
INTRODUCTION: le développement de l’AI + Web3
Au cours des dernières années, le développement rapide de l’intelligence artificielle (AI) et des technologies Web3 a attiré une large attention dans le monde entier.En tant que technologie qui simule et imite l’intelligence humaine, l’IA a fait des percées majeures dans les domaines de la reconnaissance faciale, du traitement du langage naturel, de l’apprentissage automatique, etc.Le développement rapide de la technologie de l’IA a apporté d’énormes changements et innovations à tous les domaines de la vie.
La taille du marché de l’industrie de l’IA a atteint 200 milliards de dollars américains en 2023. Les géants de l’industrie et les joueurs exceptionnels tels que Openai, le personnage.ai, Midjourney sont apparus comme des champignons après une pluie, menant l’engouement de l’IA.
Dans le même temps, Web3, en tant que modèle de réseau émergent, modifie progressivement notre compréhension et notre utilisation d’Internet.Sur la base de la technologie de blockchain décentralisée, Web3 réalise le partage de données et la contrôlabilité, l’autonomie des utilisateurs et les mécanismes de confiance grâce à des fonctions telles que des contrats intelligents, un stockage distribué et une authentification décentralisée.Le concept principal de Web3 est de libérer les données des organisations autoritaires centralisées et de donner aux utilisateurs le droit de contrôler les données et de partager la valeur des données.
Actuellement, la valeur marchande de l’industrie Web3 a atteint 25 billions de billets. Rejoignez l’industrie Web3.
Il est facile de constater que la combinaison de l’IA et du WEB3 est un domaine dont les constructeurs et les VC à l’est et l’Ouest sont très préoccupés.
Cet article se concentrera sur l’état de développement actuel de l’AI + Web3 et explorera la valeur potentielle et l’impact de cette intégration.Nous présenterons d’abord les concepts et les fonctionnalités de base de l’IA et du Web3, puis explorerons leur relation.Nous analyserons ensuite l’état actuel des projets AI + WEB3 et discuterons en profondeur des limites et des défis auxquels ils sont confrontés.Grâce à de telles recherches, nous prévoyons de fournir des références et des informations précieuses aux investisseurs et aux praticiens dans les industries connexes.
Comment l’IA interagit avec web3
Le développement de l’IA et du Web3 est comme les deux côtés de l’équilibre.Alors, quel genre d’étincelles AI et Web3 peuvent-elles entrer en collision?Ensuite, nous analyserons les difficultés et l’espace d’amélioration auxquelles sont confrontés les industries de l’IA et du Web3, puis discuterons de la façon dont les autres peuvent aider à résoudre ces difficultés.
-
Dilemme et espace d’amélioration potentielle pour l’industrie de l’IA
-
Dilemme et espace d’amélioration potentiel pour l’industrie web3
-
Tout d’abord, la puissance de calcul: L’alimentation informatique fait référence à la capacité d’effectuer des calculs et un traitement à grande échelle.Les tâches d’IA nécessitent souvent de traiter de grandes quantités de données et d’effectuer des calculs complexes, tels que la formation de modèles de réseaux de neurones profonds.La puissance de calcul à haute intensité peut accélérer les processus de formation et d’inférence des modèles et améliorer les performances et l’efficacité des systèmes d’IA.Ces dernières années, avec le développement de technologies matérielles, telles que les processeurs graphiques (GPU) et les puces d’IA dédiées (telles que les TPU), l’amélioration de la puissance informatique a joué un rôle important dans la promotion du développement de l’industrie de l’IA.Nvidia, qui a grimpé en flèche des actions ces dernières années, a occupé une grande part de marché en tant que fournisseur de GPU et a réalisé des bénéfices élevés.
-
Qu’est-ce qu’un algorithme: Les algorithmes sont les composants principaux des systèmes d’IA, et ce sont des méthodes mathématiques et statistiques utilisées pour résoudre les problèmes et mettre en œuvre des tâches.Les algorithmes d’IA peuvent être divisés en algorithmes traditionnels d’apprentissage automatique et aux algorithmes d’apprentissage en profondeur, parmi lesquels les algorithmes d’apprentissage en profondeur ont fait des percées majeures ces dernières années.La sélection et la conception des algorithmes sont cruciales pour les performances et l’efficacité des systèmes d’IA.Les algorithmes améliorés en permanence et innovants peuvent améliorer la précision, la robustesse et les capacités de généralisation des systèmes d’IA.Différents algorithmes auront des effets différents, donc l’amélioration de l’algorithme est également cruciale pour l’effet de l’efficacité des tâches.
-
Pourquoi les données sont importantes: La tâche principale des systèmes d’IA est d’extraire des modèles et des règles dans les données par l’apprentissage et la formation.
Les données sont la base de la formation et de l’optimisation des modèles.Des ensembles de données riches peuvent fournir des informations plus complètes et diverses, permettant aux modèles d’être mieux généralisés à des données invisibles, aidant les systèmes d’IA à mieux comprendre et résoudre des problèmes réels.
-
Soumis par: l’utilisateur est le consommateur de la tâche, fournissant les tâches à calculer et payant les tâches de formation de l’IA
-
Exécuteur: L’exécuteur exécute la tâche formée par le modèle et génère une preuve de réalisation de la tâche de vérification par le vérificateur.
-
Vérificateur: liant le processus de formation non déterministe au calcul linéaire déterministe, en comparant la preuve de l’exécuteur testamentaire au seuil attendu.
-
Whistleblower: Vérifiez le travail du validateur et soulevez des questions pour gagner des bénéfices lorsqu’elle est découverte.
-
Formation de l’IA: Si nous comparons l’intelligence artificielle à un étudiant, la formation est similaire à la fourniture de l’intelligence artificielle avec beaucoup de connaissances, et les exemples peuvent également être compris comme des données que nous l’appelons souvent, et l’intelligence artificielle apprend de ces exemples de connaissances.Étant donné que la nature de l’apprentissage nécessite la compréhension et la mémoire d’une grande quantité d’informations, ce processus nécessite beaucoup de puissance et de temps de calcul.
-
Raisonnement IA: Alors, qu’est-ce que le raisonnement?Il peut être compris comme en utilisant les connaissances apprises pour résoudre des problèmes ou passer des examens. .
-
Une catégorie est le fournisseur de données AI. .
-
Une autre catégorie est les validateurs de données, où les utilisateurs peuvent se connecter au Publicai Data Center et sélectionner les données les plus précieuses pour la formation d’IA pour voter.
-
Tout d’abord, qu’il s’agisse d’utiliser l’IA pour l’analyse et la prédiction des données, en utilisant l’IA dans les scénarios de recommandation et de recherche, ou de réaliser des audits de code, il n’y a pas beaucoup de différence par rapport à la combinaison des projets Web2 et de l’IA.Ces projets utilisent simplement l’IA pour améliorer l’efficacité et analyser, sans démontrer la convergence native et les solutions innovantes entre l’IA et les crypto-monnaies.
-
Deuxièmement, de nombreuses équipes Web3 se combinent davantage avec l’IA pour utiliser purement le concept de l’IA au niveau du marketing.Ils ont juste utilisé la technologie de l’IA dans des zones très limitées, puis ont commencé à promouvoir la tendance de l’IA, créant une illusion que les projets sont très proches de l’IA.Cependant, il y a encore beaucoup de lacunes dans ces projets en termes d’innovation réelle.
2.1 Dilemme face à l’industrie de l’IA
Si vous souhaitez explorer les difficultés rencontrées par l’industrie de l’IA, examinons d’abord l’essence de l’industrie de l’IA.Le cœur de l’industrie de l’IA est inséparable à partir de trois éléments: puissance de calcul, algorithmes et données.
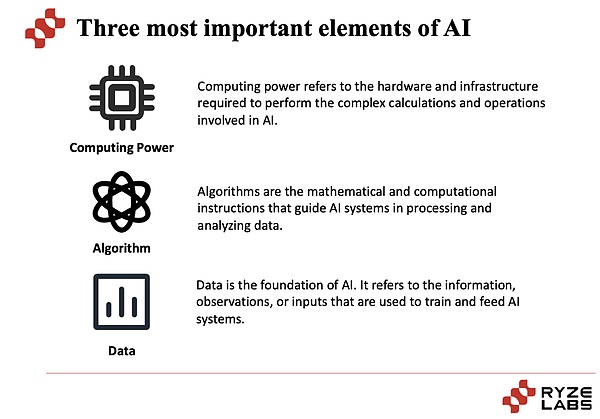
Après avoir compris les trois éléments fondamentaux de l’IA, jetons un coup d’œil aux difficultés et aux défis que l’IA rencontre dans ces trois aspects. Raisonnement, en particulier pour en termes de modèles d’apprentissage en profondeur.Cependant, l’acquisition et la gestion de la puissance de calcul à grande échelle sont un défi coûteux et complexe.Le coût, la consommation d’énergie et la maintenance des équipements informatiques hautes performances sont tous des problèmes.Surtout pour les startups et les développeurs individuels, il peut être difficile d’obtenir une puissance de calcul suffisante.
En termes d’algorithmes, bien que les algorithmes d’apprentissage en profondeur aient connu un grand succès dans de nombreux domaines, il y a encore des dilemmes et des défis.Par exemple, la formation de réseaux de neurones profonds nécessite une grande quantité de données et de ressources informatiques, et pour certaines tâches, le modèle explicatif et interprétable peut être insuffisant.De plus, la capacité de robustesse et de généralisation de l’algorithme est également un problème important, et les performances du modèle sur les données invisibles peuvent être instables.Parmi les nombreux algorithmes, comment trouver le meilleur algorithme pour fournir les meilleurs services est un processus qui nécessite une exploration continue.
En termes de données, les données sont la force motrice de l’IA, mais l’obtention de données de haute qualité et diverses reste un défi.Les données dans certains domaines peuvent être difficiles à obtenir, telles que les données de santé sensibles dans le domaine médical.De plus, la qualité, la précision et l’étiquetage des données sont également des problèmes, et des données incomplètes ou biaisées peuvent entraîner un mauvais comportement ou un biais dans le modèle.Dans le même temps, la protection de la confidentialité et de la sécurité des données est également une considération importante.
De plus, il y a des problèmes tels que l’interprétabilité et la transparence, et les caractéristiques de la boîte noire du modèle d’IA sont une préoccupation publique.Pour certaines applications, telles que la finance, les soins de santé et la justice, le processus décisionnel du modèle doit être interprétable et traçable, tandis que les modèles d’apprentissage en profondeur existants manquent souvent de transparence.Expliquer le processus décisionnel du modèle et fournir des explications dignes de confiance reste un défi.
En outre, le modèle commercial de nombreuses entrepreneuriat du projet d’IA n’est pas très clair, ce qui rend également de nombreux entrepreneurs d’IA se sentent confus.
2.2 Dilemme face à l’industrie Web3
Dans l’industrie Web3, il existe actuellement de nombreuses difficultés à différents aspects qui doivent être résolues, que ce soit l’analyse des données de Web3, la mauvaise expérience utilisateur des produits web3 ou les problèmes des vulnérabilités de code de contrat intelligent et des attaques de pirates, beaucoup de place à l’amélioration.En tant qu’outil pour améliorer la productivité, l’IA a également beaucoup de place potentielle pour le développement dans ces aspects.
Tout d’abord, l’amélioration des capacités d’analyse et de prédiction des données: l’application de la technologie d’IA dans l’analyse et la prédiction des données a apporté un impact énorme à l’industrie Web3.Grâce à l’analyse intelligente et à l’exploitation minière des algorithmes d’IA, la plate-forme Web3 peut extraire des informations précieuses à partir de données massives et prendre des prédictions et des décisions plus précises.Cela est d’une grande importance pour l’évaluation des risques, les prévisions du marché et la gestion des actifs dans le domaine de la finance décentralisée (DEFI).
De plus, des améliorations de l’expérience utilisateur et des services personnalisés peuvent également être réalisés: l’application de la technologie AI permet à la plate-forme Web3 de fournir une meilleure expérience utilisateur et des services personnalisés.Grâce à l’analyse et à la modélisation des données utilisateur, la plate-forme Web3 peut fournir aux utilisateurs des recommandations personnalisées, des services personnalisés et une expérience interactive intelligente.Cela permet d’améliorer l’engagement et la satisfaction des utilisateurs et favorise le développement de l’écosystème Web3.
En termes de sécurité et de protection de la vie privée, l’application de l’IA a également un impact profond sur l’industrie Web3.La technologie de l’IA peut être utilisée pour détecter et se défendre contre les cyberattaques, identifier des comportements anormaux et assurer une sécurité plus forte.Dans le même temps, l’IA peut également être utilisée pour la protection de la confidentialité des données, et grâce à des technologies telles que le chiffrement des données et l’informatique de confidentialité, il peut protéger les informations personnelles des utilisateurs sur la plate-forme Web3.En termes d’audit de contrats intelligents, en raison de vulnérabilités possibles et de risques de sécurité dans l’écriture et l’audit des contrats intelligents, la technologie de l’IA peut être utilisée pour automatiser les audits des contrats et la détection de vulnérabilité pour améliorer la sécurité et la fiabilité des contrats.
On peut voir que l’IA peut participer et fournir une assistance à de nombreux aspects dans les difficultés et l’espace d’amélioration potentiel face à l’industrie Web3.
Analyse de l’état actuel des projets AI + Web3
Les projets combinant l’IA et le Web3 commencent principalement à partir de deux aspects majeurs, utilisent la technologie blockchain pour améliorer les performances des projets d’IA et utiliser la technologie d’IA pour servir l’amélioration des projets Web3.
Un grand nombre de projets ont émergé pour explorer ce chemin, y compris divers projets tels que IO.net, Gensyn, Ritual, etc. Ensuite, cet article utilisera l’IA pour aider Web3 et Web3 pour aider l’IA à différentes sous-compétitions. la situation et le développement actuels.
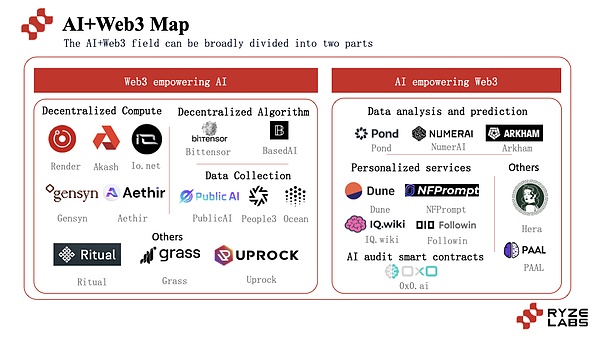
3.1 web3 aide AI
3.1.1 puissance de calcul décentralisée
Depuis que OpenAI a lancé Chatgpt à la fin de 2022, il a déclenché une vague d’IA.Après cela, Chatgpt a fait de grands efforts très rapidement, le nombre d’utilisateurs actifs mensuels atteignant 100 millions dans les deux mois.Avec l’avènement de Chatgpt, le champ d’IA a également rapidement explosé d’une piste de niche à une industrie très regardée.
Selon le rapport de Trendforce, Chatgpt nécessite 30 000 GPU NVIDIA A100 à fonctionner, et le GPT-5 nécessitera plus de calculs de magnitude à l’avenir.Cela a également ouvert une course aux armements entre diverses sociétés d’IA.
Avant la montée en puissance de l’IA, Nvidia, le plus grand fournisseur de GPU, avait ses clients axés sur trois services cloud principaux: AWS, Azure et GCP.Avec la montée en puissance de l’intelligence artificielle, un grand nombre de nouveaux acheteurs ont émergé, notamment les grandes entreprises de technologie Meta, Oracle et d’autres plateformes de données et les startups de l’IA, tous rejoignant la guerre pour thésier GPU pour former des modèles d’IA.Les grandes entreprises technologiques telles que Meta et Tesla ont augmenté les achats de modèles d’IA personnalisés et de recherche interne.Les sociétés de modèles de base comme les plateformes anthropiques et de données comme Snowflake et Databricks ont également acheté plus de GPU pour aider les clients à fournir des services d’IA.
Comme mentionné par semi-analyse l’année dernière, «GPU Rich et GPU Poor», quelques entreprises ont plus de 20 000 GPU A100 / H100, et les membres de l’équipe peuvent utiliser 100 à 1 000 GPU pour les projets.Ces sociétés sont soit des fournisseurs de cloud, soit des LLMS auto-construits, notamment Openai, Google, Meta, Anthropic, Inflexe, Tesla, Oracle, Mistral, etc.
Cependant, la plupart des entreprises sont pauvres du GPU et ne peuvent avoir du mal avec un nombre beaucoup plus petit de GPU, passant beaucoup de temps et d’énergie sur des choses qui sont plus difficiles à conduire le développement de l’écosystème.Et cette situation ne se limite pas aux startups.Certaines des sociétés d’IA les plus connues – le visage étreint, les databricks (MOSAICML), ensemble et même le flocon de neige ont moins de 20k en nombre d’A100 / H100.Ces entreprises ont des talents techniques de classe mondiale, mais sont limités par l’offre de GPU et sont désavantagés par rapport aux grandes entreprises de la concurrence en intelligence artificielle.
Cette pénurie ne se limite pas aux « GPU pauvres ». Fournitures GPU.
On peut voir qu’avec le développement rapide de l’IA, il y a un décalage grave entre la demande et les côtés de l’offre des GPU, et le problème de la pénurie d’approvisionnement est imminent.
Afin de résoudre ce problème, certaines parties du projet Web3 ont commencé à essayer de fournir des services de puissance informatique décentralisés basés sur les caractéristiques techniques de Web3, y compris Akash, Render, Gensyn, etc.Ce qui est courant à propos de ce type de projet, c’est que les jetons sont utilisés pour inciter les utilisateurs à fournir une alimentation informatique GPU inactive, devenant le côté de l’offre de la puissance de calcul pour fournir aux clients de l’IA une puissance de calcul.
Le portrait côté approvisionnement peut être principalement divisé en trois aspects: les fournisseurs de services cloud, les mineurs de crypto-monnaie et les entreprises.
Les fournisseurs de services cloud incluent de grands fournisseurs de services cloud (tels que AWS, Azure, GCP) et les fournisseurs de services cloud GPU (tels que Coreweave, Lambda, Crusoe, etc.), et les utilisateurs peuvent revendre la puissance de calcul des fournisseurs de services cloud inactifs pour gagner des revenus .Les mineurs cryptographiques au moment où Ethereum passe de POW à POS, la puissance de calcul du GPU inactif est également devenue un côté d’offre potentiel important.De plus, les grandes entreprises comme Tesla et Meta qui ont acheté un grand nombre de GPU en raison de leur disposition stratégique peuvent également utiliser la puissance de calcul du GPU inactif comme côté de l’alimentation.
Actuellement, les joueurs sur la piste sont à peu près divisés en deux catégories: l’une consiste à utiliser une puissance de calcul décentralisée pour le raisonnement d’IA, et l’autre consiste à utiliser une puissance de calcul décentralisée pour l’entraînement en IA.Le premier est tel que le rendu (bien qu’il se concentre sur le rendu, mais peut également être utilisé comme une puissance de calcul de l’IA), Akash, Aethir, etc.; , Gensyn, la plus grande différence entre les deux est le calcul.
Parlons d’abord de l’ancien projet de raisonnement sur l’IA. pouvoir.L’introduction et l’analyse de ces projets ont été mentionnées dans notre rapport de recherche sur DePin avant Ryze Labs.Bienvenue pour le vérifier.
Le point le plus central est que grâce au mécanisme d’incitation au jeton, le projet attire d’abord les fournisseurs et attire ensuite les utilisateurs à utiliser, réalisant ainsi le mécanisme de fonctionnement à froid et de base du projet, qui peut se développer et se développer davantage.Dans ce cycle, le côté de l’offre a des rendements de jetons de plus en plus précieux, et le côté de la demande a des services moins chers et plus rentables. Les prix attirent plus de participants et de spéculateurs pour participer et former une capture de valeur.
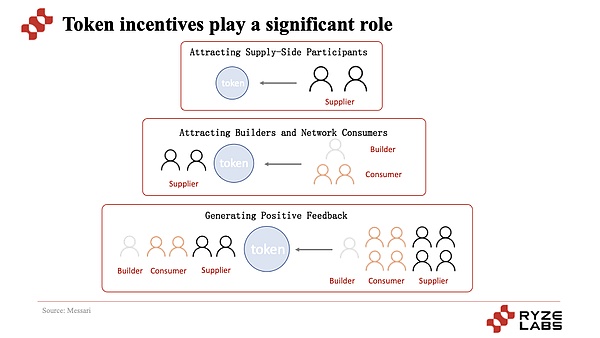
Un autre type est l’utilisation d’une puissance informatique décentralisée pour la formation en IA, comme Gensyn, IO.NET (la formation AI et le raisonnement IA peuvent à la fois le soutenir).En fait, il n’y a pas beaucoup de différence entre la logique d’opération de ce type de projet et le projet de raisonnement en IA.
Parmi eux, IO.NET est un réseau de puissance de calcul décentralisé, avec actuellement plus de 500 000 GPU, ce qui est exceptionnel dans les projets d’alimentation informatique décentralisés. Projet écologique.

De plus, Gensyn réalise une formation sur l’IA grâce à des contrats intelligents qui peuvent favoriser l’allocation des tâches et les récompenses pour l’apprentissage automatique.Comme le montre la figure ci-dessous, le travail de formation à l’apprentissage automatique de Gensyn coûte environ 0,4 $ l’heure, ce qui est beaucoup plus bas que le coût d’AWS et de GCP pour plus de 2 $.
Le système de Gensyn comprend quatre participants: Soumisseur, exécuteur testamentaire, vérificateur et dénonciateur.
On peut voir que Gensyn espère devenir un protocole informatique à échelle super-étendue et rentable pour les modèles mondiaux d’apprentissage en profondeur.Mais en regardant cette piste, pourquoi la plupart des projets choisissent-ils la puissance de calcul décentralisée pour le raisonnement en IA au lieu de la formation?
Ici, nous aidons également les amis qui ne comprennent pas la formation et le raisonnement de l’IA introduire les différences entre les deux:
On peut voir que les exigences de puissance de calcul des deux sont très différentes.
De plus, Ritual espère combiner des réseaux distribués avec des créateurs de modèles pour maintenir la décentralisation et la sécurité.Son premier produit, Internet, permet aux contrats intelligents sur la blockchain d’accéder aux modèles d’IA hors de la chaîne, permettant à ces contrats d’accéder à l’IA de manière à maintenir la vérification, la décentralisation et la confidentialité.
Le coordinateur d’Internet est responsable de la gestion du comportement des nœuds dans le réseau et de la réponse aux demandes informatiques émises par les consommateurs.Lorsqu’un utilisateur utilise Internet, l’inférence, la preuve et d’autres travaux seront placés hors de la chaîne, les résultats de sortie seront retournés au coordinateur et finalement transmis aux consommateurs de la chaîne via le contrat.
En plus des réseaux de puissance de calcul décentralisés, il existe également des réseaux de bande passante décentralisés tels que l’herbe pour améliorer la vitesse et l’efficacité de la transmission des données.En général, l’émergence de réseaux de puissance de calcul décentralisés a fourni une nouvelle possibilité pour le côté alimentation informatique de l’IA, poussant l’IA pour aller de l’avant dans une autre direction.
3.1.2 Modèle d’algorithme décentralisé
Comme mentionné dans le chapitre 2, les trois éléments principaux de l’IA sont la puissance de calcul, les algorithmes et les données.Étant donné que la puissance de calcul peut former un réseau d’approvisionnement par décentralisation, l’algorithme peut-il avoir des idées similaires pour former un réseau d’approvisionnement de modèle d’algorithme?
Avant d’analyser le projet de piste, comprenons d’abord la signification du modèle d’algorithme décentralisé.
Essentiellement, un réseau d’algorithmes décentralisé est un marché de services d’algorithme AI décentralisé qui relie de nombreux modèles d’IA différents. pour répondre aux questions pour fournir des réponses.Chat-GPT est un modèle d’IA développé par OpenAI, qui peut comprendre et produire des textes similaires aux humains.
En termes simples, le Chatgpt est comme un étudiant avec de fortes capacités pour aider à résoudre différents types de problèmes, tandis qu’un réseau d’algorithmes décentralisé est comme une école avec de nombreux élèves pour aider à résoudre les problèmes. , Les écoles qui peuvent recruter des élèves du monde entier ont un grand potentiel.
Actuellement, dans le domaine des modèles d’algorithmes décentralisés, il existe également des projets dans leurs tentatives et explorations.
Dans Bittensor, le côté d’approvisionnement du modèle algorithmique (ou mineurs) contribue à leurs modèles d’apprentissage automatique au réseau.Ces modèles peuvent analyser les données et fournir des informations.Les fournisseurs de modèles recevront un token de crypto-monnaie Tao en récompense pour leurs contributions.
Pour garantir la qualité des réponses aux questions, Bittensor utilise un mécanisme consensuel unique pour s’assurer que le réseau correspond aux meilleures réponses.Plusieurs mineurs de modèles fournissent des réponses à la demande.Le validateur du réseau commence alors à fonctionner, détermine la meilleure réponse et le renvoie à l’utilisateur.
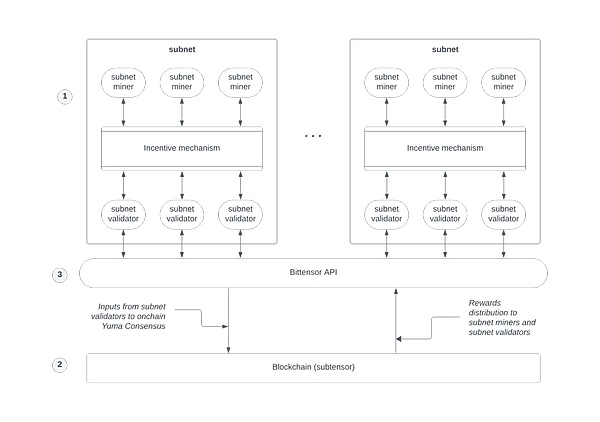
Le jeton de Bittensor Tao joue principalement deux rôles dans tout le processus. Tâches complètes du réseau.
Étant donné que Bittensor est décentralisé, toute personne ayant un accès Internet peut rejoindre le réseau, à la fois en tant qu’utilisateur posant des questions et en tant que mineur fournissant des réponses.Cela permet à plus de gens d’utiliser une intelligence artificielle puissante.
En bref, la prise de réseaux tels que Bittensor à titre d’exemple, le champ décentralisé de la modélisation algorithmique a le potentiel de créer une situation plus ouverte et transparente dans laquelle les modèles d’intelligence artificielle peuvent être formés, partagés et utilisés de manière sécurisée et décentralisée.En outre, il existe des réseaux de modèles algorithmiques décentralisés comme les bases basées.
À mesure que les plates-formes de modèles algorithmiques décentralisées évoluent, elles permettra aux petites entreprises de concurrencer les grandes organisations en utilisant les meilleurs outils d’IA, ayant ainsi un impact potentiellement significatif sur diverses industries.
3.1.3 Collecte de données décentralisée
Pour la formation des modèles d’IA, une grande quantité de données est essentielle.Cependant, la plupart des sociétés Web2 prennent toujours les données des utilisateurs pour elles-mêmes.C’est devenu un grand obstacle au développement de l’industrie de l’IA.
Cependant, d’un autre côté, certaines plateformes Web2 vendent des données utilisateur aux sociétés d’IA sans partager de profit aux utilisateurs.Reddit, par exemple, a conclu un accord de 60 millions de dollars avec Google pour permettre à Google former des modèles d’IA sur ses publications.Cela conduit aux droits de collecte de données occupés par de grandes parties Capital et Big Data, ce qui conduit au développement à forte intensité de capital de l’industrie.
Face à cette situation actuelle, certains projets combinent WEB3 avec des incitations à jetons pour obtenir une collecte de données décentralisée.Prenant l’exemple de Publicai, dans les utilisateurs de Publicai, peut participer comme deux types de rôles:
En retour, les utilisateurs peuvent obtenir des incitations en jetons grâce à ces deux types de contributions, favorisant ainsi une relation gagnant-gagnant entre les contributeurs de données et le développement de l’industrie de l’intelligence artificielle.
En plus de projets comme Publicai qui se spécialisent dans la collecte de données pour la formation de l’IA, de nombreux projets collectent également des données décentralisées grâce à des incitations à jetons. DiMo recueille les données sur les voitures de l’utilisateur, qui collecte des données météorologiques, etc. .
3.1.4 ZK protège la confidentialité des utilisateurs dans l’IA
En plus des avantages de la décentralisation, la technologie de la blockchain apporte une autre chose très importante, qui est une preuve de connaissances zéro.Grâce à la technologie des connaissances zéro, la confidentialité peut être protégée lors de la vérification des informations.
Dans l’apprentissage automatique traditionnel, les données doivent généralement être stockées et traitées de manière centralisée, ce qui peut entraîner le risque de violations de confidentialité des données.D’un autre côté, les méthodes qui protègent la confidentialité des données, telles que le cryptage des données ou la dé-identification des données, peuvent limiter la précision et les performances des modèles d’apprentissage automatique.
La technologie de preuve de connaissance zéro peut aider à faire face à ce dilemme et résoudre le conflit entre la protection de la vie privée et le partage de données.
ZKML (Zero-Knowledge Machine Learning) permet la formation et l’inférence des modèles d’apprentissage automatique sans révéler les données brutes en utilisant une technologie de preuve de connaissance zéro.La preuve de connaissances zéro permet aux caractéristiques des données et aux résultats du modèle d’être corrects sans révéler le contenu réel des données.
L’objectif principal de ZKML est d’atteindre un équilibre entre la protection de la vie privée et le partage de données.Il peut être appliqué à divers scénarios, tels que l’analyse des données médicales et de santé, l’analyse des données financières et la coopération inter-organisationnelle.En utilisant ZKML, les individus peuvent protéger la confidentialité de leurs données sensibles tout en partageant des données avec d’autres pour des informations et des opportunités plus larges de collaborer sans se soucier du risque de violations de confidentialité des données.
Le domaine est encore à ses débuts et la plupart des projets sont toujours en cours d’expression.Incorporer la confidentialité au cœur de son infrastructure de réseau distribuée à l’aide du modèle de langage grand Zero Knowledge (ZK-LLM) pour s’assurer que les données utilisateur restent privées tout au long de l’opération de réseau.
Ici, nous expliquons brièvement ce qu’est le cryptage homorphe complet (FHE).Le chiffrement entièrement homorphe est une technologie de chiffrement qui peut calculer les données à l’état crypté sans décryptage.Cela signifie que diverses opérations mathématiques (telles que l’addition, la multiplication, etc.) effectuées sur les données cryptées en utilisant le FHE peuvent être effectuées tout en gardant les données cryptées et obtenez les résultats obtenus en effectuant les mêmes opérations sur les données non incryptées d’origine. des données utilisateur.
De plus, en plus des quatre catégories ci-dessus, en termes de support d’IA de Web3, il existe également des projets de blockchain comme Cortex qui soutiennent l’exécution des programmes d’IA sur la chaîne.Actuellement, l’exécution de programmes d’apprentissage automatique sur les blockchains traditionnels est confrontée à un défi, où les machines virtuelles sont extrêmement inefficaces lors de l’exécution de tout modèle d’apprentissage automatique non complexe.Par conséquent, la plupart des gens pensent qu’il est impossible de gérer l’intelligence artificielle sur les blockchains.Cortex Virtual Machine (CVM) utilise des GPU pour exécuter des programmes AI sur la chaîne et est compatible avec EVM.En d’autres termes, la chaîne de cortex peut exécuter tous les Dapps Ethereum et intégrer l’apprentissage automatique AI dans ces DAPP sur cette base.Cela permet le fonctionnement des modèles d’apprentissage automatique de manière décentralisée, immuable et transparente, car le consensus de réseau valide chaque étape du raisonnement de l’IA.
3.2 AI aide Web3
Dans la collision entre l’IA et le Web3, en plus de l’aide de Web3 à l’IA, l’aide de l’IA à l’industrie Web3 mérite également une attention.La contribution fondamentale de l’intelligence artificielle réside dans l’amélioration de la productivité, il existe donc de nombreuses tentatives dans les contrats intelligents de l’audit de l’IA, l’analyse et la prédiction des données, les services personnalisés, la sécurité et la protection de la confidentialité.
3.2.1 Analyse et prévision des données
À l’heure actuelle, de nombreux projets Web3 ont commencé à intégrer les services d’IA existants (tels que ChatGPT) ou à développer leurs propres services pour fournir des services d’analyse et de prédiction des données aux utilisateurs de Web3.Il couvre une large gamme, notamment en fournissant des stratégies d’investissement via des algorithmes d’IA, des outils d’IA d’analyse sur chaîne, des prévisions de prix et de marché, etc.
Par exemple, Pond utilise un algorithme de graphe AI pour prédire les précieux jetons alpha à l’avenir, fournissant des conseils d’assistance en placement aux utilisateurs et aux institutions; Prise en charge des tendances des prix prédire, aidez les utilisateurs à obtenir des bénéfices et des bénéfices.
Il existe également des plateformes de concurrence d’investissement telles que NuMerai.Nuirai calcule comment ces prédictions fonctionnent au cours du mois prochain, et les candidats peuvent parier sur la RMN sur le modèle et gagner de l’argent en fonction des performances du modèle.
De plus, les plateformes d’analyse de données sur chaîne telles qu’Arkham combinent également l’IA pour les services.Arkham relie les adresses blockchain à des entités telles que les échanges, les fonds et les baleines géantes, et présente aux utilisateurs des données et des analyses clés de ces entités pour fournir aux utilisateurs des avantages décisionnels.Une partie de sa combinaison avec l’IA est qu’Arkham Ultra utilise des algorithmes pour faire correspondre les adresses avec des entités du monde réel, développé par des contributeurs de base d’Arkham avec le soutien de Palantir et des fondateurs d’Openai sur trois ans.
3.2.2 Service personnalisé
Dans les projets Web2, l’IA possède de nombreux scénarios d’application dans les domaines de la recherche et de la recommandation, répondant aux besoins personnalisés des utilisateurs.Il en va de même dans les projets Web3.
Par exemple, Dune, une plate-forme d’analyse de données bien connue, a récemment lancé l’outil de baguette pour rédiger des requêtes SQL à l’aide de modèles de grande langue.Grâce à la fonction de création de baguettes, les utilisateurs peuvent générer automatiquement des requêtes SQL basées sur des problèmes de langage naturel, afin que les utilisateurs qui ne comprennent pas SQL puissent également rechercher très facilement.
En outre, certaines plateformes de contenu Web3 ont également commencé à intégrer le résumé du contenu. Zone La principale source de toutes les connaissances objectives et de haute qualité liées à la technologie de la blockchain et aux crypto-monnaies facilite la blockchain à découvrir et à acquérir à l’échelle mondiale, et fournit aux utilisateurs des informations auxquelles ils peuvent faire confiance. Kaito, un moteur de recherche basé sur LLM, s’engage à devenir une plate-forme de recherche Web3 et à modifier la façon dont Web3 obtient des informations.
En termes de création, il existe également des projets comme NFPRomppt qui réduisent les coûts de création des utilisateurs.NFPRomppt permet aux utilisateurs de générer des NFT plus facilement via l’IA, réduisant ainsi les coûts créatifs de l’utilisateur et fournissant de nombreux services personnalisés en termes de création.
3.2.3 Contrat intelligent de l’audit AI
Dans le champ Web3, l’audit des contrats intelligents est également une tâche très importante.
Comme Vitalik l’a mentionné une fois, l’un des plus grands défis auxquels l’espace de crypto-monnaie est les erreurs de notre code.Et une possibilité attendue est que l’intelligence artificielle (IA) peut simplifier considérablement l’utilisation d’outils de vérification formelle pour prouver qu’un ensemble de codes satisfaisant des attributs spécifiques.Si nous pouvons le faire, il est possible que nous ayons des EVS SEK sans erreur (tels que les machines virtuelles Ethereum).Plus vous réduisez le nombre d’erreurs, plus l’espace augmentera la sécurité et l’IA est très utile pour y parvenir.
Par exemple, le projet 0x0.ai fournit un auditeur de contrat intelligent de l’intelligence artificielle, un outil qui utilise des algorithmes avancés pour analyser les contrats intelligents et identifier des vulnérabilités ou des problèmes potentiels qui peuvent entraîner une fraude ou d’autres risques de sécurité.Les auditeurs utilisent des techniques d’apprentissage automatique pour identifier les modèles et les exceptions dans le code, marquant les problèmes potentiels pour un examen plus approfondi.
En plus des trois catégories ci-dessus, il existe également des cas natifs qui utilisent l’IA pour aider le champ Web3. L’agrégation de Dex multi-chaîne Hera, qui utilise l’IA pour fournir la plus large gamme de jetons et les meilleurs chemins de trading entre toutes les paires de jetons.
Limites et défis des projets AI + Web3
4.1 Les obstacles réels en puissance de calcul décentralisée
Parmi les projets actuels qui aident l’IA, une grande partie des projets qui prennent en charge Web3 se concentrent sur la puissance de calcul décentralisée. Il y a aussi des problèmes pratiques qui doivent être résolus:
Par rapport aux fournisseurs de services de puissance de calcul centralisés, les produits de puissance de calcul décentralisés reposent généralement sur les nœuds et les participants distribués dans le monde pour fournir des ressources informatiques.Étant donné que les connexions réseau entre ces nœuds peuvent avoir la latence et l’instabilité, les performances et la stabilité peuvent être pires que le produit de puissance de calcul centralisé.
De plus, la disponibilité de produits de puissance informatique décentralisés est affecté par le degré de correspondance entre l’offre et la demande.S’il n’y a pas assez de fournisseurs ou si la demande est trop élevée, cela peut conduire à des ressources insuffisantes ou à une incapacité à répondre aux besoins des utilisateurs.
Enfin, les produits de puissance de calcul décentralisés impliquent généralement plus de détails techniques et de complexité que les produits de puissance de calcul centralisés.Les utilisateurs peuvent avoir besoin de comprendre et de gérer les connaissances sur les réseaux distribués, les contrats intelligents et les paiements de crypto-monnaie, et le coût de la compréhension et de l’utilisation des utilisateurs deviendra plus élevé.
Après une discussion approfondie avec un grand nombre de projets de puissance de calcul décentralisés, j’ai constaté que la puissance de calcul décentralisée actuelle ne peut être limitée qu’au raisonnement d’IA plutôt qu’à la formation en IA.
Ensuite, j’utiliserai quatre petites questions pour vous aider à comprendre les raisons derrière:
1. Pourquoi les projets de puissance informatique la plupart des plus décentralisés choisissent-ils du raisonnement en IA au lieu de la formation d’IA?
2. Où Nvidia est-elle géniale?Quelle est la raison pour laquelle la formation de puissance informatique décentralisée est difficile?
3. À quoi ressemblera la fin de la puissance de calcul décentralisée (rendu, akash, io.net, etc.)?
4. À quoi ressemblera la fin de l’algorithme décentralisé (Bittensor)?
Ensuite, décollons la couche cocon par calque:
1) En regardant cette piste, les projets d’alimentation informatique les plus décentralisés choisissent de faire un raisonnement en IA au lieu de la formation.Le noyau est les différentes exigences pour la puissance de calcul et la bande passante.
Pour aider tout le monde à mieux comprendre, comparons l’IA à un étudiant:
Formation sur l’IA: Si nous comparons l’intelligence artificielle à un étudiant, la formation est similaire à la fourniture de l’intelligence artificielle avec beaucoup de connaissances, et les exemples peuvent également être compris comme des données que nous l’appelons souvent, et l’intelligence artificielle apprend de ces exemples de connaissances.Étant donné que la nature de l’apprentissage nécessite la compréhension et la mémoire d’une grande quantité d’informations, ce processus nécessite beaucoup de puissance et de temps de calcul.
Raisonnement de l’IA: alors qu’est-ce que le raisonnement?Il peut être compris comme en utilisant les connaissances apprises pour résoudre des problèmes ou passer des examens. .
Il est facile de constater que la différence de difficulté entre les deux est essentiellement que la formation en IA de grande envergure nécessite une énorme quantité de données et la bande passante requise pour la communication de données à grande vitesse, il est donc actuellement extrêmement difficile de mettre en œuvre un pouvoir de calcul décentralisé comme formation .Cependant, le besoin d’inférence de données et de bande passante est beaucoup plus petit et la possibilité de mise en œuvre est plus grande.
Pour les grands modèles, la chose la plus importante est la stabilité.D’un autre côté, les besoins en puissance de calcul relativement faible sont possibles, tels que l’inférence de l’IA mentionnée ci-dessus, ou la formation de modèles verticaux de petite et moyenne taille pour certains scénarios spécifiques, ce qui est possible en décentralisation. dans le réseau de puissance de calcul qui peut répondre à ces besoins de puissance de calcul relativement importants.
2) Alors, où sont les données et le point de jam de la bande passante?Pourquoi la formation décentralisée est-elle difficile à réaliser?
Cela implique deux éléments clés de la formation des grands modèles: une puissance de calcul à carte unique et plusieurs cartes sont connectées en parallèle.
Power informatique à cartes à carte: à l’heure actuelle, tous les centres qui nécessitent une formation de grands modèles, nous l’appelons des centres de supercalcul.Pour faciliter la compréhension de chacun, nous pouvons utiliser le corps humain comme métaphore.Si la puissance de calcul d’une seule cellule (GPU) est très forte, la puissance de calcul globale (numéro X à cellule unique) peut également être très forte.
Connexion parallèle multi-cartes: la formation d’un grand modèle est souvent de 100 milliards de gb.Par conséquent, nous devons mobiliser ces dizaines de milliers de cartes pour la formation. En partie, la formation sur différentes cartes graphiques peut nécessiter les résultats de B lors de la formation A, de sorte que plusieurs cartes sont impliquées en parallèle.
Pourquoi Nvidia est-elle si puissante et sa valeur marchande a été décollée, mais il est difficile pour AMD et Huawei et Horizon domestiques.Le noyau n’est pas la puissance de calcul à carte unique elle-même, mais deux aspects: l’environnement logiciel CUDA et la communication multi-cartes NVLink.
D’une part, il est très important de savoir s’il existe un écosystème logiciel qui peut s’adapter au matériel, comme le système CUDA de Nvidia.
D’un autre côté, c’est la communication multi-cartes.En raison de l’existence de NVLink, il est impossible de connecter les cartes NVIDIA et AMD; Autour du monde.
Le premier point explique pourquoi AMD, Huawei et Horizon en Chine sont actuellement difficiles à rattraper;
3) À quoi ressemblera la fin de la puissance de calcul décentralisée?
La puissance de calcul décentralisée est actuellement difficile à former des modèles importants.Ses exigences pour la connexion parallèle de plusieurs cartes sont très élevées et la bande passante est limitée par la distance physique.NVIDIA utilise NVLink pour réaliser une communication multi-cartes.
Mais d’un autre côté, la demande de puissance de calcul relativement faible est possible, telle que l’inférence de l’IA ou la formation de modèles verticaux petits et moyens dans certains scénarios spécifiques, ce qui est possible dans les réseaux de puissance de calcul décentralisés. De grands fournisseurs de services de nœuds, ils ont le potentiel de répondre à ces besoins de puissance de calcul relativement importants.En plus de scénarios informatiques Edge comme le rendu, il est également relativement facile à mettre en œuvre.
4) À quoi ressemblera la fin du modèle d’algorithme décentralisé?
La fin du modèle d’algorithme décentralisé dépend de la fin de la future AI. Il n’est pas nécessaire de se lier à un grand modèle pour le produit de la couche d’application, mais coopère avec plusieurs grands modèles.
4.2 La combinaison d’Ai + Web3 est relativement rugueuse et 1 + 1> 2 n’est pas réalisée
Actuellement, parmi les projets qui combinent Web3 avec l’IA, en particulier en termes d’IA pour aider les projets Web3, la plupart des projets utilisent toujours l’IA en surface et ne reflètent pas vraiment l’intégration profonde entre l’IA et la crypto-monnaie.Ce type d’application de surface se reflète principalement dans les deux aspects suivants:
Bien qu’il y ait encore ces limites dans les projets Web3 et AI actuels, nous devons réaliser que ce n’est qu’un stade précoce du développement.À l’avenir, nous pouvons nous attendre à des recherches et à une innovation plus approfondies pour obtenir une intégration plus étroite entre l’IA et la crypto-monnaie et créer des solutions plus indigènes et significatives dans des domaines tels que la finance, les organisations autonomes décentralisées, les marchés de prévision et le plan NFT.
4.3 L’économie token devient un tampon pour le récit du projet IA
Comme le problème du modèle d’entreprise des projets d’IA mentionnés au début, car de plus en plus de modèles importants ont commencé à progressivement open source, un grand nombre de projets AI + Web3 sont souvent difficiles à développer et à collecter des fonds dans Web2, nous choisissons donc de superposer Le récit de WEB3.
Mais la vraie clé est de savoir si l’intégration de l’économie des jetons peut vraiment aider les projets d’IA à résoudre les besoins réels, ou s’il s’agit simplement d’une valeur narrative ou à court terme, il doit en fait être remis en question.
À l’heure actuelle, la plupart des projets AI + Web3 sont loin d’atteindre la scène pratique.
Résumer
À l’heure actuelle, de nombreux cas et applications ont émergé dans des projets AI + Web3.Tout d’abord, la technologie AI peut fournir à Web3 des scénarios d’application plus efficaces et intelligents.Grâce à l’analyse des données et aux capacités de prédiction de l’IA, les utilisateurs de Web3 peuvent avoir de meilleurs outils dans la prise de décision d’investissement et d’autres scénarios;Dans le même temps, la technologie de l’IA peut également fournir des recommandations plus précises et intelligentes et des services personnalisés pour des applications décentralisées afin d’améliorer l’expérience utilisateur.
Dans le même temps, la décentralisation et la programmabilité de Web3 offrent également de nouvelles opportunités pour le développement de la technologie de l’IA.Grâce à des incitations à jet, des projets de calcul décentralisés fournissent de nouvelles solutions au dilemme de fourniture insuffisante de puissance de calcul de l’IA.L’autonomie des utilisateurs de Web3 et les mécanismes de confiance ont également apporté de nouvelles possibilités au développement de l’IA.
Bien que le projet de croisement AI + Web3 actuel en soit encore à ses débuts et qu’il y a de nombreuses difficultés à faire face, elle apporte également de nombreux avantages.Par exemple, les produits de puissance de calcul décentralisés ont certaines lacunes, mais ils réduisent leur dépendance à l’égard des institutions centralisées, offrent une plus grande transparence et auditabilité et permettent une participation et une innovation plus larges.Les produits de calcul de calcul décentralisés peuvent être une option précieuse pour les cas d’utilisation spécifiques et les besoins des utilisateurs; Couverture des données et promouvoir la diversité et l’inclusion des données, etc.Dans la pratique, ces avantages et inconvénients doivent être pesés et gérés et des mesures techniques sont prises pour surmonter les défis pour garantir que les projets de collecte de données décentralisés ont un impact positif sur le développement de l’IA.
En général, l’intégration de l’AI + Web3 offre des possibilités illimitées pour l’innovation technologique future et le développement économique.En combinant l’analyse intelligente et les capacités de prise de décision de l’IA avec la décentralisation et l’autonomie des utilisateurs de Web3, nous pensons qu’à l’avenir, nous pouvons construire un système économique et social plus intelligent, plus ouvert et plus juste.







