作者:Arweave 來源:X, @ArweaveOasis
Arweave Ecosystem 自 2018 年啟動以來,一直被認為是去中心化存儲賽道中最具價值的網絡之一。但轉眼 5 年,由於它的技術主導屬性,很多人對 Arweave/AR 是既熟悉又陌生。本文就從回顧 Arweave 自成立以來的技術發展歷史入手,以增進大家對 Arweave 的深入理解。
Arweave 在 5 年內共經歷了十餘次主要的技術升級,其主要迭代的核心目標就是從一個計算主導的挖礦機制轉變為由存儲主導的挖礦機制。
Arweave 1.5:主網啟動
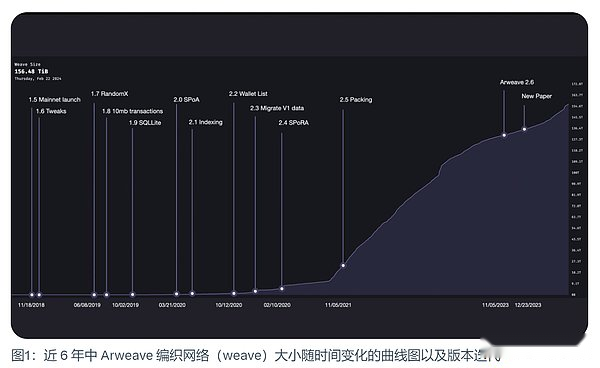
Arweave 主網在 2018 年 11 月 18 日啟動。當時的編織網絡大小僅有 177 MiB。早期的 Arweave 在某些方面與現在類似,2 分鐘的出塊時間,每個區塊可容納的上限為 1000 筆。除此之外,更多的是不同的方面,如每筆交易的大小限制僅有 5.8 MiB。並且它使用了一種名為訪問證明(Proof of Access)的挖礦機制。
那問題來了,什麼是訪問證明(PoA)呢?
簡單說,是為了生成新的區塊,礦工必須證明他們可以訪問區塊鏈歷史中的其他區塊。所以訪問證明會從鏈上隨機選擇一個歷史區塊,要求礦工將那個歷史區塊作為一個回溯塊(Recall Block)放進他們試圖生成的當前區塊中。而這將是這個回溯塊的完整備份。
當時的想法是礦工們不必存儲所有區塊,只要他們能證明可以訪問這些區塊,就可以參與挖礦競爭。(Dmac 在他的視頻中用賽車比賽作比喻便於理解,這裡引用過來。)
首先這場比賽有一個終點線,這個終點線會隨著參與者的數量或挖礦速度而移動,以確保比賽總是在大約兩分鐘內結束。這就是兩分鐘區塊時間的原因。
其次,這個比賽分為兩部分。
·第一部分,可以稱為資格賽,礦工們必須證明他們可以訪問歷史區塊。一旦手中有了指定區塊,就可以進入決賽。如果礦工沒有存儲區塊,沒關係,他們還可以從同行那裡訪問它,同樣可以加入比賽。
·第二部分,相當於資格賽後的決賽,這部分就是純粹以工作量證明的方式使用哈希計算能力來挖礦,實質上就是消耗能源來計算哈希並最終贏得比賽。
一旦一個礦工越過了終點線,比賽結束,下一場比賽開始。而挖礦獎勵都歸一個贏家所有,這便使得挖礦變得異常激烈。因此,Arweave 開始快速增長。

Arweave 1.7:RandomX
早期的 Arweave 原理是一個非常簡單易懂的機制,但沒過多久,研究人員就意識到可能會出現的一個不良結果。即礦工可能會採取一些對網絡不利的策略,我們稱其為墮落策略。
主要是因為,有些礦工在沒有存儲指定快速訪問區塊時,就必須去訪問別人的區塊,這使得他們比存儲了區塊的礦工慢了一步,輸在了起跑線上。但解決方案也很簡單,只要大量堆疊 GPU ,通過大算力、消耗大量能源就能彌補這個缺陷,因此,他們甚至可以超過那些存儲區塊並保持快速訪問的礦工。如果這種策略成為了主流,礦工將不再存儲和分享區塊,取而代之的是不斷優化算力設備,消耗大量能量來獲得競爭的勝利。最終結果就會變成網絡的實用性大幅下降,數據逐漸變得中心化。這對於存儲網絡來說,顯然是一種墮落的背離。
為了解決這個問題,Arweave 1.7 版本出現了。
這個版本最大的特點是引入了一種叫 RandomX 的機制。它是一個在 GPU 或 ASIC 設備上運行非常困難的哈希公式,這使得礦工們放棄堆疊 GPU 算力,只採用通用 CPU 來參加哈希算力的競賽。
Arweave 1.8/1.9:10 MiB 交易大小與 SQL lite
對礦工而言,除了證明他們有訪問歷史區塊的能力外,還有更重要的事項需要處理,那就是對用戶向 Arweave 發布的交易進行處理。
所有新的用戶交易數據都必須被打包進新區塊中,這是對一條公鏈最起碼的要求。在 Arweave 網絡中,當一個用戶向一個礦工提交一條交易數據時,這個礦工不僅會將數據打包進自己即將提交的區塊中,還會將它分享給其它礦工,以此讓所有礦工都能將這條交易數據打包進各自即將提交的區塊中。他們為什麼要這樣做呢?這裡至少有兩個原因:
·他們在經濟上被激勵去這樣做,因為每個包含在區塊中的交易數據會增加該區塊的獎勵。礦工們互相分享交易數據,能確保無論誰贏得出塊權,都能得到最大的獎勵。
·防止網絡發展的死亡螺旋。如果用戶的交易數據時常會不被打包進區塊,那用戶就會越來越少,網絡就失去了它的價值,礦工的收益也會變少,這是所有人都不願意看到的。
所以礦工選擇以這種互惠互利的方式來最大化自己的利益。但這又帶來了數據傳輸上的一個難題,它成為網絡可擴展性的瓶頸。交易越多,區塊越大,而 5.8 MiB的交易限制也沒有起到作用。因此,Arweave 通過硬分叉,將交易大小增加至 10 MiB,從而獲得了一些緩解。
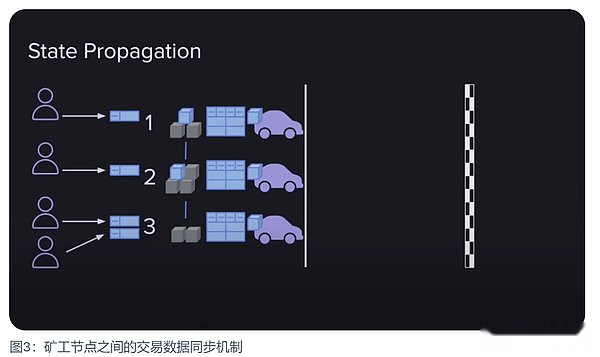
但即便如此,傳輸瓶頸的問題仍然沒有得到解決。Arweave 是一個全球分布的礦工網絡,所有礦工都需要同步狀態。而且每個礦工的速度連接也都不同,這讓網絡出現了平均連接速度。為了讓該網絡每兩分鐘產生一個新的區塊,連接速度就需要足夠上傳希望在這兩分鐘內存儲的所有數據。如果用戶上傳的數據超過了網絡的平均連接速度,就會導致擁堵,降低網絡的效用。這會成為 Arweave 發展的絆腳石。所以,後續 1.9 的更新版本為提高網絡的性能使用了 SQL lite 等基礎設施。
Arweave 2.0:SPoA
2020 年 3 月,Arweave 2.0 的更新為網絡引入了兩個重要更新,也因此解除了網絡可擴展性的枷鎖,並打破了在 Arweave 上存儲數據的能力極限。
第一個更新是簡潔的證明(Succinct Proof)。這是基於默克爾樹加密結構所構建的,它使礦工能夠通過提供一個簡單的默克爾樹化的壓縮分支路徑,來證明他們存儲了一個塊中的所有字節。它所帶來的改變是,礦工們只需要把一個不到 1 KiB 的簡潔證明打包進塊中即可,不再需要打包一個可能有 10 GiB 的回溯塊。
第二個更新是「格式 2 交易」。這個版本對交易的格式進行了優化,其目的是為了給節點間分享的數據傳輸塊瘦身。相對於「格式 1 交易」需要把交易的頭與數據同時加入塊中的模式,「格式 2 交易」則允許將交易頭和數據分開,也就是在礦工節點之間的塊信息數據共享傳輸中,除回溯塊簡潔證明之外,所有交易都只需要將交易頭加入塊中,交易數據可以在競賽結束後再添加至塊中。這將大大降低礦工節點之間同步區塊內交易時的傳輸要求。
這些更新的結果是它創建了比過去更輕、更容易傳輸的區塊,釋放了網絡中的過剩帶寬。礦工們此時會使用這些過剩帶寬來傳輸「格式 2 交易」的數據,因為這些數據在未來將會成為回溯塊。因此,可擴展性問題被解決了。
Arweave 2.4:SPoRA
到目前為止,Arweave 網絡中的所有問題都解決了嗎?答案是顯然沒有。另一個問題又因新的 SPoA 機制而衍生出來。
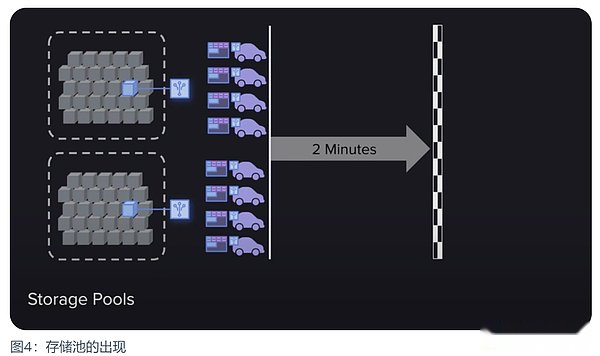
與礦工堆疊 GPU 算力類似的挖礦策略又出現了。這次雖然不是 GPU 堆疊的算力中心化問題,但帶來一種可能更以計算為中心的主流策略。那就是快速訪問存儲池的出現。所有歷史區塊都被存在這些存儲池中,當存取證明生成一個隨機的回溯塊時,它們可以快速生成證明,然後在礦工之間以極快的速度同步。
這雖然看起來沒有多大問題,數據在這樣的策略中還是可以得到足夠多的備份與存儲。但問題是這種策略會潛移默化地轉變礦工的關注點,礦工不再有動力獲得對數據的高速訪問,因為現在傳輸證明變得非常容易且快速,所以他們會將大部分精力投入到工作量證明的哈希運算中,而不是數據存儲。這難道不是另一種形式的墮落策略嗎?
於是,Arweave 在經歷了數次功能升級後,如數據索引迭代(Indexing),錢包列表壓縮(Wallet List),V1 版交易數據遷移等。終於迎來了又一次大版本的迭代 —— SPoRA,隨機訪問的簡潔證明。
SPoRA 真正將 Arweave 引入到了全新的時代,通過機制迭代讓礦工的注意力從哈希計算轉到了數據存儲上。
那麼,隨機訪問的簡潔證明有什麼不同呢?
它首先有兩個先決條件,
·經過索引的數據集(Indexed Dataset)。得益於 2.1 版本中迭代的 Indexing 功能,它用全局偏移量為編織網絡中的每個數據塊(Chunk)作了標記,以便每個數據塊都可以通過這個全局偏移量來快速訪問。這就帶來了 SPoRA 的核心機制 —— 數據塊的連續檢索。 值得提醒的是這裡提到的數據塊(Chunk)是大文件經過分割後的最小數據單元,其大小為 256 KiB。並不是區塊 Block 的概念。
·慢哈希(Slow Hash)。這種哈希用於隨機地選出備選數據塊(Candidate Chunk)。得益於 1.7 版本引入的 RandomX 算法,礦工無法使用算力堆疊的方式搶跑,只能使用 CPU 進行計算。
基於這兩個先決條件,SPoRA 機制有 4 個步驟
第一步,生成一個隨機數,並用該隨機數與前區塊信息通過 RandomX 生成一個慢哈希;
第二步,使用這個慢哈希計算出一個唯一的回溯字節(Recall Byte 即數據塊的全局偏移量);
第三步,礦工用這個回溯字節從自己的存儲空間中尋找相對應的數據塊。如果礦工沒有存儲該數據塊,則返回到第一步重新開始;
第四步,用第一步生成的慢哈希與剛找到的數據塊進行一次快哈希;
第五步,如果計算出的哈希結果大於當前的挖礦難度值,則完成塊的挖掘與分發。反之則回到第一步重新開始。
所以從這裡可以看到,這極大地激勵了礦工們儘可能多地將數據存儲在能夠通過非常快的總線連接到他們的 CPU 的硬碟上,而不是在遠在天邊的存儲池中。完成將挖礦策略從計算導向扭轉為存儲導向。
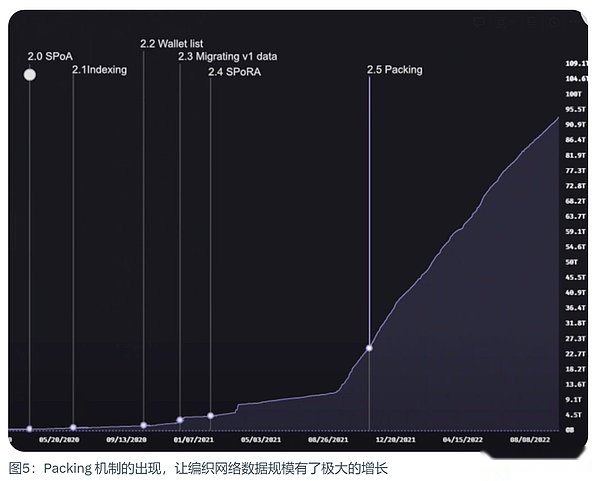
Arweave 2.5:Packing 和數據暴增
SPoRA 讓礦工都開始瘋狂地存儲數據,因為這是改善挖礦效率的最低懸的果實。那接下來發生什麼事情呢?
一些聰明的礦工意識到這種機制下的瓶頸實際上是能多快從硬碟驅動器獲取數據。從硬碟獲取的數據塊越多,能計算的簡潔證明就越多,能執行的哈希操作就越多,挖到礦的機率就越高。
所以如果當礦工在硬碟驅動器上花費了十倍成本,比如使用了讀寫速度更快的 SSD 來存儲數據,那這位礦工所擁有的哈希能力就會高十倍。當然這也會出現類似 GPU 算力的軍備競賽。比 SSD 更快的存儲形式,比如 RAM 驅動器這種更快傳輸速度的奇特存儲形式也會隨之出現。不過這完全取決於投入產出比。
現在,礦工能生成哈希的最快速度就是一個 SSD 硬碟的讀寫速度,這為類似 PoW 模式的能源消耗設定了一個較低的上限,從而更加環保。
這樣就完美了嗎? 當然還不是。技術人員們認為還可以在此基礎上做得更好。
為了能有更大數據量的上傳,Arweave 2.5 引入了數據捆綁包機制。這雖然不是一次真正意義上的協議升級,但它一直都是可擴展性計劃中的一個重要部分,它讓網絡的大小得到了爆炸性的增長。因為它突破了我們在開始時談到的每個區塊 1000 筆交易的上限。數據捆綁包只佔用了這 1000 筆交易中的一筆而已。這為 Arweave 2.6 打下了基礎。
Arweave 2.6
Arweave 2.6 是自 SPoRA 之後的一次重大版本升級。它在此前的基礎上又向自己的願景邁進了一步,讓 Arweave 挖礦變得更加低成本以此來促進更加去中心化的礦工分布。
那它具體有什麼不同?由於篇幅問題,這裡只作簡單的介紹,未來會更加具體地專門解讀 Arweave 2.6 的機制設計。
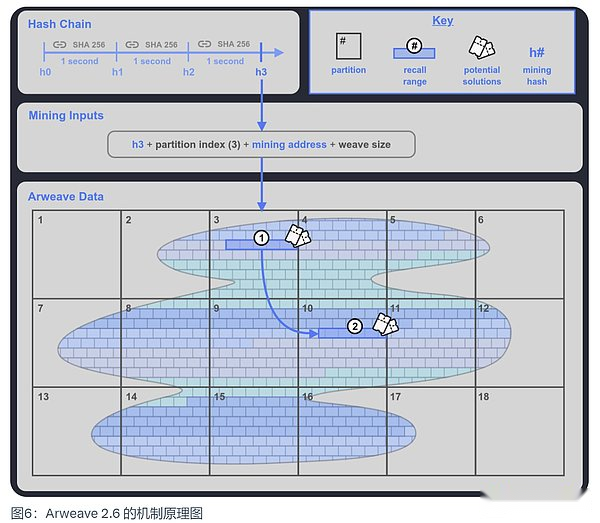
簡單理解,Arweave 2.6 就是 SPoRA 的限速版本,它為 SPoRA 引入了一個可以每秒鐘滴答一次的可驗證加密時鐘,我們稱其為哈希鏈(Hash Chain)。
·它每滴答一次就會產生一個挖礦哈希(Mining Hash),
·礦工選擇一個他們存儲的數據分區的索引來參與挖礦,
·結合這個挖礦哈希與分區索引,可以在礦工選定的已存儲數據分區中生成一個回溯範圍,這個回溯範圍包括了 400 個回溯塊,這些就是礦工可以用來挖礦的回溯塊。除了這個回溯範圍之外,還會再隨機在編織網絡(Weave)中再生成一個回溯範圍 2,如果礦工存儲了足夠多的數據分區,就能夠獲得這個範圍 2,也就是另外的 400 個回溯塊挖礦機會,以此來增加最終勝出的機率。這就很好地激勵了礦工去存儲足夠多的數據分區的副本。
·礦工挨個使用回溯範圍內的數據塊進行測試,如果結果大於當前給定網絡難度即贏得挖礦權利,如果沒有滿足,則使用下一個數據塊測試。
這就意味著每秒鐘將會產生的最大哈希數量是固定的,2.6 版本將這個數量控制在普通機械硬碟性能也能處理的範圍之內。這讓原本基於 SSD 硬碟驅動器最大速度能高達每秒數千或數十萬次哈希的能力變成了擺設,只能以每秒幾百個哈希的速度與機械硬碟同臺競技。這就好比一輛蘭博基尼與一輛豐田普銳斯在一場限速是 60 公裡每小時的比賽中競爭,蘭博基尼的優勢在極大程度上被限制住了。所以,現在對挖礦性能貢獻最大的是礦工存儲數據集的數量。
以上是 Arweave 在發展歷程中的一些重要迭代裡程碑。從 PoA 到 SPoA 到 SPoRA 再到 Arweave 2.6 的限速版 SPoRA,始終遵循著原初的願景。2023 年 12 月 26 日,Arweave 官方又發布了 2.7 版本白皮書,在這些機制的基礎上又作了很大調整,將共識機制進化到了 SPoRes 簡潔的複製證明。