générer des preuves ZK, utiliser un ensemble de clés uniques pour établir une connexion TLS et sélectionner la suite de chiffrement appropriée pour la communication avec le serveur Web cible.Grass utilise actuellement un validateur centralisé et prévoit de déménager au comité du validateur à l’avenir.
d) Processeur ZK (processeur ZK)
Recevez une preuve de génération de chaque données de session de nœud à partir du vérificateur, preuve de validité par lots de toutes les demandes Web et soumettre à la couche 1 (Solana).
e) grand livre des données (Grass L2)
Stockez l’ensemble de données complet et liez-le à la chaîne L1 correspondante (Solana).
f) Modèle d’incorporation de bord
Responsable de la conversion de données Web non structurées en modèles structurés qui peuvent être formés avec l’IA.
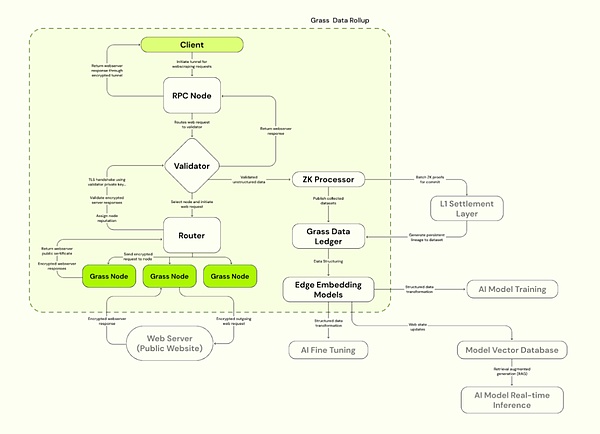
Source: herbe
Analyse et comparaison de l’herbe et de l’Openlayer
Les réseaux distribués OpenLayer et Grass Lentent pour offrir aux entreprises la possibilité d’accéder aux données Internet ouvertes et des informations fermées qui nécessitent une authentification.Le mécanisme d’incitation favorise le partage des données et la production de données de haute qualité.Les deux sont déterminés à créer une couche de données décentralisée pour résoudre le problème de l’accès et de la vérification de l’acquisition de données, mais adoptent des chemins techniques et des modèles commerciaux légèrement différents.
Différentes architectures techniques
Grass utilise l’architecture de rouleau de données de la couche 2 sur Solana et utilise actuellement un mécanisme de vérification centralisé et un seul validateur.En tant que premier lot d’AVS, OpenLayer est construit sur Eigenlayer et utilise des incitations économiques et des mécanismes de confiscation pour réaliserMécanisme de vérification décentralisé.Il adopte également une conception modulaire, mettant l’accent sur l’évolutivité et la flexibilité des services de vérification des données.
Différences de produit
Les deux offrent des produits similaires à C, permettant aux utilisateurs de monétiser la valeur des données via les nœuds.Sur B les cas d’utilisation, Grass fournit un modèle de marché de données intéressant et utilise L2 pour stocker verbalement des données complètes pour fournir aux entreprises d’IA un ensemble de formation structuré, de haute qualité et vérifiable.OpenLayer n’a pas de composant de stockage de données dédié temporaire, mais fournit une gamme plus large de services de vérification de flux de données en temps réel (VAAS). Pour le flux de prix du marché RWA / DEFI / PRÉDICTION, fournissez des données sociales en temps réel, etc.
Par conséquent, la clientèle cible de Grass est principalement destinée aux sociétés de l’IA et aux scientifiques des données, fournissant des ensembles de données de formation à grande échelle et structurés, et servant également des institutions de recherche et des entreprises qui nécessitent un grand nombre d’ensembles de données de réseau; Besoins de données hors chaîne.
Concurrence potentielle à l’avenir
Cependant, compte tenu des tendances de l’industrie, les fonctions des deux projets sont en effet susceptibles de converger à l’avenir.L’herbe peut également fournir des données structurées en temps réel bientôt.En tant que plate-forme modulaire, OpenLayer peut également se développer à la gestion des ensembles de données à l’avenir pour avoir son propre grand livre de données, de sorte que les zones compétitives des deux peuvent progressivement se chevaucher.
De plus, les deux projets peuvent envisager d’ajouter l’étiquetage des données comme un lien clé.L’herbe peut se déplacer plus rapidement à cet égard, car ils ont un énorme réseau de nœuds – il y aurait plus de 2,2 millions de nœuds actifs.Cet avantage donne à Grass le potentiel de fournir des services d’apprentissage par renforcement (RLHF) basés sur la rétroaction humaine, en utilisant une grande quantité de données étiquetées pour optimiser les modèles d’IA.
Cependant, OpenLayer, avec son expertise en vérification des données et en temps réel, peut maintenir ses avantages en matière de qualité et de crédibilité des données.De plus, en tant que l’un des AVE de Eigenlayer, Openlayer peut avoir un développement ultérieur dans le mécanisme de vérification décentralisé.
Bien que les deux projets puissent rivaliser dans certains domaines, leurs forces uniques respectives et leurs voies techniques peuvent également conduire à leurs niches différentes dans l’écosystème de données.
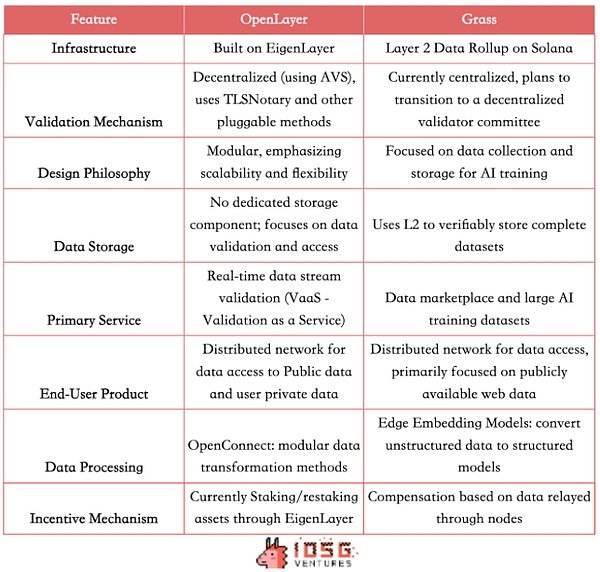
(Source: IOSG, David)
4.3 Vava
En tant que réseau de pool de données centré sur l’utilisateur, Vana s’engage également à fournir des données de haute qualité pour l’IA et les applications connexes.Par rapport à OpenLayer et Grass, Vana adopte plus de chemins technologiques et de modèles commerciaux.Vana a terminé un financement de 5 millions de dollars en septembre 2024, dirigé par Coinbase Ventures.
Lancé à l’origine en 2018 en tant que projet de recherche pour le MIT, Vana vise à devenir une blockchain de couche 1 conçue spécifiquement pour les données privées des utilisateurs.Ses innovations dans la propriété des données et l’allocation de valeur permettent aux utilisateurs de profiter des modèles d’IA formés sur leurs données.Le noyau de Vana est par le biais de confiance, privé et attribuablePool de liquidité de donnéeset innovantPreuve de contributionMécanismes pour réaliser la circulation et la valeur des données privées:
4.3.1.
VANA introduit un concept unique de Data Liquidity Pool (DLP): En tant que composant central du réseau VANA, chaque DLP est un réseau indépendant entre pairs pour agréger des types spécifiques d’actifs de données.Les utilisateurs peuvent télécharger leurs données privées (telles que l’historique des achats, les habitudes de navigation, les activités de médias sociaux, etc.) sur un DLP spécifique et choisir de manière flexible d’autoriser ces données à des tiers spécifiques à utiliser.Les données sont intégrées et gérées par le biais de ces pools de liquidité, qui sont identifiés pour garantir la confidentialité des utilisateurs tout en permettant aux données de participer à des applications commerciales, comme pour la formation du modèle d’IA ou l’étude de marché.
Les utilisateurs soumettent des données à DLP et reçoivent des jetons DLP correspondants (chaque DLP a une récompense spécifique). .Non seulement les utilisateurs peuvent partager des données, mais ils peuvent également obtenir des avantages continus des appels ultérieurs aux données (et fournir un suivi visuel).Contrairement aux ventes traditionnelles de données à temps unique, Vana permet aux données de continuer à participer au cycle économique.
4.3.2.
L’une des autres innovations de base de Vana estPreuve de contribution(Preuve de contribution) Mécanisme.Il s’agit du mécanisme clé de Vana pour garantir la qualité des données, permettant à chaque DLP de personnaliser les fonctions de preuve de contribution uniques en fonction de ses caractéristiques pour vérifier l’authenticité et l’intégrité des données et évaluer la contribution des données à l’amélioration des performances du modèle d’IA.Ce mécanisme garantit que les contributions des données des utilisateurs sont quantifiées et enregistrées, fournissant ainsi des récompenses aux utilisateurs.Semblable à la « preuve de travail » dans les crypto-monnaies, la preuve de contribution distribue des avantages aux utilisateurs en fonction de la qualité, de la quantité de données apportées par les utilisateurs et de la fréquence d’utilisation.L’exécution automatique des contrats intelligents garantit que les contributeurs reçoivent des récompenses qui correspondent à leurs contributions.
Architecture technique de Vana
Il s’agit de la couche centrale de Vana, responsable de la contribution, de la vérification et de l’enregistrement des données aux DLP, et introduit des données à la chaîne en tant qu’actif numérique transférable.Les créateurs DLP déploient des contrats SMART DLP pour fixer l’objectif de la contribution des données, des méthodes de vérification et des paramètres de contribution.Les contributeurs de données et les gardiens soumettent des données pour la vérification, et le module de preuve de contribution (POC) effectue une évaluation de vérification et de valeur des données, et accorde des droits et des récompenses de gouvernance en fonction des paramètres.
Il s’agit d’une plate-forme de données ouverte pour les contributeurs de données et les développeurs, et c’est aussi la couche d’application de VANA.La couche de portabilité des données fournit un espace de collaboration pour les contributeurs de données et les développeurs afin de créer des applications à l’aide de la liquidité de données accumulée dans DLPS.Fournit une infrastructure pour la formation distribuée des modèles appartenant à des utilisateurs et du développement AI DAPP.
Un grand livre décentralisé est également un tableau de flux de données en temps réel qui traverse l’ensemble de l’écosystème VANA.Assurez-vous un transfert efficace des jetons DLP et fournissez un accès aux données inter-DLP aux applications.Compatible avec EVM, permettant l’interopérabilité avec d’autres réseaux, protocoles et applications Defi.
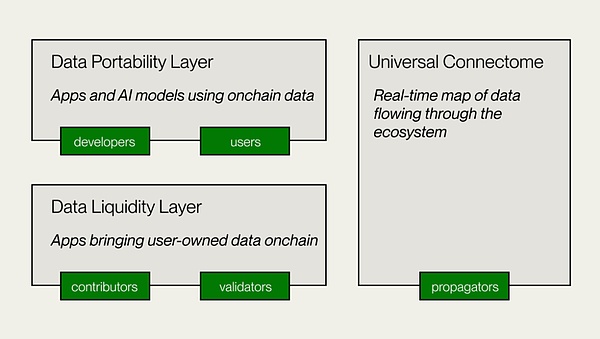
(Source: Vana)
Vana fournit un chemin relativement différent, en se concentrant sur la liquidité et l’autonomisation de la valeur des données des utilisateurs. L’interopérabilité et les licences fournissent une nouvelle solution.Créez finalement un écosystème Internet ouvert qui permet aux utilisateurs de posséder et de gérer leurs propres données, ainsi que des produits intelligents créés à partir de ces données.
5. La proposition de valeur des réseaux de données décentralisés
Le scientifique des données Clive Humby a déclaré en 2006 que les données sont du pétrole à la nouvelle ère.Au cours des 20 dernières années, nous avons assisté au développement rapide de la technologie de « raffinage ».Une technologie telle que l’analyse des mégadonnées et l’apprentissage automatique ont permis une valeur de données sans précédent.Selon les prévisions d’IDC, d’ici 2025, le cercle mondial de données passera à 163 ZB, dont la plupart proviendront des utilisateurs individuels. devra être commercialisé à l’avenir.
Points de douleur des solutions traditionnelles: déverrouiller l’innovation dans web3
Grâce à un réseau de nœuds distribué, la solution de données Web3 perdus par les limites des installations traditionnelles, atteint une acquisition de données plus large et plus efficace et améliore l’efficacité d’acquisition en temps réel et la crédibilité de vérification de données spécifiques.Dans ce processus, la technologie Web3 garantit l’authenticité et l’intégrité des données et peut protéger efficacement la confidentialité des utilisateurs, réalisant ainsi un modèle d’utilisation des données plus juste.Cette architecture de données décentralisée favorise l’acquisition de donnéesDémocratisation.
Qu’il s’agisse du mode de nœud utilisateur d’OpenLayer et de l’herbe, ou de la monétisation par Vana des données privées des utilisateurs, en plus d’améliorer l’efficacité d’une collecte de données spécifique, les utilisateurs ordinaires peuvent partager les dividendes de l’économie des données, en créant un modèle gagnant-gagnant pour les utilisateurs et Les développeurs, afin que les utilisateurs contrôlent et bénéficient vraiment de leurs données et de leurs ressources connexes.
Grâce à l’économie des jetons, la solution de données Web3 a repensé le modèle d’incitation et a créé un mécanisme d’allocation de valeur de données plus équitable.Il a attiré un grand nombre d’utilisateurs, des ressources matérielles et des capitaux pour coordonner et optimiser le fonctionnement de l’ensemble du réseau de données.
Ils ont aussiModularité et évolutivité: Par exemple, la conception modulaire d’OpenLayer offre une flexibilité pour l’itération technologique future et l’expansion écologique.Grâce aux caractéristiques techniques, nous optimisons la méthode d’acquisition de données de la formation des modèles d’IA pour fournir des ensembles de données plus riches et plus diversifiés.
De la génération de données, du stockage, de la vérification à l’échange et à l’analyse, les solutions basées sur wEB3 résolvent de nombreux inconvénients des installations traditionnelles grâce à des avantages technologiques uniques et donnent également aux utilisateurs la possibilité de monétiser des données personnelles, déclenchant un changement fondamental dans le modèle économique de données.Avec le développement et l’évolution de la technologie et l’expansion des scénarios d’application, la couche de données décentralisée devrait devenir la prochaine génération d’infrastructures critiques, ainsi que d’autres solutions de données Web3, fournissant un support pour un large éventail d’industries basées sur les données.







