
TL/DR
Hemos discutido cómo AI y Web3 pueden aprovecharse cada uno y complementarse entre sí en varias industrias verticales, como redes informáticas, plataformas proxy y aplicaciones de consumo.Al centrarse en el campo vertical de los recursos de datos, los proyectos web emergentes proporcionan nuevas posibilidades para la adquisición de datos, el intercambio y la utilización.
-
Los proveedores de datos tradicionales tienen dificultades para satisfacer las necesidades de la IA y otras industrias basadas en datos para datos verificables de alta calidad en tiempo real, especialmente en términos de transparencia, control de usuarios y protección de la privacidad
-
Las soluciones Web3 están funcionando para remodelar el ecosistema de datos.Las tecnologías como MPC, la prueba de conocimiento cero y el notario de TLS aseguran la autenticidad y la protección de la privacidad cuando los datos circulan entre múltiples fuentes, mientras que el almacenamiento distribuido y la computación de borde proporcionan una mayor flexibilidad y eficiencia para el procesamiento de datos en tiempo real.
-
enRed de datos descentralizadaEsta infraestructura emergente ha generado varios proyectos representativos, OpenLayer (capa de datos real modular), hierba (utilizando el ancho de banda inactivo del usuario y las redes de nodo de rastreador descentralizados) y Vana (redes de soberanía de datos del usuario de la capa 1), con diferente la ruta técnica abre nuevas perspectivas para las nuevas perspectivas para AI Capacitación y campos de aplicación.
-
A través de la capacidad de crowdsourcing, los mecanismos de incentivos basados en el token y la infraestructura de datos descentralizada pueden proporcionar soluciones más privadas, seguras, eficientes y económicas que los proveedores de servicios de hiperescala Web2, y brindar a los usuarios la capacidad de usarlo. , construyendo un ecosistema digital más abierto, seguro e interconectado.
1.La ola de demanda de datos
Los datos se han convertido en un impulsor clave de la innovación y la toma de decisiones en diversas industrias.UBS predice que se espera que el volumen de datos global crezca en más de diez veces a 660 ZB entre 2020 y 2030, y para 2025, cada persona en el mundo generará 463 EB (exabytes, 1EB = 1 mil millones de GB) de datos por persona por día.El mercado de datos como servicio (DAAS) se está expandiendo rápidamente, y según un informe de Grand View Research, el mercado Global DAAS está valorado en US $ 14.36 mil millones en 2023 y se espera que crezca a una tasa compuesta anual del 28.1% por 2030, finalmente llegando a 768. $ 100 millones.Detrás de estos números de alto crecimiento está la demanda de datos de confianza en tiempo real de alta calidad en múltiples campos industriales.
El entrenamiento del modelo AI se basa en una gran cantidad de entrada de datos para identificar patrones y ajustar los parámetros.Después de la capacitación, el conjunto de datos también se requiere para probar las capacidades de rendimiento y generalización del modelo.Además, los agentes de IA, como un formulario de aplicación inteligente emergente previsible en el futuro, requieren fuentes de datos en tiempo real y confiables para garantizar la toma de decisiones y la ejecución de tareas precisas.
(Fuente: Leewayhertz)
La demanda de análisis de negocios también se está volviendo diversa y extensa, y se ha convertido en la herramienta central para impulsar la innovación corporativa.Por ejemplo, las plataformas de redes sociales y las compañías de investigación de mercado necesitan datos de comportamiento del usuario confiables para formular estrategias y información sobre las tendencias, integrar múltiples datos de múltiples plataformas sociales y construir un retrato más completo.
Para el ecosistema Web3, también se necesitan datos confiables y reales en la cadena para respaldar algunos nuevos productos financieros.A medida que se están tocando más y más activos nuevos, se necesitan interfaces de datos flexibles y confiables para respaldar el desarrollo y la gestión de riesgos de productos innovadores, lo que permite ejecutar los contratos inteligentes en función de los datos en tiempo real verificables.
Además de lo anterior, hay investigación científica, Internet de las cosas (IoT), etc.Nuevos casos de uso La demanda de datos diversos en tiempo real en diversas industrias está aumentando, mientras que los sistemas tradicionales pueden tener dificultades para hacer frente a los volúmenes de datos en rápido crecimiento y las demandas cambiantes.
2. Limitaciones y problemas de la ecología de datos tradicional
Un ecosistema de datos típico incluye recopilación de datos, almacenamiento, procesamiento, análisis y aplicación.El modelo centralizado se caracteriza por la recopilación y el almacenamiento de datos centralizados, la gestión y la operación y el mantenimiento del equipo de TI de la empresa central, y se implementa un control de acceso estricto.
Por ejemplo, el ecosistema de datos de Google cubre múltiples fuentes de datos, desde motores de búsqueda, Gmail hasta sistemas operativos de Android, y utiliza estas plataformas para recopilar datos de usuario, almacenarlos en su centro de datos distribuido globalmente y luego usar algoritmos para procesar y analizar para varios para admitir varios Desarrollo y optimización de productos y servicios.
Por ejemplo, en el mercado financiero, los datos e infraestructura LSEG (anteriormente Refinitiv) utiliza datos históricos e en tiempo real para obtener intercambios globales, bancos y otras instituciones financieras importantes, y utiliza su propia red de noticias Reuters para recopilar noticias relacionadas con el mercado y usar el uso del mercado. Sus algoritmos y modelos patentados generan datos analíticos y evaluación de riesgos como productos adicionales.
(Fuente: kdnuggets.com)
Las arquitecturas de datos tradicionales son efectivas en los servicios profesionales, pero las limitaciones de los modelos centralizados son cada vez más obvias.En particular, los ecosistemas de datos tradicionales enfrentan desafíos en términos de cobertura, transparencia y protección de la privacidad del usuario de las fuentes de datos emergentes.Aquí hay algunos ejemplos:
-
Cobertura de datos inadecuada: Los proveedores de datos tradicionales tienen desafíos para capturar y analizar rápidamente las fuentes de datos emergentes, como el sentimiento de las redes sociales, los datos del dispositivo IoT.Los sistemas centralizados son difíciles de adquirir e integrar de manera eficiente los datos de «cola larga» de numerosas fuentes a pequeña escala o no convencionales.
Por ejemplo, el incidente de GameStop en 2021 revela las limitaciones de los proveedores de datos financieros tradicionales al analizar el sentimiento de las redes sociales.El sentimiento de los inversores en plataformas como Reddit cambió rápidamente la tendencia del mercado, pero las terminales de datos como Bloomberg y Reuters no pudieron capturar estas dinámicas de manera oportuna, lo que resultó en un retraso en las pronósticos del mercado.
-
La accesibilidad de los datos es limitada: El monopolio limita la accesibilidad.Muchos proveedores tradicionales abren algunos de sus datos a través de servicios API/nube, pero los altos costos de acceso y los procesos de autorización complejos aún aumentan la dificultad de la integración de datos.
Es difícil para los desarrolladores en la cadena acceder rápidamente a datos confiables fuera de la cadena, y algunos gigantes monopolizan los datos de alta calidad, y el costo de acceso es alto.
-
Problemas de transparencia de datos y credibilidad: Muchos proveedores de datos centralizados carecen de transparencia en sus métodos de recopilación y procesamiento de datos, y carecen de mecanismos efectivos para verificar la autenticidad e integridad de los datos a gran escala.La verificación de datos en tiempo real a gran escala sigue siendo un problema complejo, y la naturaleza de la centralización también aumenta el riesgo de que los datos sean manipulados o manipulados.
-
Protección de la privacidad y propiedad de datos: Grandes compañías de tecnología han utilizado datos de usuarios a gran escala.Como creadores de datos privados, es difícil para los usuarios obtener las recompensas que se merecen.Los usuarios a menudo no tienen idea de cómo se recopilan, procesan y usan sus datos, y también es difícil determinar el alcance y la forma de usar los datos.Exagerar y usarlo también conduce a serios riesgos de privacidad.
Por ejemplo, el incidente de Cambridge Analytica de Facebook expuso enormes vulnerabilidades en cómo los proveedores de datos tradicionales pueden usar transparencia y privacidad.
-
Isla de datos: Además, los datos en tiempo real de diferentes fuentes y formatos son difíciles de integrar rápidamente, lo que afecta la posibilidad de un análisis integral.Muchos datos a menudo se bloquean dentro de una organización, lo que limita el intercambio de datos e innovación entre las industrias y las organizaciones, y el efecto de silo de datos dificulta la integración y el análisis de datos de dominio cruzado.
Por ejemplo, en la industria del consumidor, las marcas necesitan integrar datos de plataformas de comercio electrónico, tiendas físicas, redes sociales e investigación de mercado, pero estos datos pueden ser difíciles de integrar debido a la inconsistente o la cuarentena del formato de la plataforma.Por ejemplo, las compañías de viajes compartidas como Uber y Lyft, aunque ambas recopilan una gran cantidad de datos en tiempo real sobre el transporte, las necesidades de los pasajeros y la ubicación geográfica de los usuarios, no pueden ser propuestas, compartidas e integradas debido a la competencia.
Además, también hay problemas como la rentabilidad y la flexibilidad.Los proveedores de datos tradicionales están respondiendo activamente a estos desafíos, pero la tecnología emergente Web3 proporciona nuevas ideas y posibilidades para resolver estos problemas.
3.Ecosistema de datos Web3
Desde el lanzamiento de soluciones de almacenamiento descentralizadas, como IPFS (sistema de archivos interplanetario) en 2014, han surgido una serie de proyectos emergentes en la industria, comprometidos a resolver las limitaciones del ecosistema de datos tradicional.Vemos que las soluciones de datos descentralizadas han formado un ecosistema interconectado de nivel múltiple que cubre todas las etapas del ciclo de vida de datos, incluida la generación de datos, el almacenamiento, el intercambio, el procesamiento y el análisis, la verificación y la seguridad, y la privacidad y la propiedad.
-
Almacenamiento de datos: El rápido desarrollo de Filecoin y Arweave demuestra que el almacenamiento descentralizado (DC) se está convirtiendo en un cambio de paradigma en el espacio de almacenamiento.El esquema DCS reduce el riesgo de falla de un solo punto a través de una arquitectura distribuida mientras atrae a los participantes con una rentabilidad más competitiva.Con la aparición de una serie de casos de aplicación a gran escala, la capacidad de almacenamiento de DCS ha mostrado un crecimiento explosivo (por ejemplo, la capacidad de almacenamiento total de la red Filecoin ha alcanzado 22 exabytes en 2024).
-
Procesamiento y análisis: Las plataformas de computación de datos descentralizadas como Fluence mejoran el tiempo real y la eficiencia del procesamiento de datos a través de la tecnología de computación de borde, y son especialmente adecuadas para escenarios de aplicación como Internet de las cosas (IoT) y la inferencia de IA que requieren un alto rendimiento en tiempo real.El proyecto Web3 utiliza tecnologías como el aprendizaje federado, la privacidad diferencial, el entorno de ejecución de confianza y el cifrado totalmente homomórfico para proporcionar protección de privacidad flexible y compensaciones en la capa informática.
-
Mercado de datos/plataforma de intercambio: Para promover la cuantificación y la circulación del valor de los datos, el protocolo oceánico ha creado canales de intercambio de datos eficientes y abiertos a través de mecanismos de tokenización y DEX, como ayudar a las empresas manufactureras tradicionales (empresa matriz de Mercedes-Benz Daimler) para desarrollar el mercado de intercambio de datos para ayudarlos a compartir datos en la gestión de la cadena de suministro.Streamr, por otro lado, ha creado una red de transmisión de datos basada en suscripción sin permisos adecuada para escenarios de análisis de IoT y en tiempo real, que muestra un potencial sobresaliente en proyectos de transporte y logística (como trabajar con proyectos finlandeses de ciudades inteligentes).
Con la frecuencia creciente del intercambio de datos y la utilización, la autenticidad, la credibilidad y la privacidad de los datos se han convertido en problemas clave que no pueden ignorarse.Esto ha llevado al ecosistema Web3 a extender la innovación a las áreas de verificación de datos y protección de la privacidad, dando a luz una serie de soluciones innovadoras.
3.1 Innovación en verificación de datos y protección de la privacidad
Muchas tecnología Web3 y proyectos nativos están trabajando para resolver la autenticidad de los datos y los problemas de protección de datos privados.Además de ZK, MPC y otras tecnologías se han utilizado ampliamente, entre los cuales el notario del Protocolo de seguridad de la capa de transporte (notario de TLS) es particularmente digno de atención como método de verificación emergente.
Introducción al notario de TLS
El Protocolo de seguridad de la capa de transporte (TLS) es un protocolo de cifrado ampliamente utilizado en las comunicaciones de red, con el objetivo de garantizar la seguridad, integridad y confidencialidad de la transmisión de datos entre clientes y servidores.Es un estándar de cifrado común en la comunicación de red moderna y se utiliza en HTTPS, correo electrónico, mensajes instantáneos y otros escenarios.
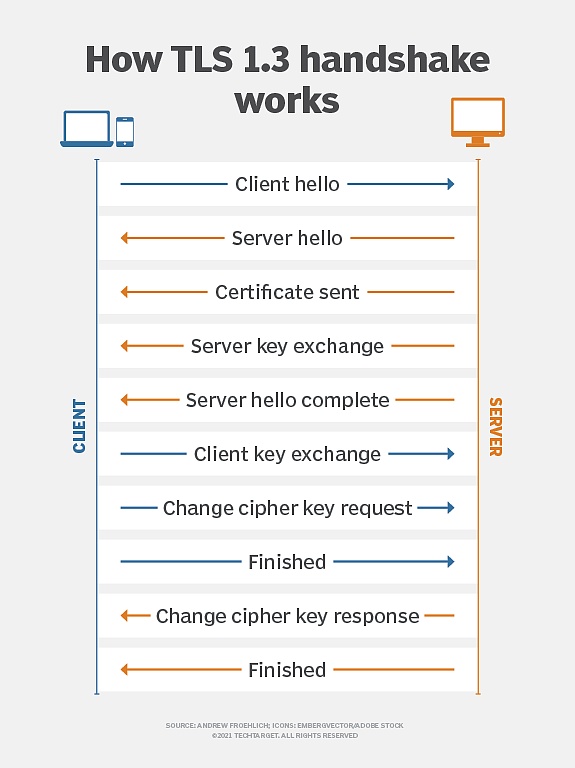
(Principio de cifrado TLS, Fuente: TechTarget)
Cuando nació hace diez años, el objetivo inicial del notario de TLS era verificar la autenticidad de las sesiones de TLS mediante la introducción de «notarios» de terceros fuera del cliente (Prover) y el servidor.
Utilizando la tecnología de segmentación clave, la clave maestra de la sesión TLS se divide en dos partes, en poder del cliente y el notario.Este diseño permite a los notarios participar en el proceso de verificación como terceros de confianza, pero no puede acceder al contenido de comunicación real.Este mecanismo de notarización está diseñado para detectar ataques de hombre en los medios, prevenir certificados fraudulentos, garantizar que los datos de comunicación no se manifesten durante la transmisión y permitan a terceros confiables confirmar la legitimidad de las comunicaciones mientras protegen la privacidad de la comunicación.
Por lo tanto, el notario de TLS proporciona una verificación segura de datos y equilibra efectivamente los requisitos de verificación y la protección de la privacidad.
En 2022, el proyecto de notario TLS es reconstruido por el laboratorio de investigación de privacidad y exploración de extensión (PSE) de la Fundación Ethereum.La nueva versión del Protocolo de Notario TLS se reescribe desde cero en el lenguaje de Rust, incorpora protocolos de cifrado más avanzados (como MPC). No se filtró contenido de datos.Mientras se mantiene la función de verificación del notador nocturno TLS original, mejora enormemente las capacidades de protección de la privacidad, lo que lo hace más adecuado para las necesidades de privacidad de datos actuales y futuras.
3.2 Variaciones y extensiones del notario de TLS
En los últimos años, la tecnología notarial de TLS también ha evolucionado continuamente y se ha desarrollado sobre la base del desarrollo y producido múltiples variantes, mejorando aún más las funciones de privacidad y verificación:
-
zktls: Una versión mejorada por la privacidad del notario de TLS, combinado con la tecnología ZKP, permite a los usuarios generar pruebas cifradas de datos de la página web sin exponer ninguna información confidencial.Es adecuado para escenarios de comunicación que requieren protección de la privacidad extremadamente alta.
-
3P-TLS (TLS de tres partes): Se introducen el cliente, el servidor y el auditor para permitir a los auditores verificar la seguridad de la comunicación sin filtrar el contenido de comunicación.Este protocolo es muy útil en escenarios en los que se requiere transparencia, pero se requiere protección de la privacidad, como revisiones de cumplimiento o auditorías de transacciones financieras.
Los proyectos de Web3 utilizan estas tecnologías de cifrado para mejorar la verificación de datos y la protección de la privacidad, romper el monopolio de datos, resolver silos de datos y problemas de transmisión confiables y permitir a los usuarios probar su privacidad sin revelar sus registros comerciales para cuentas de redes sociales y préstamos financieros. , antecedentes profesionales e información de certificación académica, como:
-
El protocolo Reclaim utiliza la tecnología ZKTLS para generar pruebas de conocimiento de conocimiento cero del tráfico HTTPS, lo que permite a los usuarios importar de forma segura los datos de actividades, reputación e identidad de sitios web externos sin exponer información confidencial.
-
ZkPass combina la tecnología 3P-TLS para permitir a los usuarios verificar los datos privados del mundo real sin fugas.
-
Opacity Network se basa en ZKTLS, lo que permite a los usuarios probar de manera segura su actividad en varias plataformas (como Uber, Spotify, Netflix, etc.) sin acceder directamente a las API de esas plataformas.Implementar prueba de actividad multiplataforma.
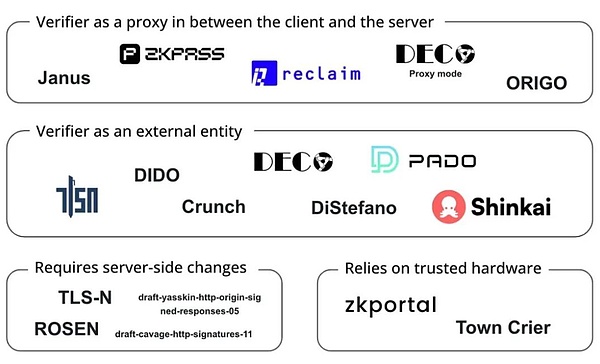
(Proyectos que funcionan oN TLS Oráculos, Fuente: Bastian Wetzel)
Como un enlace importante en la cadena del ecosistema de datos, la verificación de datos de Web3 tiene amplias perspectivas de aplicaciones.Sin embargo, el desarrollo de la tecnología de verificación de autenticidad es solo el comienzo de la construcción de una nueva generación de infraestructura de datos.
4. Red de datos descentralizada
Algunos proyectos combinan la tecnología de verificación de datos mencionada anteriormente para realizar exploraciones más profundas en la corriente aguas arriba del ecosistema de datos, a saber, la trazabilidad de los datos, la recopilación de datos distribuidos y la transmisión confiable.Aquí hay varios proyectos representativos: OpenLayer, Grass y Vana, que muestran un potencial único en la construcción de una infraestructura de datos de próxima generación.
4.1 OpenLayer
OpenLayer es uno de los proyectos de aceleradores de emprendimiento criptográfico A16Z Crypto 2024, que sirve como la primera capa de datos real modular, comprometida a proporcionar una solución modular innovadora para coordinar la recopilación de datos, la verificación y la transformación para satisfacer las empresas Web2 y Web3 que necesitan.OpenLayer ha atraído el apoyo de fondos conocidos e inversores ángeles, incluidas Geometry Ventures, Longhash Ventures.
Existen múltiples desafíos en la capa de datos tradicional: la falta de mecanismo de verificación confiable, la dependencia de la arquitectura centralizada conduce a la limitación del acceso, los datos entre los diferentes sistemas carecen de interoperabilidad y liquidez, y tampoco hay un mecanismo de asignación de valor de datos justo.
Un problema más concreto es que los datos de entrenamiento de IA se están volviendo cada vez más escasos hoy.En Internet público, muchos sitios web han comenzado a utilizar restricciones anti-más seguidores para evitar que las compañías de IA se arrastren a escala.
Y enDatos privados y patentadosPor un lado, la situación es más complicada.Bajo este status quo, los usuarios no pueden obtener de forma segura beneficios directos al proporcionar datos privados y, por lo tanto, no están dispuestos a compartir estos datos confidenciales.
Para resolver estos problemas, OpenLayer ha creado una capa de datos auténtica modular con tecnología de verificación de datos y coordinó el proceso de recopilación, verificación y conversión de datos en un descentralizado + incentivos económicos, para las empresas Web2 y Web3. infraestructura.
4.1.1 Los componentes centrales del diseño modular de OpenLayer
OpenLayer proporciona una plataforma modular para simplificar el proceso de recopilación de datos, verificación de confianza y conversión:
a) OpenNodes
OpenNodes es el componente central responsable de la recopilación de datos descentralizados en el ecosistema de OpenLayer.
OpenNodes admite tres tipos de datos principales para satisfacer las necesidades de diferentes tipos de tareas:
-
Datos de Internet disponibles públicamente (como datos financieros, datos meteorológicos, datos deportivos y flujos de redes sociales)
-
Datos privados del usuario (como el historial de visualización de Netflix, el historial de pedidos de Amazon, etc.)
-
Datos autoinformados de fuentes seguras (como datos firmados por un propietario patentado o verificados por un hardware de confianza específico).
Los desarrolladores pueden agregar fácilmente nuevos tipos de datos, especificar nuevas fuentes de datos, requisitos y métodos de recuperación de datos, y los usuarios pueden optar por proporcionar datos no identificados a cambio de recompensas.Este diseño permite que el sistema se expanda continuamente a las nuevas necesidades de datos.
b) Validadores abiertos
OpenValidators es responsable de la verificación de datos después de la recopilación, lo que permite a los consumidores de datos confirmar que los datos proporcionados por el usuario coinciden exactamente con la fuente de datos.Todos los métodos de verificación proporcionados pueden verificarse mediante cifrado, y los resultados de verificación se pueden verificar después.Para el mismo tipo de prueba, hay múltiples proveedores diferentes para proporcionar servicios.Los desarrolladores pueden elegir el proveedor de verificación más adecuado de acuerdo con sus necesidades.
En los casos de uso iniciales, especialmente para datos públicos o privados de la API de Internet, OpenLayer utiliza TLSNOtary como una solución de verificación para exportar datos de cualquier aplicación web y probar la autenticidad de los datos sin comprometer la privacidad.
No se limita a TLSNOtary, gracias a su diseño modular, el sistema de verificación puede acceder fácilmente a otros métodos de verificación para adaptarse a diferentes tipos de datos y necesidades de verificación, incluidas, entre otros::
-
Conexiones TLS atestiguadas: use un entorno de ejecución de confianza (TEE) para establecer una conexión TLS certificada para garantizar la integridad y la autenticidad de los datos durante la transmisión.
-
Enclaves seguros: use entornos de aislamiento seguro a nivel de hardware (como Intel SGX) para procesar y verificar datos confidenciales para proporcionar un mayor nivel de protección de datos.
-
Generadores de prueba de ZK: ZKP integrado, que permite la verificación de las propiedades de los datos o los resultados del cálculo sin revelar datos originales.
c) OpenConnect
OpenConnect es el módulo central en el ecosistema de OpenLayer responsable de la conversión de datos y la realización de la disponibilidad, el procesamiento de datos de varias fuentes, asegurando la interoperabilidad de los datos entre diferentes sistemas y satisfacer las necesidades de diferentes aplicaciones.Por ejemplo:
-
Convierta los datos en un formato Oracle en la cadena, que es conveniente para el uso directo de contratos inteligentes.
-
Convierta los datos sin procesar no estructurados en datos estructurados y realice un preprocesamiento previo para el entrenamiento de IA y otros fines.
Para los datos de las cuentas privadas de los usuarios, OpenConnect proporciona desensibilización de datos para proteger la privacidad, y también proporciona componentes para mejorar la seguridad durante el intercambio de datos y reducir las violaciones y el abuso de datos.Para satisfacer las necesidades de los datos en tiempo real para aplicaciones como AI y Blockchain, OpenConnect admite una conversión eficiente de datos en tiempo real.
En la actualidad, a través de la integración con Eigenlayer, el operador de OpenLayer AVS monitorea las tareas de solicitud de datos, es responsable de rastrear datos y verificarlos, y luego informa los resultados al sistema para prometer o volver a acumular activos a través de Eigenlayer para proporcionar garantías financieras para su comportamiento. .Si se confirma el comportamiento malicioso, enfrentará el riesgo de ser multado y confiscado de los activos comprometidos.Como uno de los primeros AVS (servicios de verificación activos) en la red principal de Eigenlayer, OpenLayer ha atraído a más de 50 operadores y $ 4 mil millones en activos de reacción.
En general, la capa de datos descentralizada construida por OpenLayer expande el alcance y la diversidad de los datos disponibles sin sacrificar la practicidad y la eficiencia, al tiempo que garantiza la autenticidad de los datos a través de la tecnología de cifrado y los incentivos económicos.Su tecnología tiene una amplia gama de casos de uso prácticos para los DAPP Web3 que buscan obtener información fuera de la cadena, modelos de IA que requieren información real para entrenar e inferir, y compañías que desean segmentar y localizar a los usuarios en función de sus identidades y reputaciones existentes.Los usuarios también pueden valorar sus datos privados.
4.2 hierba
Grass es un proyecto emblemático desarrollado por Wynd Network para crear un rastreador web descentralizado y una plataforma de datos de capacitación de IA.A finales de 2023, el Proyecto Grass completó una ronda de semillas de $ 3.5 millones dirigida por Polychain Capital y Tribe Capital.Inmediatamente después, en septiembre de 2024, el proyecto marcó el comienzo de un financiamiento de la Serie A dirigido por Hackvc, con instituciones de inversión conocidas como Polychain, Delphi, Lattice y Brevan Howard también participaron.
Mencionamos que la capacitación de IA requiere una nueva exposición de datos, y una de las soluciones es usar múltiples IP para romper los permisos de acceso a datos y alimentar los datos de IA.Grass comenzó desde esto para crear una red de nodo de rastreador distribuida, dedicada a usar el ancho de banda inactivo de los usuarios para recopilar y proporcionar conjuntos de datos verificables para el entrenamiento de IA en forma de infraestructura física descentralizada.El nodo ruta las solicitudes web a través de la conexión a Internet del usuario, accede a sitios web públicos y compila conjuntos de datos estructurados.Utiliza la tecnología de computación Edge para realizar la limpieza y el formato de datos preliminares para mejorar la calidad de los datos.
Grass adopta la arquitectura de acumulación de datos de la capa 2 de Solana, basada en Solana para mejorar la eficiencia del procesamiento.Grass utiliza un validador para recibir, verificar y lotes de transacciones web de nodos, generando pruebas de ZK para garantizar la autenticidad de los datos.Los datos verificados se almacenan en el libro mayor de datos (L2) y se vinculan a la prueba de la cadena L1 correspondiente.
4.2.1 Componentes principales de hierba
a) nodo de hierba
Similar a OpenNodes, los usuarios de C-END instalan aplicaciones de Grass o extensiones de navegador y ejecutarlas, use el ancho de banda inactivo para realizar operaciones de rastreo de red, los nodos enrutan las solicitudes web a través de la conexión a Internet del usuario, acceden a sitios web públicos y compilan conjuntos de datos estructurados y usan la computación Edge Computing tecnología para realizar.Los usuarios reciben recompensas de token de hierba en función del ancho de banda y la cantidad de datos aportados.
b) enrutadores
Conecte los nodos y validadores de hierba, administre redes de nodos y el ancho de banda de retransmisión.Los enrutadores están incentivados para operar y recibir recompensas, con la proporción de proporción de proporción de recompensa proporciones de proporción de proporción al ancho de banda de verificación total que lo pasó.
c) Validadores
Reciba, verifica y verifica las transacciones web del enrutador, genere pruebas de ZK, use un conjunto de clave único para establecer una conexión TLS y seleccione el conjunto de cifrado apropiado para la comunicación con el servidor web de destino.Grass actualmente utiliza un validador centralizado y planea mudarse al Comité de Validador en el futuro.
d) procesador ZK (procesador ZK)
Reciba una prueba de generar cada datos de la sesión de nodo desde el verificador, prueba de validez de lotes de todas las solicitudes web y envíe a la capa 1 (Solana).
e) Libro de datos de hierba (hierba L2)
Almacene el conjunto de datos completo y vinculáramos a la cadena L1 correspondiente (Solana).
f) modelo de incrustación de borde
Responsable de convertir datos web no estructurados en modelos estructurados que puedan ser capacitados con IA.
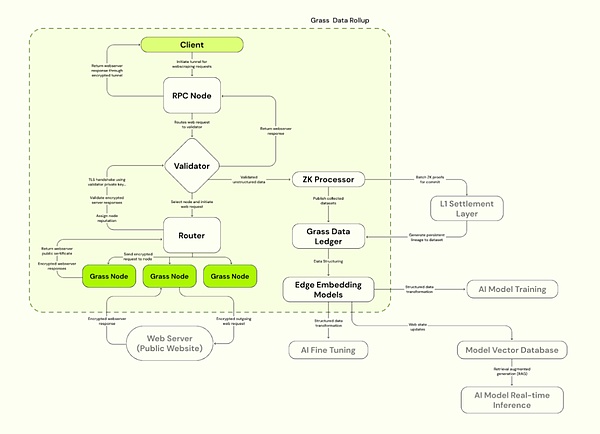
Fuente: hierba
Análisis y comparación de Grass y OpenLayer
Las redes distribuidas de apalancamiento de OpenLayer y Grass para proporcionar a las empresas la oportunidad de acceder a datos de Internet abiertos e información cerrada que requiere autenticación.El mecanismo de incentivos promueve el intercambio de datos y la producción de datos de alta calidad.Ambos están comprometidos a crear una capa de datos descentralizada para resolver el problema del acceso y la verificación de la adquisición de datos, pero adoptan rutas técnicas y modelos de negocios ligeramente diferentes.
Diferentes arquitecturas técnicas
Grass utiliza la arquitectura de acumulación de datos de la capa 2 en Solana, y actualmente utiliza un mecanismo de verificación centralizado y un único validador.Como el primer lote de AVS, OpenLayer se basa en Eigenlayer y utiliza incentivos económicos y mecanismos de confiscación para lograrMecanismo de verificación descentralizado.También adopta un diseño modular, enfatizando la escalabilidad y la flexibilidad de los servicios de verificación de datos.
Diferencias de productos
Ambos ofrecen similares a los productos C, lo que permite a los usuarios monetizar el valor de los datos a través de nodos.En los casos de uso de B, Grass proporciona un modelo de mercado de datos interesante y utiliza L2 para almacenar verbalmente los datos completos para proporcionar a las empresas de inteligencia artificial un conjunto de capacitación verificable estructurado, de alta calidad y verificable.OpenLayer no tiene un componente de almacenamiento de datos dedicado temporal, pero proporciona una gama más amplia de servicios de verificación de flujo de datos en tiempo real (VAA). Para el precio del proyecto RWA/Defi/Prediction Market Project, proporcione datos sociales en tiempo real y más.
Por lo tanto, la base de clientes objetivo de Grass está dirigida principalmente a compañías de IA y científicos de datos, proporcionando conjuntos de datos de capacitación a gran escala y estructurado, y también atiende a instituciones de investigación y empresas que requieren una gran cantidad de conjuntos de datos de red; necesidades de datos fuera de la cadena.
Competencia potencial en el futuro
Sin embargo, teniendo en cuenta las tendencias de la industria, es probable que las funciones de los dos proyectos converjan en el futuro.Grass también puede proporcionar datos estructurados en tiempo real pronto.Como plataforma modular, OpenLayer también puede expandirse a la gestión del conjunto de datos en el futuro para tener su propio libro de datos, por lo que las áreas competitivas de los dos pueden superponerse gradualmente.
Además, ambos proyectos pueden considerar agregar el etiquetado de datos como un enlace clave.La hierba puede moverse más rápido a este respecto, ya que tienen una gran red de nodos, según los informes, más de 2.2 millones de nodos activos.Esta ventaja le da a Grass el potencial de proporcionar servicios de aprendizaje de refuerzo (RLHF) basados en la retroalimentación humana, utilizando una gran cantidad de datos etiquetados para optimizar los modelos de IA.
Sin embargo, OpenLayer, con su experiencia en verificación de datos y procesamiento en tiempo real, puede mantener sus ventajas en la calidad y credibilidad de los datos.Además, como AVS de Eigenlayer, OpenLayer puede tener un mayor desarrollo en el mecanismo de verificación descentralizado.
Si bien los dos proyectos pueden competir en ciertas áreas, sus respectivas fortalezas y rutas técnicas únicas también pueden llevar a su ocupación de diferentes nichos en el ecosistema de datos.
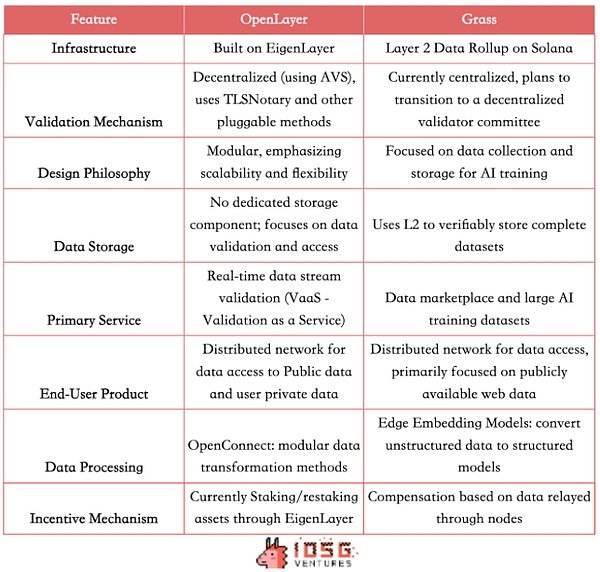
(Fuente: iOSG, David)
4.3 Vava
Como una red de grupo de datos centrada en el usuario, VANA también se compromete a proporcionar datos de alta calidad para IA y aplicaciones relacionadas.En comparación con OpenLayer y Grass, Vana adopta más rutas tecnológicas y modelos de negocios diferentes.Vana completó un financiamiento de $ 5 millones en septiembre de 2024, dirigido por Coinbase Ventures.
Originalmente lanzado en 2018 como un proyecto de investigación para MIT, Vana tiene como objetivo convertirse en una cadena de bloques de capa 1 diseñada específicamente para datos privados del usuario.Sus innovaciones en la propiedad de datos y la asignación de valor permiten a los usuarios beneficiarse de los modelos de IA capacitados en sus datos.El núcleo de Vana es a través de confianza, privado y atribuibleGrupo de liquidez de datose innovadorPrueba de contribuciónMecanismos para realizar la circulación y el valor de los datos privados:
4.3.1.
VANA presenta un concepto único del grupo de liquidez de datos (DLP): como el componente central de la red VANA, cada DLP es una red independiente de igual para agregar tipos específicos de activos de datos.Los usuarios pueden cargar sus datos privados (como el historial de compras, los hábitos de navegación, las actividades de las redes sociales, etc.) a un DLP específico y elegir de manera flexible si autorizar estos datos a terceros específicos para su uso.Los datos se integran y se gestionan a través de estos grupos de liquidez, que se desidentifican para garantizar la privacidad del usuario al tiempo que permite que los datos participen en aplicaciones comerciales, como para capacitación en modelo de IA o investigación de mercado.
Los usuarios envían datos a DLP y reciben tokens DLP correspondientes (cada DLP tiene una recompensa específica). .Los usuarios no solo pueden compartir datos, sino que también pueden obtener beneficios continuos de las llamadas posteriores a los datos (y proporcionar seguimiento visual).A diferencia de las ventas tradicionales de datos de un solo tiempo, VANA permite que los datos continúen participando en el ciclo económico.
4.3.2.
Una de las otras innovaciones centrales de Vana esPrueba de contribución(Prueba de contribución) Mecanismo.Este es el mecanismo clave de Vana para garantizar la calidad de los datos, lo que permite a cada DLP personalizar las funciones únicas de la prueba de contribución en función de sus características para verificar la autenticidad y la integridad de los datos y evaluar la contribución de los datos a la mejora del rendimiento del modelo de IA.Este mecanismo garantiza que las contribuciones de datos de los usuarios se cuantifiquen y registren, proporcionando así recompensas a los usuarios.Similar a la «prueba de trabajo» en las criptomonedas, la prueba de contribución distribuye beneficios a los usuarios en función de la calidad, la cantidad de datos aportados por los usuarios y la frecuencia de uso.La ejecución automática de contratos inteligentes asegura que los contribuyentes reciban recompensas que coincidan con sus contribuciones.
Arquitectura técnica de Vana
-
Capa de liquidez de datos
Esta es la capa central de Vana, responsable de la contribución, verificación y grabación de datos a DLP, e introduce datos en la cadena como un activo digital transferible.Los creadores de DLP implementan contratos inteligentes DLP para establecer el propósito de la contribución de los datos, los métodos de verificación y los parámetros de contribución.Los contribuyentes de datos y los custodios presentan datos para la verificación, y el módulo de prueba de contribución (POC) realiza la verificación de datos y la evaluación del valor, y otorga derechos de gobierno y recompensas en función de los parámetros.
-
Capa de portabilidad de datos
Esta es una plataforma de datos abiertos para contribuyentes y desarrolladores de datos, y también es la capa de aplicación de VANA.La capa de portabilidad de datos proporciona un espacio de colaboración para que los contribuyentes y los desarrolladores de datos creen aplicaciones utilizando la liquidez de datos acumulada en DLP.Proporciona infraestructura para la capacitación distribuida de modelos propiedad de usuarios y desarrollo de AI DAPP.
-
Connectoma universal
Un libro mayor descentralizado también es un diagrama de flujo de datos en tiempo real que se ejecuta a través de todo el ecosistema VANA.Asegure una transferencia efectiva de tokens DLP y proporcione acceso a datos de DLP a aplicaciones.Compatible con EVM, permitiendo la interoperabilidad con otras redes, protocolos y aplicaciones Defi.
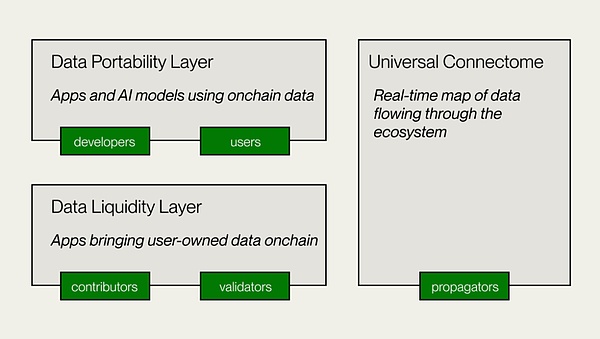
(Fuente: Vana)
VANA proporciona una ruta relativamente diferente, centrándose en el empoderamiento de liquidez y valor de los datos del usuario. La interoperabilidad y la licencia proporcionan una nueva solución.En última instancia, cree un ecosistema de Internet abierto que permita a los usuarios poseer y administrar sus propios datos, así como productos inteligentes creados a partir de estos datos..
5. La propuesta de valor de las redes de datos descentralizadas
El científico de datos Clive Humby dijo en 2006 que los datos son petróleo en la nueva era.En los últimos 20 años, hemos sido testigos del rápido desarrollo de la tecnología de «refinación».La tecnología como el análisis de big data y el aprendizaje automático han permitido un valor de datos sin precedentes.Según el pronóstico de IDC, para 2025, el círculo de datos global crecerá a 163 ZB, la mayoría de los cuales vendrán de usuarios individuales. deberá comercializarse en el futuro.
Puntos débiles de las soluciones tradicionales: desbloquear innovación en Web3
A través de una red de nodos distribuida, la solución de datos Web3 rompe las limitaciones de las instalaciones tradicionales, logra una adquisición de datos más amplia y eficiente, y mejora la eficiencia de adquisición en tiempo real y la credibilidad de verificación de datos específicos.En este proceso, la tecnología Web3 garantiza la autenticidad e integridad de los datos y puede proteger efectivamente la privacidad del usuario, logrando así un modelo de utilización de datos más justo.Esta arquitectura de datos descentralizada promueve la adquisición de datosDemocratización.
Ya sea que se trate del modo de nodo de usuario de OpenLayer y Grass, o la monetización de Vana de los datos privados del usuario, además de mejorar la eficiencia de la recopilación de datos específicos, los usuarios comunes pueden compartir los dividendos de la economía de datos, creando un modelo de ganar-ganar para los usuarios y desarrolladores, de modo que los usuarios realmente controlan y se benefician de sus datos y recursos relacionados.
A través de la economía token, la solución de datos Web3 ha rediseñado el modelo de incentivos y ha creado un mecanismo de asignación de valor de datos más justo.Ha atraído a una gran cantidad de usuarios, recursos de hardware y capital para coordinar y optimizar el funcionamiento de toda la red de datos.
Ellos también tienenModularidad y escalabilidad: Por ejemplo, el diseño modular de OpenLayer proporciona flexibilidad para futuras iteraciones tecnológicas y expansión ecológica.Gracias a las características técnicas, optimizamos el método de adquisición de datos de la capacitación del modelo de IA para proporcionar conjuntos de datos más ricos y diversos.
Desde la generación de datos, el almacenamiento, la verificación hasta el intercambio y el análisis, las soluciones impulsadas por Web3 resuelven muchas desventajas de las instalaciones tradicionales a través de ventajas tecnológicas únicas, y también brindan a los usuarios la capacidad de monetizar datos personales, lo que desencadena un cambio fundamental en el modelo económico de datos.Con el mayor desarrollo y evolución de la tecnología y la expansión de los escenarios de aplicación, se espera que la capa de datos descentralizada se convierta en la próxima generación de infraestructura crítica, junto con otras soluciones de datos de Web3, proporcionando apoyo para una amplia gama de industrias basadas en datos.







