
Compiled by: Wuzhu, bitchain vision
On April 8, 2025, Ethereum founder Vitalik gave a keynote speech at the 2025 Hong Kong Web3 Carnival Summit.Bitchain Vision compiles the speech content as follows.

Now, it takes a 1-week exit period to exit Optimism or Arbitrum, which can cause a lot of problems.
Why should we care about this?Why care about the faster connection between L2 and L1?I think there are two reasons for me.One of them isUser Experience, We hope users have a better experience, and waiting for 1 week is a bad experience.Another reason isWe need a more integrated ecosystem.We need to do something to really improve Optimism, Arbitrum, Polygon.
These are like the parts of the Ethereum world, they are not independent.
Currently, it is very fast to achieve interoperability between L1 and L2, but it requires a lot of Gas.We’ve really been concerned about this since last summer.Two things we focus on include: specific address of the blockchain and intent items.I hope it doesn’t take a week to transfer Optimism to Arbitrum, and I even hope it can put Optimism into a smart contract.
In a smart contract, if anyone first provides proof that they send the currency to any destination address through the contract, it will automatically jump to this step.Therefore, we hope to find the right way to minimize the waiting time of the week.
Why do we have a weekly withdrawal window now?Because Optimism’s Rollup needs to wait a week to see if anyone questioned its hash, and if no one questioned it, you can accept the hash.The advantage of Optimism is that it relies on very cautious technology, but at the cost of waiting for a week.
If we don’t want to wait 1 week, then we need to build a system that can completely use a non-Optimism proof system to package blocks, such asThe combination of ZK+TEE+OP——This is the design plan we proposed.
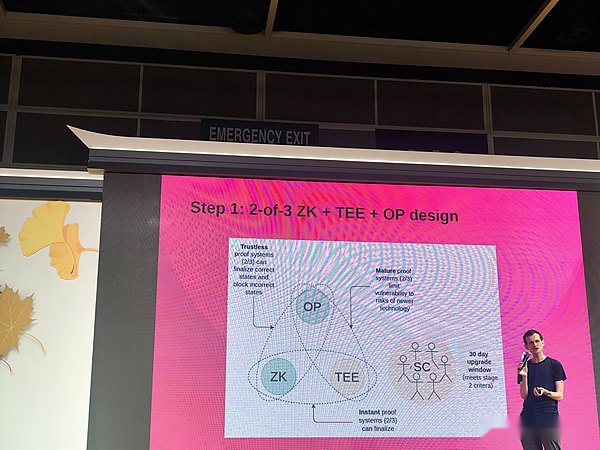
Under normal circumstances, once an L2 transaction occurs, the state will be finalized on L1 in one hour, reducing 1 hour to 12 seconds, which is basically just a matter of efficiency.So this is the first goal.The second goal is that we hope that L2 is trustless.We want to prove that the system can determine the correct state and record the error state even if the components that require trust are broken.So today, Rollup is either in phase zero or in phase one, which means they put a certain level of trust or all of their trust on some kind of security committee.You have to trust manufacturers to design them correctly.You have to trust that the manufacturer will not keep a copy on the site key itself.

Moreover, you must also believe that the hardware mechanism is not something that anyone who holds the hardware can destroy, and you must believe that they cannot find a way, such as laser, infrared scanning hardware, to extract information without destroying vision.
Now, we don’t want to put all our trust on ZK.
You assign trust between three different mechanisms that run according to very different logical types.If we have this design, you can reduce the finalization period from 1 hour to 1 week to 1 hour.By the way, another way isMy previous view of group systems, I basically divided them into two categories.One type is institutional trust, and the other type is encryption trust.
Another dimension is fast and slow.Fast things can be approved immediately, while slow things can take some time.Interestingly, like the four things here, they are basically 4 proof system components that people use or think about in the context of L2, right?If we could really put them in a box, they would fit just 2×2.
The first step, basically, we shorten the Devil Walk window from 1 week to 1 hour.What has this brought to you?Basically, it means that if you use native bridge to transfer assets directly, your waiting time will be reduced from 1 week to 1 hour.If you use intent-based bridging, intent-based bridging is instant, but the liquidity provider does not have to wait 1 hour, but rather 1 hour.The cost of providing liquidity has dropped by 168 times.So the fees you have to pay will drop by up to 168 times.
L2s can read L1 asynchronously using lowlookahead.This is a feature that L2 already has, as they must be able to handle deposits.We take the same state as reading the deposit and expose it to L1SLOADopcode.Supporting reading of L1 oracle data, keystore wallets, and many other applications is very valuable because one of the challenges L2 often faces is that they need to pay huge amounts of money.

So I get all kinds of custom applications, specific integrations.This can indeed reduce costs, because in many cases, the alternative will be able to directly read a copy of the application that already exists on one application, which is suitable for processing data.It works for certain things, not for things that need to be written to anyone.
A key storage wallet is another interesting idea, right?The idea of a key storage wallet is basically that in normal network security, you want to change a key, you don’t want the key to have an unlimited life cycle.Neo is part of the account abstract goal, which I will discuss today.
But I’ve talked about it many times, basically just creating an account with arbitrary logic so you can do things like changing the encryption algorithm, changing the keys, making them have a lot of resistance and making them use snark added like recovery methods.Now, one of the challenges is that if you can change the key, then you have a hundred changes after that.Therefore, you have to change the record of the current key in 100 places.
How do you solve this problem?We solve this problem by placing the record of the current key on a central contract.Then you appear a copy of the wallet on each L2 and just read L1.This makes many very reasonable and very same securitization security practices more feasible and practical in the L2 world.
Another benefit is that this makes the workflow that includes both L2 and L1 easier and more natural for developers.We’re not just talking about theory, and a bunch of completely separate chains, we’re actually talking about L1 theory continuing to be at the heart of the user experience for applications and people.
The third step is to prove the aggregation.I mentioned earlier that if we take this approach based on two or three, or in the future, if we do very good formal verification and we rely only on ZK, we can reduce the commit time from 1 week to 1 hour.Why 1 hour?Why not 12 seconds?There are two reasons, and we can solve these two reasons.The first reason is the submission cost.Therefore, submitting a proof to L1 requires an additional overhead, about 500,000 gas, and the cost of AA is very high.
Now, if you imagine submitting a proof for each period, there are 2.5 million periods a year.We spend $27.5 million a year just to maintain a relative value, which is crazy.Who is here willing to pay $27 million a year.But if you submit it every minute, instead of every 12 seconds, the $27 million spent per year becomes $5.5 million.Then, if you submit it every hour, it drops to under $100,000 per year.This is actually controllable.This natural solution is evidence aggregation.

If we have a large number of different tools, then these tools do not have to be submitted to different groups separately. Chain proofs can be grouped, and groups can submit their proofs to the aggregation, and then the aggregation can submit a separate snark to prove the existence of other snarks.The cost of verifying the snark is only a one-time cost of 500,000 gas.What’s going on here is basically what’s on this picture?Right?Basically, you have a bunch of proofs and those proofs also specify which contract.We are in a block.Then you have an aggregation proof.The aggregation proof is verified.The aggregation proof contains all information from a single aggregate as public input, and the proof occurs only once.Then this contract will only make a call to each summary once, and the only thing the call does is to target each summary.It just loads separately.The cost per time dropped from 500,000 gas to less than 10,000 gas.
There is stillThe fourth step is to reduce the proof delay.Prove that calculations take longer and more computing power than doing them.By default, this calculation does not fail.You have to extend it, and you have to do this very intensive calculation.

So the result is that in equilibrium, it still takes 500 seconds to prove it, right?This is a problem.So the question is, how do we solve this problem?Have two ideas.One is that we can use dedicated hardware to improve it.Some companies are already doing this.If you get 100x hardware acceleration factor, then you can prove it in real time.Another idea is super paralyzable proof.So from a mathematical point of view, this is actually very simple.Basically, you break the calculation into multiple steps.Then you generate proofs for each step in parallel on different devices.
If that’s not enough, the improvements to dedicated hardware will be faster.At the same time, the cost of improvement will be lower.So we have a lot of choices.
If you use Intensive Optimism and Arbitrum, both have much faster time slots, you can do it in 2 seconds as well.So it will be very cheap.So if you use Intensive, you will be able to quickly transfer essentially unlimited amounts of Ethereum at low cost.So, this also means we can create a closer connection between L1 and L2.We have a more integrated world, and it all becomes easier and faster for everyone.Thanks.






