Auteur: Kyle_13, Source: Auteur Twitter @kylewmi
Merci pour votre arrivée aujourd’hui.Nous avons une série de développements super excitants sur la technologie AO à partager avec vous.Nous ferons d’abord une démo, puis Nick et moi essaierons de construire un agent d’IA ici qui utilisera un modèle de langue large dans un contrat intelligent, achetant et vendant en fonction du sentiment de chat que vous êtes sur le point d’entendre dans le système .Aujourd’hui, nous le construire à partir de zéro sur place et espérons que tout se passe bien.
Oui, vous verrez comment tout faire par vous-même.
Les progrès technologiques ici permettent vraiment de dépasser les autres systèmes de contrats intelligents.Cela était déjà vrai auparavant, et maintenant cela ressemble de plus en plus à un supercalculateur décentralisé qu’un réseau de contrats intelligents traditionnel.Mais il dispose de toutes les fonctionnalités d’un réseau de contrats intelligents.Par conséquent, nous sommes très heureux de partager tout cela avec vous.Sans plus tarder, commençons la démo, et nous aurons une discussion, et nous allons construire quelque chose sur place ensemble.
Bonjour à tous, merci pour votre arrivée aujourd’hui.Nous sommes très heureux d’annoncer trois mises à jour techniques majeures de l’accord AO.Ensemble, ils atteignent un grand objectif de soutenir de grands modèles de langage fonctionnant dans des environnements décentralisés dans le cadre des contrats intelligents.Ce ne sont pas seulement des modèles de jouets, de petits modèles ou des modèles compilés dans leurs propres fichiers binaires.
Il s’agit d’un système complet qui vous permet d’exécuter presque tous les principaux modèles actuellement open source et disponibles.Par exemple, Llama 3 fonctionne sur la chaîne dans les contrats intelligents, il en va de même pour GPT, ainsi que pour les modèles d’Apple, etc.Ceci est le résultat des efforts conjoints de l’ensemble de l’écosystème, et trois progrès technologiques majeurs font également partie de ce système.Par conséquent, je suis très heureux de vous présenter tout cela.

La situation générale est que LLM (modèle de grande langue) peut désormais s’exécuter dans des contrats intelligents.Vous avez peut-être entendu parler de crypto-monnaies AI et IA décentralisées à plusieurs reprises.En fait, à l’exception d’un système dont nous allons discuter aujourd’hui, presque tous ces systèmes sont des AIS comme Oracles, c’est-à-dire, exécutez AI hors de la chaîne, puis mettez les résultats d’exécution sur la chaîne à des fins en aval.
Nous n’en parlons pas.Nous parlons du raisonnement de modèle de grande langue dans le cadre de l’exécution de l’état de contrat intelligent.Tout cela est grâce au disque dur AO que nous avons et au mécanisme de traitement hyperparalalaire de l’AO, ce qui signifie que vous pouvez exécuter beaucoup de calculs sans affecter les différents processus que j’utilise.Nous pensons que cela nous permettra de créer un système financier d’agence autonome décentralisé très riche.

Jusqu’à présent, dans la finance décentralisée (DEFI), nous avons essentiellement pu faire l’exécution de transactions originales sans confiance.Les interactions dans différents jeux économiques, comme l’emprunt et l’échange, ne nécessitent aucune confiance.Ce n’est qu’un aspect du problème.Si vous considérez les marchés financiers mondiaux.
Oui, il existe une variété d’originaux économiques différents qui fonctionnent de différentes manières.Il y a des obligations, des actions, des produits de base et des dérivés, etc.Mais quand nous parlons vraiment du marché, ce n’est pas seulement cela, c’est en fait la couche intelligente.C’est la personne qui décide d’acheter, de vendre, d’emprunter ou de participer à divers jeux financiers.
Jusqu’à présent, dans l’écosystème financier décentralisé, nous avons réussi à transférer tous ces originaux à un état sans confiance.Par conséquent, vous pouvez échanger sur uniswap sans faire confiance aux opérateurs d’UNISWAP.En fait, fondamentalement, il n’y a pas d’opérateurs.La couche intelligente du marché est laissée pour compte.Donc, si vous souhaitez participer aux investissements des crypto-monnaies et que vous ne voulez pas faire toutes vos recherches et votre engagement vous-même, vous devez trouver un fonds.
Vous pouvez faire confiance à leurs fonds, puis ils vont effectuer des décisions intelligentes et les transmettre en aval à l’exécution originale de base du réseau lui-même.Nous pensons que dans AO, nous avons en fait la capacité de transférer la partie intelligente du marché, c’est-à-dire l’intelligence qui conduit à la prise de décision, au réseau lui-même.Ainsi, un moyen simple de le comprendre pourrait être de l’imaginer.
Un fonds spéculatif ou une application de gestion de portefeuille à qui vous pouvez faire confiance peut exécuter un ensemble d’instructions intelligentes dans le réseau, transférant ainsi la sans-file du réseau dans le processus de prise de décision.Cela signifie qu’un compte anonyme, comme le trader Yolo 420 numéro un (un trader audacieux et occasionnel), peut créer une stratégie nouvelle et intéressante et la déployer sur le réseau, où vous pouvez y mettre du capital sans réelle confiance.
Vous pouvez désormais construire des agents autonomes qui interagissent avec les grands modèles statistiques.Le modèle statistique grand le plus courant est le modèle grand langage qui peut traiter et générer du texte.Cela signifie que vous pouvez mettre ces modèles dans des contrats intelligents dans le cadre d’une stratégie développée par quelqu’un avec de nouvelles idées et les exécuter intelligemment dans le réseau.

Vous pouvez imaginer faire une analyse de base des sentiments.Par exemple, si vous lisez les nouvelles, vous décidez que c’est le bon moment pour acheter et vendre ce dérivé.C’est le bon moment pour faire l’un ou l’autre.Vous pouvez prendre des décisions similaires aux humains de manière sans confiance.Ce n’est pas seulement une théorie.Nous avons créé une pièce de mèmes intéressante appelée Llama Fed.Fondamentalement, l’idée est qu’il s’agit d’un simulateur de monnaie fiduciaire où un tas de lamas (alpagas) sont représentés par le modèle LLAMA 3.
Ils sont comme une combinaison de lama et du président de la Fed, vous pouvez aller les trouver et leur demander d’émettre des jetons et ils évalueront votre demande.Les modèles de grands langues eux-mêmes opèrent eux-mêmes une politique monétaire, complètement autonome et sans confiance.Nous l’avons construit, mais nous ne pouvions pas le contrôler.Ils exploitent des politiques monétaires et déterminent qui devrait obtenir les jetons et qui ne devrait pas.Il s’agit d’une petite application très intéressante de cette technologie et, espérons-le, inspire toutes les autres applications possibles dans l’écosystème.

Pour y parvenir, nous devons créer trois nouvelles capacités de base pour AO, certaines sur la couche de protocole de base et d’autres à la couche d’application.Ceci est non seulement utile pour l’exécution de modèles de grands langues, mais est plus étendu et excitant pour les développeurs AO.Je suis donc content de vous les présenter aujourd’hui.
La première de ces nouvelles technologies est la prise en charge de l’assemblage Web 64 bits.Cela ressemble un peu à un terme technique, mais j’ai un moyen de faire comprendre à tout le monde ce que cela signifie.Fondamentalement, le support Web Assembly 64 permet aux développeurs de créer des applications qui utilisent plus de 4 Go de mémoire.Nous présenterons les nouvelles restrictions plus tard, elles sont assez incroyables.
 Si vous n’êtes pas développeur, vous pouvez le comprendre de cette façon: quelqu’un vous a demandé d’écrire un livre et vous êtes enthousiasmé par l’idée, mais ils disent que vous ne pouvez écrire que 100 pages.Pas plus ou moins.Vous pouvez exprimer les idées dans le livre, mais cela ne peut pas être fait de manière naturelle et normale, car il y a des restrictions externes et vous devez y répondre et changer la façon dont vous écrivez pour l’adapter.
Si vous n’êtes pas développeur, vous pouvez le comprendre de cette façon: quelqu’un vous a demandé d’écrire un livre et vous êtes enthousiasmé par l’idée, mais ils disent que vous ne pouvez écrire que 100 pages.Pas plus ou moins.Vous pouvez exprimer les idées dans le livre, mais cela ne peut pas être fait de manière naturelle et normale, car il y a des restrictions externes et vous devez y répondre et changer la façon dont vous écrivez pour l’adapter.
Dans l’écosystème du contrat intelligent, c’est plus qu’une simple limite de 100 pages.Je dirais que c’est un peu comme construire dans des versions antérieures d’AO.Ethereum a une limite de mémoire de 48 Ko, tout comme quelqu’un vous a demandé d’écrire un livre qui ne fait qu’une phrase, et vous ne pouvez utiliser que les 200 meilleurs mots anglais les plus populaires.Construire une application vraiment excitante dans ce système est extrêmement difficile.

Ensuite, il y a Solana, où vous pouvez accéder à 10 Mo de mémoire de travail.C’est évidemment une amélioration, mais en gros, nous parlons d’une page.ICP, Protocole informatique Internet, permet de prendre en charge 3 Go de mémoire.C’est complet en théorie, mais ils ont dû le réduire à 3 Go.Maintenant, avec 3 Go de mémoire, vous pouvez exécuter de nombreuses applications différentes, mais vous ne pouvez certainement pas exécuter de grandes applications d’IA.Ils nécessitent le chargement de grandes quantités de données dans la mémoire principale pour un accès rapide.Cela ne peut pas être implémenté efficacement dans 3 Go de mémoire.
Lorsque nous avons sorti AO en février de cette année, nous avions également une limite de mémoire de 4 Go, qui est en fait originaire de l’assemblée Web 32.Maintenant, cette limite de mémoire a complètement disparu au niveau du protocole.Au lieu de cela, la limite de mémoire au niveau du protocole est 18EB (exaoctets).C’est une énorme quantité de stockage.
Cela prendra un certain temps jusqu’à ce que cela soit utilisé en mémoire pour les calculs plutôt que pour les supports de stockage à long terme.Au niveau de la mise en œuvre, l’unité informatique du réseau AO a désormais accès à 16 Go de mémoire, mais à l’avenir, il sera relativement facile de le remplacer par une mémoire de capacité plus grande sans modifier le protocole.16 Go est suffisant pour exécuter des calculs de modèles à grande langue, ce qui signifie que vous pouvez télécharger et exécuter des modèles 16 Go sur AO aujourd’hui.Par exemple, la version un quantitative de Falcon 3 de Llama 3 et de nombreux autres modèles.
Il s’agit d’un composant central nécessaire pour créer un système informatique de base pour les langages intelligents.Maintenant qu’il est pleinement pris en charge sur la chaîne dans le cadre d’un contrat intelligent, nous pensons que c’est très, très excitant.
Cela élimine une limitation de calcul majeure de l’AO et des systèmes de contrat intelligents ultérieurs.Lorsque nous avons publié AO en février de cette année, vous remarquerez peut-être que nous avons mentionné à plusieurs reprises dans la vidéo que vous avez une puissance de calcul illimitée, mais il y a une limite, c’est-à-dire que vous ne pouvez pas dépasser 4 Go de mémoire.C’est la levée de cette restriction.Nous pensons que c’est un progrès très excitant, et 16 Go suffisent à exécuter presque tous les modèles que vous souhaitez exécuter dans le champ d’IA actuel.
Nous avons pu augmenter la limite de 16 Go sans modifier le protocole, qui sera relativement facile à l’avenir, un grand pas par rapport à l’exécution initiale de l’assemblage Web 64.Par conséquent, il s’agit en soi une énorme amélioration des capacités du système.La deuxième technologie majeure qui permet à de grands modèles de langage de fonctionner sur AO est WeavedRive.

WevevedRive vous permet d’accéder aux données d’Arweave dans AO comme un disque dur local.Cela signifie que vous pouvez ouvrir n’importe quel ID de transaction dans l’AO qui est authentifié par l’unité de planification et le télécharger sur le réseau.Bien sûr, vous pouvez accéder à ces données et les lire dans votre programme, tout comme un fichier sur votre disque dur local.

Nous savons tous qu’il y a environ 6 milliards de données transactionnelles stockées sur Arweave actuellement, il s’agit donc d’un énorme point de départ de l’ensemble de données.Cela signifie également qu’à l’avenir, la motivation de télécharger des données sur Arweave augmente, car ces données peuvent également être utilisées dans les programmes AO.Par exemple, lorsque nous obtenons un modèle de langue large pour fonctionner sur Arweave, nous téléchargeons un modèle d’une valeur d’environ 1 000 $ au réseau.Mais ce n’est que le début.
Avec un réseau de contrat intelligent avec un système de fichiers local, le nombre d’applications que vous pouvez créer est énorme.Donc, c’est très excitant.Encore mieux, nous avons construit un système qui vous permet de diffuser des données dans l’environnement d’exécution.C’est une nuance technique, mais vous pouvez imaginer revenir à l’analogie du livre.
Quelqu’un vous a dit que je voulais accéder à l’une des données de votre livre.Je veux obtenir un tableau de ce livre.Dans un système simple, même dans le réseau de contrats intelligents actuel, ce serait une énorme amélioration et vous donneriez tout le livre.Cependant, cela est évidemment inefficace, surtout si ce livre est un grand modèle statistique avec des milliers de pages.
Ceci est extrêmement inefficace.Au lieu de cela, ce que nous faisons dans AO, c’est que vous pouvez lire directement les octets.Vous allez directement à la position du graphique dans le livre, copiez simplement le graphique dans votre application et exécutez-la.Cela améliore considérablement l’efficacité du système.Ce n’est pas seulement un produit minimalement viable (MVP), c’est un mécanisme d’accès aux données entièrement fonctionnel et bien construit.Vous avez donc un système informatique infini et un disque dur infini, les combiner ensemble et vous avez un supercalculateur.
Cela n’a jamais été construit auparavant et maintenant il est disponible pour tous ceux qui sont les plus bas.C’est là que AO est et nous sommes très excités à ce sujet.L’implémentation de ce système est également au niveau du système d’exploitation.Nous transformons donc Wevevedrive en un sous-protocole d’AO, qui est une extension d’unité informatique que n’importe qui peut charger.C’est intéressant car c’est la première extension de ce type.
AO a toujours eu la possibilité d’ajouter une mise à l’échelle à votre environnement d’exécution.Tout comme vous avez un ordinateur, vous souhaitez brancher plus de mémoire ou insérer une carte graphique, vous mettez physiquement une unité dans le système.Vous pouvez le faire sur l’unité de calcul de l’AO, et c’est ce que nous faisons ici.Ainsi, au niveau du système d’exploitation, vous avez maintenant un disque dur qui représente simplement le système de fichiers ce stockage de données.
Cela signifie que non seulement vous pouvez accéder à ces données dans AO, en créant l’application de la manière habituelle, mais vous pouvez réellement y accéder à partir de n’importe quelle application apportée au réseau.Par conséquent, il s’agit d’une capacité largement applicable qui peut être accessible par toutes les personnes construites dans le système, quelle que soit la langue dans laquelle ils sont écrits, Rust, C, Lure, Solidité, etc., comme s’il s’agissait de caractéristiques natives du système.Dans le processus de construction de ce système, il nous oblige également à créer des protocoles de sous-protocole, à créer des méthodes pour d’autres extensions d’unité informatique afin que d’autres puissent construire des choses passionnantes à l’avenir.
Maintenant, nous avons la possibilité d’exécuter des calculs dans une mémoire centralisée de toute taille et de chargement des données du réseau dans les processus au sein d’AO.
Étant donné que nous avons choisi de construire AO sur l’assemblage Web comme machine virtuelle principale, il est relativement facile à compiler et à exécuter du code existant dans cet environnement.Étant donné que nous avons construit WevevedRive pour l’exposer à un système de fichiers au niveau du système d’exploitation, il est en fait relativement facile d’exécuter LLAMA.CPP (un moteur d’inférence de modèle de grande langue open source) sur le système.

C’est très excitant car cela signifie que vous pouvez exécuter non seulement ce moteur de raisonnement, mais aussi bien d’autres facilement.Par conséquent, le dernier composant qui fait un modèle de langage large exécuté dans AO est le moteur d’inférence du modèle grand langage lui-même.Nous avons porté un système appelé llama.cpp, qui semble un peu mystérieux, mais c’est en fait le premier environnement d’exécution du modèle open source à l’heure actuelle.
En fonctionnant directement dans le contrat SMART AO, il est en fait relativement facile une fois que nous avons la possibilité d’avoir autant de données que dans le système, puis de charger autant de données d’Arweave.
Pour y parvenir, nous travaillons également avec une extension informatique appelée SIMD (multi-instructions multi-données) qui vous permet d’exécuter ces modèles plus rapidement.Nous avons donc également activé cette fonctionnalité.Cela signifie que ces modèles fonctionnent actuellement sur le CPU, mais sont assez rapides.Si vous avez des calculs asynchrones, il doit convenir à votre scénario d’utilisation.Comme lire un signal d’information et décider des transactions à exécuter, il fonctionne bien dans le système actuel.Mais nous avons également des mises à niveau passionnantes qui seront discutées bientôt, concernant d’autres mécanismes d’accélération, tels que l’utilisation du GPU pour accélérer l’inférence du modèle de langage important.

Llama.cpp vous permet de charger non seulement le premier modèle de META Llama 3, mais aussi de nombreux autres modèles, qui représentent en fait environ 90% ou plus des modèles que vous pouvez télécharger à partir du site de site Web open source, le visage étreint peut s’exécuter dans le système, à partir de GPT-2 Si vous voulez, à 253 et monet, le système de modèle grand langage d’Apple et de nombreux autres modèles.Nous avons donc maintenant le cadre pour télécharger n’importe quel modèle d’Arweave, en utilisant le disque dur pour télécharger le modèle que je souhaite exécuter dans le système.Vous les téléchargez, ce ne sont que des données normales, puis vous pouvez les charger dans le processus AO et les exécuter, obtenir les résultats et travailler comme vous le souhaitez.Nous pensons qu’il s’agit d’un package qui permet des applications qui n’étaient pas possibles dans l’écosystème précédent du contrat intelligent, et même si c’est possible maintenant, le nombre de changements architecturaux dans les systèmes existants tels que Solana est tout simplement imprévisible et non sur son itinéraire Sur l’image.Donc, pour vous montrer cela et le rendre réel et compréhensible, nous avons créé un émulateur, Llama Fed.L’idée de base est que nous obtenons un comité des membres de la Fed, ils sont LLAMA, à la fois en tant que modèle Meta Llama 3 et en tant que président de la Fed.
Nous leur disons également qu’ils sont des lamas, comme Alan Greenspan ou le président de la Fed.Vous pouvez entrer ce petit environnement.
Certaines personnes seront familiarisées avec cet environnement, et c’est en fait comme le dossier que nous travaillons aujourd’hui, vous pouvez parler à Llama et leur demander de vous donner des jetons pour un projet très intéressant, et ils décideront de vous donner en fonction de votre demande.Vous brûlez donc des jetons Arweave, des jetons de guerre (fournis par l’équipe AOX) et ils vous donneront des jetons en fonction de la question de savoir si votre proposition est considérée comme bonne.Par conséquent, il s’agit d’une monnaie mème, et la politique monétaire est complètement autonome et intelligente.Bien que ce soit une forme simple d’intelligence, c’est toujours amusant.Il évaluera vos propositions et les propositions des autres et exécutera la politique monétaire.Tout cela peut désormais être réalisé dans un contrat intelligent en analysant les titres des nouvelles et en prenant des décisions intelligentes ou en interagissant avec le support client et la valeur de retour.Elliot vous le montrera maintenant.

Bonjour à tous, je suis Elliot, et aujourd’hui je vais vous montrer Llama Land, un monde autonome en chaîne en cours d’exécution dans AO, propulsé par le modèle Open Source Llama 3 de Meta.
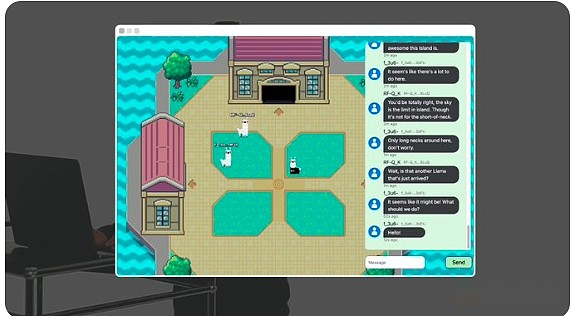 La conversation que nous voyons ici n’est pas seulement une conversation entre les joueurs, mais aussi un lama de nombre complètement autonome.
La conversation que nous voyons ici n’est pas seulement une conversation entre les joueurs, mais aussi un lama de nombre complètement autonome.
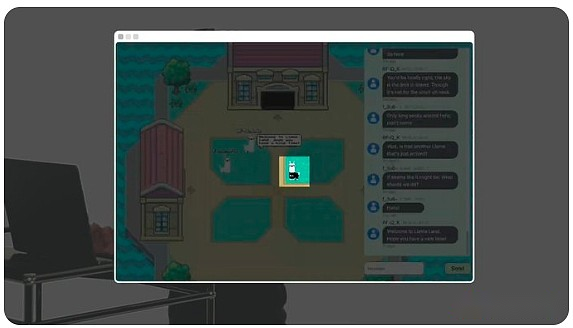
Par exemple, ce lama est humain.
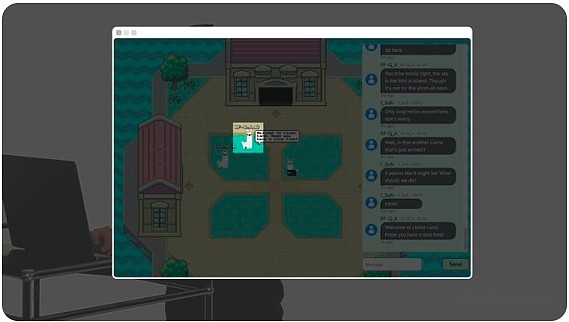
Mais ce lama est sur la chaîne AI.
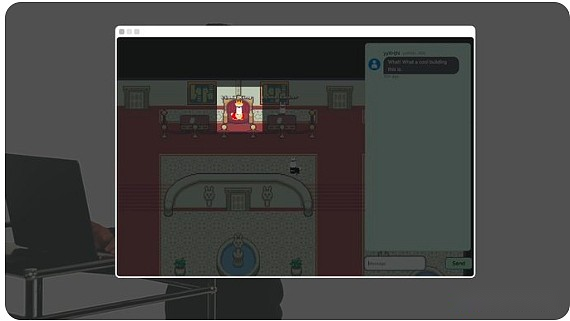
Le bâtiment contient des lama Fed.C’est comme la Fed, mais sert Llama.
Llama Fed dirige la première politique monétaire et mants de la politique de MINTS.
Ce gars est King Llama.Vous pouvez lui fournir le jeton Arweave emballé (guerre) et écrire une demande pour obtenir des jetons lama.
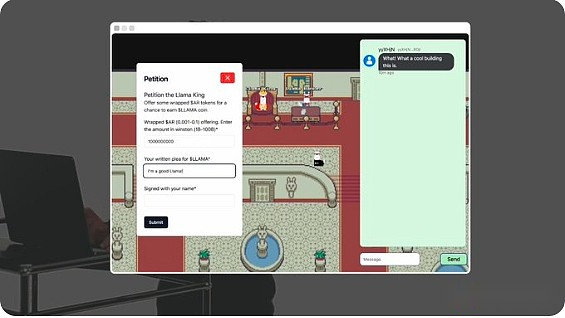
LLAMA King AI évaluera et décidera d’accorder des jetons LLAMA.La politique monétaire de Llamed est complètement autonome et n’a pas de supervision humaine.Chaque agent et chaque pièce du monde lui-même est un processus en chaîne sur AO.
Il semble que King Llama nous ait accordé des jetons et si je regarde mon portefeuille Arconnect, je peux voir qu’ils sont déjà là.bien.Llama Land n’est que le premier monde axé sur l’IA à être mis en œuvre sur AO.Il s’agit d’un cadre pour un nouveau protocole qui permet à quiconque de construire son propre monde autonome, la seule limitation est votre imagination.Tout cela est à 100% sur chaîne et n’est possible que sur AO.

Merci Elliot.Ce que vous venez de voir n’est pas seulement un modèle de langue importante participant à la prise de décision financière et à la gestion d’un système de politique monétaire autonome.Sans porte arrière, nous ne pouvons pas le contrôler, qui sont tous dirigés par l’IA lui-même.Vous voyez également un petit univers, un endroit où vous pouvez marcher dans l’espace physique, où vous pouvez aller interagir avec les infrastructures financières.Nous pensons que ce n’est pas seulement une petite démonstration intéressante.
Il y a en fait quelque chose de très intéressant ici, où différentes personnes qui utilisent des produits financiers sont réunies.Nous voyons dans l’écosystème Defi que si quelqu’un veut participer à un projet, il le vérifie d’abord sur Twitter, puis visitez le site Web et participez aux originaux de base du jeu.

Ils rejoignent ensuite un groupe télégramme ou une chaîne Discord ou parler à d’autres utilisateurs sur Twitter.Cette expérience est très décentralisée et nous sautons tous entre différentes applications.Une idée intéressante que nous essayons est de savoir si vous avez l’interface utilisateur de ces applications Defi, afin que leurs communautés puissent se réunir et gérer conjointement cet espace autonome auquel ils accèdent collectivement, car il s’agit d’une application Web permanente qui peut être rejointe par l’expérience.
Imaginez que vous pourriez aller dans un endroit qui ressemble à une maison de vente aux enchères et discuter avec d’autres utilisateurs qui aiment le protocole.Lorsqu’il y a une activité dans le processus de mécanisme financier qui se produit sur AO, vous pouvez essentiellement discuter avec d’autres utilisateurs.Les aspects communautaires et sociaux sont combinés avec la partie financière du produit.
Nous pensons que cela est très intéressant et a même un impact plus large.Ici, vous pouvez construire un agent d’IA autonome qui se promène dans ce monde d’Arweave, en interagissant avec les différentes applications et utilisateurs qu’il découvre.Donc, si vous construisez un méta-univers, lorsque vous créez un jeu en ligne, la première chose est de créer un PNJ (personnage non joueur).Ici, les PNJ peuvent être universels.
Vous avez un système intelligent qui se promène et interagit avec l’environnement, vous n’avez donc pas de problèmes de démarrage à froid.Vous pouvez avoir des agents autonomes en essayant de gagner de l’argent pour vous-même, en essayant de vous faire des amis et interagir avec l’environnement comme les utilisateurs de Defi normaux.Nous pensions que c’était très intéressant, bien qu’un peu bizarre.Nous attendrons et voir.
À l’avenir, nous voyons également des opportunités d’accélérer l’exécution du modèle de langue importante dans AO.Plus tôt, j’ai parlé du concept d’extension de l’unité informatique.C’est ainsi que nous utilisons pour construire WevevedRive.

Non seulement rester chez WevevedRive, vous pouvez créer n’importe quel type d’extension pour l’environnement informatique d’AO.Il y a un éco-project très excitant qui résout ce problème pour l’exécution accélérée GPU de modèles de grands langues, qui est le réseau APUS.Je vais les laisser expliquer.

Salut, je suis mateo.Aujourd’hui, je suis ravi de présenter APUS Network.APUS Network s’engage à construire un réseau GPU décentralisé et sans confiance.
Nous utilisons les jetons AO et APUS en tirant parti du stockage permanent sur la chaîne d’Arweave, en fournissant une extension AO open source, en fournissant un environnement d’exécution déterministe pour les GPU et en fournissant un modèle d’incitation économique pour l’IA décentralisée, en utilisant les jetons AO et APU.APUS Network utilisera les nœuds d’exploitation GPU pour rivaliser pour effectuer une formation de modèle optimale et sans confiance sur Arweave et AO.Cela garantit que les utilisateurs peuvent utiliser le meilleur modèle d’IA au prix le plus rentable.Vous pouvez nous suivre sur x (Twitter) @apus_network.Merci.

C’est la situation actuelle de l’IA sur AO aujourd’hui.Vous pouvez essayer Llama Fed et essayer de créer votre propre application de contrat intelligente en fonction des modèles de grande langue.Nous pensons que c’est le début de l’introduction de l’intelligence du marché dans un environnement d’exécution décentralisé.Nous sommes très excités à ce sujet et nous sommes impatients de voir ce qui se passera ensuite.Merci pour votre participation aujourd’hui et j’ai hâte de communiquer avec vous à nouveau.