
AIがオープンする必要がある理由
「人工知能を開く必要がある理由」について説明しましょう。私の経歴は機械学習であり、私は自分のキャリアの中で約10年間、さまざまな機械学習の仕事で働いてきました。しかし、暗号、自然言語の理解、そして近くの設立に参加する前に、私はGoogleで働いていました。現在、トランスと呼ばれる最新の人工知能のほとんどを促進するフレームワークを開発しています。Googleを離れた後、私は機械学習会社を始めて、プログラムに機械を教えることができます。これは、コンピューターとの対話方法を変えることです。しかし、2017年または2018年にはこれを行いませんでしたが、早すぎて、その時点でこれを行うコンピューティングの能力とデータはありませんでした。

当時私たちがしたことは、世界中の人々を引き付けて、私たち、ほとんどが学生のためにデータをラベル付けする仕事をすることでした。彼らは中国、アジア、東ヨーロッパにいます。それらの多くは、これらの国に銀行口座を持っていません。米国は簡単にお金を送る気がないので、私たちは問題の解決策としてブロックチェーンを使用したいと考え始めました。私たちは、これを簡単にするために、どこにいても、世界中の人々にプログラム的な方法で支払いたいと思っています。ちなみに、Cryptoの現在の課題は、現在多くの問題を解決していますが、通常、このプロセスを獲得するために最初にCryptoを購入する必要があります。
企業のように、彼らは、まず第一に、あなたはそれを使用するために会社のエクイティを購入する必要があると言うでしょう。これは、私たちが近づく多くの問題の1つです。それでは、人工知能の側面について少し詳細に説明しましょう。言語モデルは新しいものではなく、1950年代に存在しました。これは、自然言語ツールで広く使用されている統計ツールです。2013年に始まった長い間、深い学習が再起動されるにつれて、新しい革新が始まりました。この革新は、単語を一致させ、それらを多次元ベクトルに追加し、それらを数学的な形式に変換できることです。これは、ディープラーニングモデルでうまく機能します。これらは、マトリックスの乗算と活性化機能の多くです。

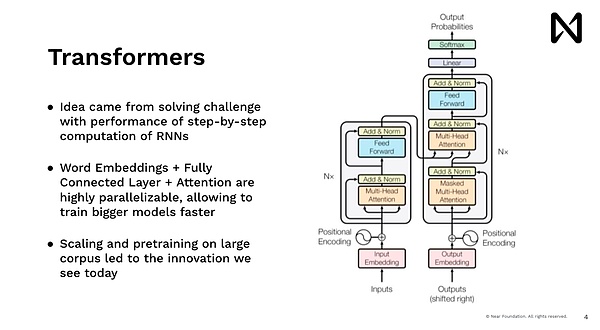
これにより、高度な深い学習を開始し、モデルを訓練して楽しいことをすることができます。今振り返ってみると、当時私たちがやっていたのはニューロンのニューラルネットワークであり、これは主に人間のモデルを模倣しており、一度に一言も読むことができました。だから、これを行うのは非常に遅いです。Google.comでユーザーにコンテンツを表示しようとすると、回答をする5分前にWikipediaを読むのを待つ人はいませんが、すぐに答えを取得したいと思います。したがって、Transformersモデル、つまりChatGpt、Midjourney、およびすべての最近の進捗を促進するモデルは、同じアイデアから来ており、データを並行して処理し、すぐに回答を行う方法があることを期待しています。
したがって、ここでのこのアイデアの主要な革新は、すべての単語、すべてのトークン、すべての画像ブロックが並行して処理され、GPUおよびその他のアクセラレータが非常に並列コンピューティングパワーを活用していることです。そうすることで、私たちはそれについて規模で推論することができます。このスケールは、トレーニングスケールをスケールアップするため、自動トレーニングデータを処理できます。その後、ドーパミンは、爆発的なトレーニングを達成し、短時間で驚くべき仕事をしました。それは大量のテキストを持っており、世界の言語を推論と理解して驚くべき結果を達成し始めます。
現在の方向性は、以前はデータサイエンティストと機械学習エンジニアが使用するツールであった革新的な人工知能を加速し、その後、製品に何があるか、または意思決定者とデータについて話し合うことができるツールでした。これで、このモデルのAIが人々と直接通信しています。モデルが実際に製品の背後に隠れているため、モデルと通信していることを知らないかもしれません。そこで、私たちは、AIが以前にどのように機能したかを理解していた人々から、それを理解し、使用できるようになった人々からこの変化を経験しました。

だから、私はあなたにいくつかの背景を与えるためにここにいます。私たちがGPUを使用してモデルをトレーニングしていると言うとき、これはデスクトップでビデオゲームをプレイするときに使用する種類のGPUではありません。

通常、各マシンには8つのGPUが装備されており、そのすべてがマザーボードを介して互いに接続され、それぞれが約16台のマシンを備えたラックに積み重ねられています。これらのラックはすべて、専用のネットワークケーブルを介して互いに接続されており、情報をGPU間で直接かつ迅速に送信できるようにします。したがって、情報はCPUには適していません。実際、CPUでそれを扱うことはありません。すべての計算はGPUで発生します。したがって、これはスーパーコンピューターのセットアップです。繰り返しますが、これは伝統的な「ねえ、これはGPUのこと」ではありません。したがって、GPU4のスケールを備えたモデルは、約3か月でトレーニングに10,000 H100を使用し、コストは6400万ドルでした。誰もが現在のコストが何であるか、そしていくつかの最新のモデルを訓練するのにどれくらいの費用がかかるかを知っています。
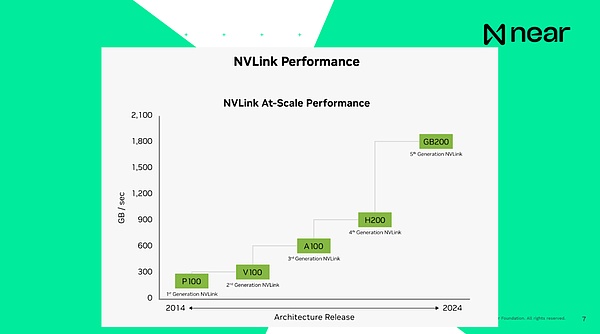
重要なのは、システムが互いに接続されていると言うと、H100の現在の接続速度、つまり前世代の製品は1秒あたり900GBであり、コンピューター内のCPUとRAMの間の接続速度は200GBであることです。 1秒間、これはすべてコンピューターです。したがって、同じデータセンターであるGPUから別のGPUにデータを送信すると、コンピューターよりも高速になります。お使いのコンピューターは基本的にボックス内で独自に通信できます。新世代の製品の接続速度は、基本的に1秒あたり1.8TBです。開発者の観点から見ると、これは個別のコンピューティングユニットではありません。これらは、非常に大規模なコンピューティングを提供する巨大なメモリとコンピューティングパワーを持つスーパーコンピューターです。
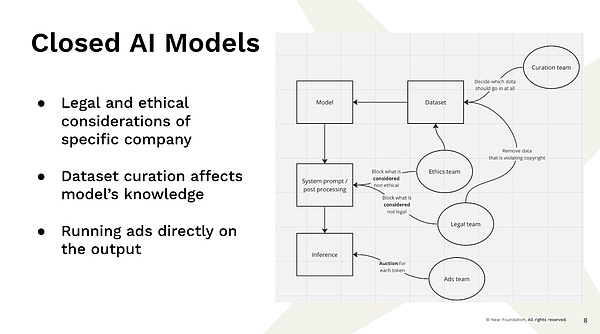
今、これは私たちが直面している問題につながります。これらの大企業には、現在そのようなサービスを提供しているこれらのモデルを構築するリソースと能力があり、そこにどれだけの仕事があるかわかりません、 右?これは例ですよね?完全に集中型の会社プロバイダーに行き、クエリを入力します。その結果、ソフトウェアエンジニアリングチームではなく、結果の表示方法を決定するチームがいくつかありますよね?どのデータがデータセットに入るかを決定するチームがあります。
たとえば、インターネットからデータをクロールするだけの場合、バラクオバマがケニアで生まれ、バラクオバマがハワイで生まれたことは、人々が論争について推測したいのでまったく同じです。したがって、何を訓練するかを決める必要があります。あなたはそれが真実であると信じていないので、いくつかの情報を除外することを決定する必要があります。したがって、このような個人がどのデータが採用され、そのデータが存在するかを決定した場合、これらの決定は主にそれらを作成した人の影響を受けます。どのコンテンツが著作権で保護されているか、何が違法であるかを見ることができないと判断する法務チームがあります。私たちには、不道徳なものと見せないものを決定する「倫理的チーム」があります。
したがって、ある程度、そのようなフィルタリングと操作の行動がたくさんあります。これらのモデルは統計モデルです。それらはデータから選択されます。データに何もない場合、彼らは答えを知りません。データに何かがある場合、彼らはおそらくそれを事実として扱うでしょう。今、あなたがAIから答えを得たとき、これは心配するかもしれません。右。今、あなたはモデルから答えを得るべきですが、保証はありません。結果がどのように生成されるかわかりません。企業は、特定のセッションを最高入札者に販売して、実際に結果を変更する場合があります。どの車を購入すべきか尋ねると、トヨタはトヨタに偏っているべきだと思うことに決め、トヨタはこれを行うために10セントを支払うことを決めました。

したがって、これらのモデルをニュートラルでデータを表すべき知識ベースとして使用したとしても、実際には、結果を非常に具体的な方法でバイアスする前に多くのことがあります。これは多くの問題を引き起こしましたよね?これは基本的に、大企業とメディアの間の異なる法的訴訟の1週間です。SEC、今ではほとんどすべての人がお互いを訴えようとしています。なぜなら、これらのモデルは非常に多くの不確実性と力をもたらしているからです。そして、あなたが楽しみにしているなら、問題は、大手ハイテク企業が常に彼らの収益を増やし続ける動機を持っているということですよね?たとえば、あなたが公開会社である場合、収益を報告する必要があり、成長を続ける必要があります。
これを達成するために、既にターゲット市場を占有している場合、たとえば、すでに20億人のユーザーがいます。インターネットにはこれ以上の新しいユーザーはいません。平均収益を最大化する以外に多くの選択肢はありません。つまり、ユーザーからより多くの価値を抽出する必要があり、それらはほとんど価値がない場合があります。または、動作を変更する必要があります。生成AIは、特にすべての知的知性の形で来ると人々が考える場合、ユーザーの行動を操作して変化させるのに非常に優れています。そのため、規制上の圧力が高く、規制当局がこのテクノロジーがどのように機能するかを完全に理解していないこの非常に危険な状況に直面しています。ユーザーを操作から保護することはほとんどありません。

操作的なコンテンツ、誤解を招くコンテンツは、広告がなくても、何かのスクリーンショットを撮り、タイトルを変更し、Twitterに投稿するだけで、人々は夢中になります。あなたはあなたの収入を継続的に最大化する原因となる経済的インセンティブメカニズムを持っています。そして、それは実際にあなたがグーグル内で邪悪なことをしているようではありませんよね?どのモデルを開始するかを決定すると、AまたはBテストを実行して、どのモデルがより多くの収益をもたらすかを確認します。そのため、ユーザーからより多くの価値を抽出することにより、収益を継続的に最大化します。さらに、ユーザーとコミュニティは、モデルのコンテンツ、使用されたデータ、および実際に達成しようとした目標に関する情報を持っていません。これは、アプリケーションユーザーの場合です。これは一種の調整です。
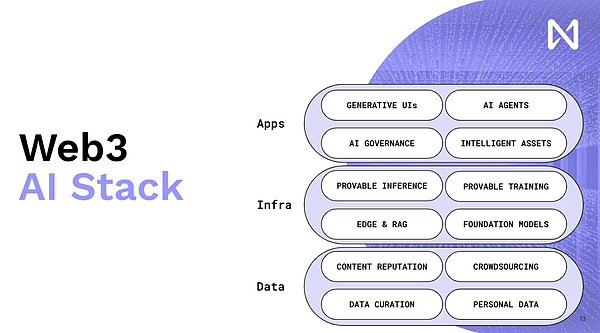
これが、Web 3とAIの統合を常に促進している理由です。これは、Web 3 AIの一般的な方向性です。詳細を理解するために、最初の部分について簡単に説明します。

繰り返しますが、これは純粋にAIの問題ではありませんが、言語モデルは大きな影響力をもたらし、人々が情報を操作して利用するために拡大しました。あなたが望むのは、さまざまなコンテンツを見ると現れる、追跡可能で追跡可能な暗号の評判です。ですから、実際に暗号化され、各Webサイトのすべてのページにあるコミュニティノードがいくつかあると想像してください。これを超えると、これらのモデルがほとんどすべてを読み取り、パーソナライズされた概要とパーソナライズされた出力を提供するため、これらの流通プラットフォームはすべて中断されます。
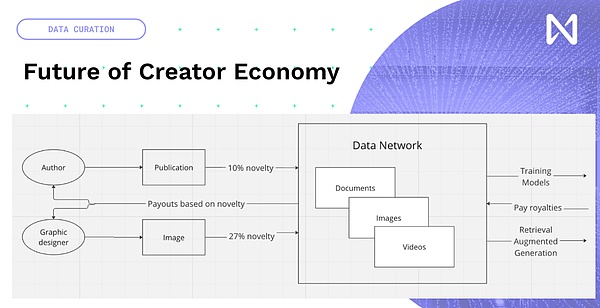
そのため、実際に新しいクリエイティブコンテンツを作成する代わりに、新しいクリエイティブコンテンツを作成する機会があります。既存のコンテンツにブロックチェーンとNFTを追加しましょう。モデルトレーニングと推論時間に関する新しいクリエイターの経済、新しい出版物、写真、YouTube、音楽など、人々が作成するデータは、モデルトレーニングに貢献する量に基づいてネットワークに入ります。したがって、これに基づいて、コンテンツに基づいてグローバルにいくらかの補償を得ることができます。そのため、現在、広告ネットワークによって推進されている人目を引く経済モデルから、革新的で興味深い情報を真にもたらすものに移行しています。
私が言及したい重要なことの1つは、多くの不確実性が浮遊点操作から来ているということです。これらのモデルはすべて、多くの浮動小数点操作と乗算が含まれます。これらはすべて不確実な操作です。
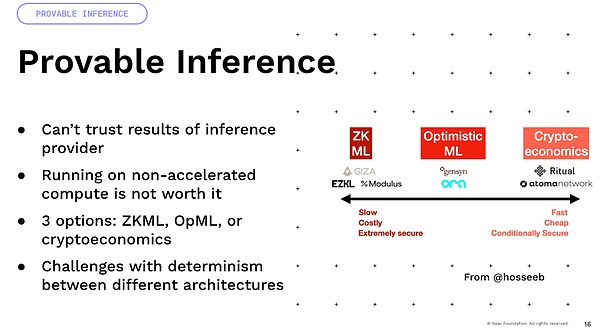
これで、さまざまなアーキテクチャのGPUでそれらを掛けている場合。したがって、A100とH100を服用すると、結果は異なります。したがって、暗号経済や楽観主義など、確実性に依存する多くの方法は、実際に多くの困難に遭遇し、これを達成するために多くの革新が必要です。最後に、プログラム可能な通貨とプログラム可能な資産を構築しているという興味深い考えがありますが、このインテリジェンスを追加することを想像できれば、コードによって定義されていないスマート資産を持つことができます。自然言語が世界と対話する能力ですよね?これは、多くの興味深い収益の最適化と債務を抱える方法であり、世界で取引戦略を実施することができます。

現在の課題は、現在のすべてのイベントが強力な堅牢な行動を持っていないことです。トレーニングの目的は次のトークンを予測することであるため、彼らは敵対的に強力になるように訓練されていません。そのため、モデルにすべてのお金を与えるように説得する方が簡単になります。先に進む前に、この問題を解決することは実際に非常に重要です。だから私はあなたにこの考えを残します、私たちは岐路に立っていますよね?極端なインセンティブとフライホイールを備えた閉鎖されたAIエコシステムがあります。なぜなら、製品を発売すると、多くの収益を生み出し、その収益を建設製品に入れるからです。ただし、この製品は、会社の収益を最大化するために生まれ、ユーザーから抽出された価値を最大化します。または、このオープンなユーザー所有の方法があり、ユーザーは状況を制御します。

これらのモデルは実際にあなたにとって良いものであり、あなたの興味を最大化しようとしています。彼らはあなたにインターネット上の多くの危険からあなたを真に守る方法を提供します。そのため、より多くの開発とアプリケーションにAI X Cryptoが必要です。みなさん、ありがとうございます。







