
著者:YBB Capital Zeke
序文
2月16日に、Openaiは最新のテキスト制御ビデオ生成拡散モデル「SORA」を発表しました。これは、複数のセグメントでカバーされている幅広い視覚データ型の高品質な生成のビデオを通じて生成AIの別のマイルストーンを示しています。Pikaとは異なり、AIビデオ生成ツールは、複数の画像で数秒間ビデオを生成する状態にあります。さらに、このモデルは、物理的な世界とデジタルの世界をシミュレートする能力も反映しています。
建設方法の観点から、SORAはGPTモデル「ソースデータトランスフォーマル拡散 – 発光」の以前の技術パスを継続しました。つまり、その開発と成熟度はエンジンとしてのコンピューティングパワーも必要であり、必要なデータの量であり、ビデオトレーニングはテキストのそれよりもはるかに大きいです。トレーニングされたデータの量は、コンピューティングパワーの需要をさらに高めます。ただし、初期の記事「人気トラックプレビュー:分散化コンピューティングパワー市場」でAI時代におけるコンピューティングパワーの重要性についてすでに議論しており、最近のAIの人気が高まっているため、すでに多数のコンピューティングパワーがあります。市場でのプロジェクトが出現し始めています。Depinに加えて、Web3とAIの織り織りはどのような火花が衝突する可能性がありますか?このトラックには他にどのような機会が含まれていますか?この記事の主な目的は、過去の記事を更新および完了し、AI時代のWeb3の可能性について考えることです。
AI開発の歴史における3つの主要な方向
人工知能は、人間の知能をシミュレート、拡大、強化するために設計された新興科学と技術です。1950年代と1960年代の誕生以来、人工知能は、半世紀以上の発展の後、社会生活とすべての人生の変化を促進する重要な技術となっています。このプロセスでは、象徴性、つながり、行動主義の3つの研究方向の織り間発展が、今日のAIの急速な発展の基礎となっています。
象徴性
論理的またはルール主義としても知られているため、シンボルを処理することで人間の知性をシミュレートすることが可能であると考えられています。この方法は、シンボルを使用して、問題領域内のオブジェクト、概念、およびそれらの相互関係を表現および操作し、論理的推論を使用して問題を解決します。象徴性の中心的な見方は、シンボルが現実世界の高度な抽象化を表すシンボルの操作と論理的推論を通じて、インテリジェントな行動を達成できることです。
コネクショニズム
または、人間の脳の構造と機能を模倣することにより、知性を実現するように設計されたニューラルネットワーク手法。この方法により、多数の単純な処理ユニット(ニューロンなど)のネットワークを構築し、これらのユニット間(シナプスなど)間の接続の強度を調整することにより、学習を可能にします。Connectionismは、データから学習し、一般化する能力を強調し、パターン認識、分類、および継続的な入力および出力マッピングの問題に特に適しています。コネクティック主義の発達としての深い学習は、画像認識、音声認識、自然言語処理などの分野でブレークスルーを行いました。
行動主義
行動主義は、バイオニックロボット工学と自律的なインテリジェントシステムの研究と密接に関連しており、エージェントが環境との相互作用を通じて学習できることを強調しています。最初の2つとは異なり、行動主義は内部表現や思考プロセスのシミュレーションに焦点を当てていませんが、知覚と行動のサイクルを通じて適応行動を達成します。行動主義は、環境との動的な相互作用と学習を通じてインテリジェンスが明らかにされると考えています。これは、複雑で予測不可能な環境でのアクションを必要とするモバイルロボットと適応制御システムに適用する場合に特に効果的です。
これら3つの研究方向には本質的な違いがありますが、実際のAIの研究と応用に相互作用して統合して、AI分野の開発を共同で促進することもできます。
AIGC原理の概要
現在、爆発的な発達を受けている人工知能生成コンテンツ(AIGC)は、結合性の進化と応用です。これらのモデルは、データに存在する基礎となる構造、関係、パターンを学習するために、大きなデータセットと深い学習アルゴリズムを使用してトレーニングされています。画像、ビデオ、コード、音楽、デザイン、翻訳、質問の回答、テキストなど、ユーザーの入力プロンプトに基づいて、斬新でユニークな出力結果を生成します。現在のAIGCは、基本的に、ディープラーニング(DL)、ビッグデータ、および大規模なコンピューティングパワーの3つの要素で構成されています。
深い学習
ディープラーニングは機械学習(ML)のサブフィールドであり、ディープラーニングアルゴリズムは、人間の脳に従ってモデル化されたニューラルネットワークです。たとえば、人間の脳には、情報を学習および処理するために協力する何百万もの相互に関連するニューロンが含まれています。同様に、深い学習ニューラルネットワーク(または人工ニューラルネットワーク)は、コンピューター内で一緒に働く多層的な人工ニューロンで構成されています。人工ニューロンは、数学的計算を使用してデータを処理するノードと呼ばれるソフトウェアモジュールです。人工ニューラルネットワークは、これらのノードを使用して複雑な問題を解決する深い学習アルゴリズムです。
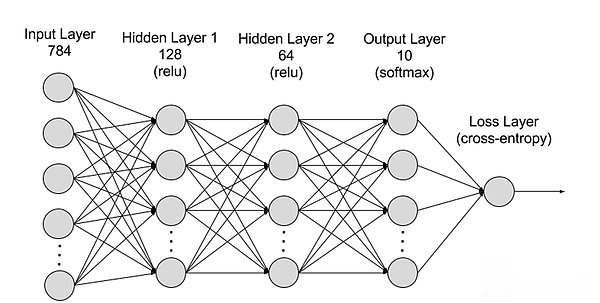
ニューラルネットワークを階層から分割すると、入力層、隠れ層、出力層に分割でき、パラメーターは異なる層間で接続されます。
-
入力レイヤー:入力層は、外部入力データの受信を担当するニューラルネットワークの最初のレイヤーです。入力層の各ニューロンは、入力データの特徴に対応します。たとえば、画像データを処理する場合、各ニューロンは画像のピクセル値に対応する場合があります。
-
隠されたレイヤー:入力層はデータを処理し、ニューラルネットワークのさらなるレイヤーに渡します。これらの隠されたレイヤーは、さまざまなレベルで情報を処理し、新しい情報を受信するときに動作を調整します。ディープラーニングネットワークには、複数の異なる角度からの問題を分析するために使用できる数百の隠れレイヤーがあります。たとえば、分類しなければならない未知の動物のイメージを取得した場合、すでに知っている動物と比較できます。たとえば、これが耳の形、脚の数、生徒のサイズに基づいて、これがどの動物であるかを判断できます。深いニューラルネットワークの隠れ層も同じように機能します。深い学習アルゴリズムが動物の画像を分類しようとする場合、その隠された層はそれぞれ動物のさまざまな特徴を処理し、それらを正確に分類しようとします。
-
出力層:出力層は、ネットワークの出力の生成を担当するニューラルネットワークの最後の層です。出力層の各ニューロンは、可能な出力カテゴリまたは値を表します。たとえば、分類問題では、各出力層ニューロンはカテゴリに対応する場合がありますが、回帰問題では、出力層には予測結果を表す値が1つしかない場合があります。
-
パラメーター:ニューラルネットワークでは、異なるレイヤー間の接続は、ネットワークがデータのパターンを正確に識別して予測を行うことができるように、トレーニング中に最適化された重みとバイアスパラメーターで表されます。パラメーターの増加は、ニューラルネットワークのモデル容量、つまり、データの複雑なパターンを学習して表現するモデルの能力を高める可能性があります。しかし、パラメーターの対応する増加により、コンピューティングパワーの需要が増加します。
ビッグデータ
効果的なトレーニングのために、ニューラルネットワークには通常、大規模で多様な、高品質でマルチソースデータが必要です。これは、機械学習モデルのトレーニングと検証の基礎です。ビッグデータを分析することにより、機械学習モデルは、データのパターンと関係を学習して、予測または分類を行うことができます。
大規模なコンピューティングパワー
ニューラルネットワークの多層複雑な構造、多数のパラメーター、ビッグデータ処理要件、反復トレーニング方法(トレーニング段階では、モデルは繰り返し反復する必要があり、トレーニングプロセス中に、伝播してバックプロパゲートする必要がありますアクティベーション関数を含む各計算の層は、損失関数の計算、勾配の計算と重みの更新、高精度計算の要件、並列計算能力、最適化と正規化技術、モデルの評価と検証プロセスが導きました。高いコンピューティングパワーの需要に。

ソラ
Openaiの最新のビデオジェネレーションAIモデルとして、SORAは、多様な視覚データを処理および理解する人工知能の能力の大きな進歩を表しています。ビデオ圧縮ネットワークと時空のパッチテクノロジーを採用することにより、SORAは世界中のさまざまなデバイスから撮影された大規模な視覚データを統一された形式の表現形式に変換することができ、複雑な視覚コンテンツの効率的な処理と理解を達成できます。テキスト条件付けされた拡散モデルに依存して、SORAはテキストプロンプトに基づいて非常にマッチしたビデオまたは写真を生成し、非常に高い創造性と適応性を示します。
ただし、ビデオ生成におけるソラのブレークスルーと実際の相互作用のシミュレーションにもかかわらず、物理的な世界シミュレーションの精度、長いビデオ生成の一貫性、複雑なテキスト命令の理解、トレーニングと生成の効率など、いくつかの制限に直面しています。本質的に、ソラは、Openaiの独占コンピューティングパワーとファーストモーバーのアドバンテージを通じて、「ビッグデータトランスフォーション – エマージェンス」の古い技術的なパスを継続し、他のAI企業がまだ追い越されています。
ソラはブロックチェーンとはほとんど関係がありませんが、個人的には次の1〜2年かかると思います。SORAの影響により、他の高品質のAI生成ツールが迅速に出現して発達するようになり、Web3のGameFi、ソーシャルネットワーキング、クリエイティブプラットフォーム、Depinなどの複数のトラックに放射されるため、SORAを一般的に理解する必要があります。将来のAIがWeb3と効果的にどのように組み合わされるかは、考えなければならない重要なポイントかもしれません。
AI X Web3への4つの主要なパス
上記のように、実際には、一般化可能性と生成効果の観点から、生成AI:アルゴリズム、データ、およびコンピューティングの根拠に必要な3つの基本的な基盤しかないことがわかります。 。ブロックチェーンの最大の役割は、生産関係と地方分権の再構築の2つです。だから私は個人的に、2つの間に衝突を生成する4つの方法があると思います:
分散型コンピューティングパワー
過去に関連記事を書いたことがあるため、この段落の主な目的は、コンピューティングパワートラックの最近の状況を更新することです。AIに関しては、コンピューティングパワーは常にバイパスするのが難しいリンクです。ソラが生まれた後、AIのコンピューティングパワーに対する大きな需要はすでに想像できません。最近、スイスのダボスで開催された2024年の世界経済フォーラムでは、Openai CEOのウルトラマンは、この段階での最大の束縛であり、将来の2つの重要性が通貨に相当すると述べました。2月10日、ウルトラマンサムは、現在のグローバルな半導体産業構造を書き直すために、7兆米ドル(23年間で中国のGDPの40%に相当)を調達するという非常に素晴らしい計画を発表しました。コンピューティングパワーに関連する記事を書くとき、私の想像力は依然として国家の封鎖に限定されており、巨人はそれを独占しています。
したがって、分散化されたコンピューティングパワーの重要性は、自然に自明です。AIの観点から、コンピューティングパワーの使用は、2つの方向に分割できます。需要は、非常に高いしきい値を持つ方向であり、実装が非常に困難になるように運命づけられています。推論は比較的単純です。一方では、分散型ネットワーク設計では複雑ではありません。他方では、ハードウェアと帯域幅の要件は比較的低く、現在は主流の方向です。
集中化されたコンピューティングパワー市場の想像力は非常に大きく、多くの場合、キーワード「兆レベル」にリンクされています。しかし、最近登場した多数のプロジェクトから判断すると、それらのほとんどはまだ棚にあり、人気を利用しています。常に分散化の正しいバナーを保持しますが、分散型ネットワークの非効率性については黙ってください。また、デザインには高度な均一性があり、多数のプロジェクトが非常に似ています(ワンクリックL2プラスマイニングデザイン)。そのような状況で追跡します。
アルゴリズムとモデルコラボレーションシステム
機械学習アルゴリズムは、データから法律やパターンを学習し、それらに基づいて予測または決定を下すことができるこれらのアルゴリズムを指します。アルゴリズムは、設計と最適化には深い専門知識と技術革新が必要なため、テクノロジー集約型です。アルゴリズムは、AIモデルのトレーニングの中心にあり、データが有用な洞察または決定にどのように変換されるかを定義します。生成的敵対的ネットワーク(GAN)、変動自動エンコーダー(VAE)、および変圧器などのより一般的な生成AIアルゴリズムは、特定のフィールド(絵画、言語認識、翻訳、ビデオ生成など)です。そして、専用のAIモデルがアルゴリズムを介してトレーニングされます。
非常に多くのアルゴリズムとモデルには、独自の利点があります。最近人気のあるBittensorは、採掘インセンティブを通じてリーダーです。Commune AI(コードコラボレーション)およびその他の側面も主にこの方向に基づいています。
したがって、AIコラボレーションエコシステムの物語は、斬新で興味深いものです。結局のところ、主要なAI企業のクローズドソースアルゴリズムとモデルは、アップデート、反復、統合に非常に強力な機能を持っています。生成モデル。
分散化されたビッグデータ
単純な観点から、プライベートデータを使用してAIとタグデータは、ブロックチェーンと非常に一貫した方向ですプロジェクトの利益。複雑な観点から、ブロックチェーンデータのブロックチェーンデータを使用してブロックチェーンデータのアクセシビリティを解決することも興味深い方向です(Gizaの探索方向の1つ)。
理論的には、ブロックチェーン全体の状況を反映して、ブロックチェーンデータにいつでもアクセスできます。しかし、ブロックチェーンのエコシステム以外の人々にとっては、これらの膨大な量のデータを取得するのは容易ではありません。ブロックチェーンを完全に保存するには、豊富な専門知識と大量の専門的なハードウェアリソースが必要です。ブロックチェーンデータにアクセスするという課題を克服するために、業界でいくつかのソリューションが登場しています。たとえば、RPCプロバイダーはAPIを介してノードにアクセスしますが、インデックス作成サービスによりSQLとGraphQLを介してデータ抽出が可能になります。どちらも問題の解決に重要な役割を果たします。ただし、これらの方法には制限があります。RPCサービスは、大量のデータクエリを必要とし、多くの場合ニーズを満たすことができない高密度の使用シナリオには適していません。一方、インデックスサービスはデータを取得するためのより構造化された方法を提供しますが、Web3プロトコルの複雑さにより、効率的なクエリを構築することが非常に困難であり、数百または数千行の複雑なコードを必要とする場合があります。この複雑さは、一般的なデータ実践者とWeb3の詳細を深く理解していない人々にとって大きな障害です。これらの制限の累積効果は、この分野でのより広いアプリケーションと革新を促進できるブロックチェーンデータに簡単にアクセスして利用する必要があることを強調しています。
次に、高品質のブロックチェーンデータと組み合わせたZKML(ナレッジプルーフマシン学習、機械学習のチェーンの負担を軽減する)を介して、ブロックチェーンのアクセシビリティを解決するデータセットを作成することができるかもしれませんが、AIはブロックチェーンを大幅に減らすことができます。データアクセシビリティのしきい値であるため、MLフィールドの開発者、研究者、および愛好家は、効果的で革新的なソリューションを構築するためのより質の高いデータセットにアクセスできます。
AIはDappを支援します
CHATGPT3が23年で人気を博して以来、AIの力を与えるDAPPSは非常に一般的な方向になりました。非常に広範なユーティリティを備えた生成AIにAPIを介してアクセスできるため、データプラットフォーム、トレーディングロボット、ブロックチェーン百科事典、およびその他のアプリケーションを単純化およびインテリジェントに分析できます。一方、チャットボット(MyShellなど)やAIコンパニオン(Sleepless AI)としてプレイしたり、生成AIを介してチェーンゲームでNPCを作成することもできます。ただし、技術的な障壁が少ないため、それらのほとんどはAPIにアクセスした後に微調整されており、プロジェクト自体との組み合わせは完璧ではないため、めったに言及されていません。
しかし、ソラが到着した後、私は個人的には、AIがGamefiを強化する方向(メタバースを含む)とクリエイティブプラットフォームが次の焦点の焦点となると信じています。Web3フィールドのボトムアップの性質のため、従来のゲームやクリエイティブ企業と競合する製品を生産することは間違いなく困難であり、SORAの出現はこのジレンマを破る可能性があります(たぶん2〜3年)。Soraのデモから判断すると、Micro-Short Drama Companiesと競合する可能性があります。 – 従来の産業のダウンは壊れます。
結論
生成AIツールの継続的な進歩により、将来的にはより多くのエポック作りの「iPhone Moments」を経験します。多くの人がAIとWeb3の組み合わせにsnめていますが、実際には現在の方向のほとんどは問題ではないと思います。実際には、解決する必要がある3つの問題、つまり必要性、効率、適合していると思います。2つの統合は探査段階にありますが、このトラックが次の強気市場の主流になることを妨げません。
常に十分な好奇心と新しいものを受け入れることは、歴史的に必要なメンタリティです機会を逃します。







