Author: Lucas Tcheyan, Arjun Yenamandra, Source: Galaxy Research, Compiled by: Bitchain Vision
Introduction
Last year, Galaxy Research published its first article on the intersection of cryptocurrency and artificial intelligence.The article explores how cryptocurrency without trust and permissionless infrastructure can become the foundation for AI innovation.These include: the emergence of a decentralized market for processing power (or computing) that has emerged in response to the shortage of graphics processors (GPUs); the early applications of zero-knowledge machine learning (zkML) in verifiable on-chain reasoning; and the potential of autonomous AI agents to simplify complex interactions and use cryptocurrencies as native medium of exchange.
At that time, many of these initiatives were in their infancy, but were only some compelling proof of concepts that imply that they had practical advantages over centralized solutions, but had not yet expanded enough to reshape the AI landscape.However, in the year since then, decentralized AI has made meaningful progress in achieving it.To seize this momentum and discover the most promising progress, Galaxy Research will release a series of articles in the coming year to explore specific verticals in the frontiers of encryption + artificial intelligence.
This article was first published in decentralized training, focusing on projects dedicated to implementing permissionless training of basic models on a global scale.The motivations for these projects are dual.From a practical perspective, they recognized that a large number of idle GPUs around the world can be used for model training, providing AI engineers around the world with an otherwise unbearable training process and making open source AI development a reality.From a conceptual perspective, these teams are motivated by the strict control of one of the most important technological revolutions of our time and the urgent need to create open alternatives.
More broadly, for the encryption field, implementing decentralized and subsequent training of the basic model is a key step in building a fully on-chain AI stack that requires no permission and is accessible at every layer.The GPU market can access models and provide the hardware required for training and inference.zkML providers can be used to verify model output and protect privacy.AI agents can act as composable building blocks that combine models, data sources, and protocols into higher-order applications.
This report explores the underlying architecture of the decentralized artificial intelligence protocol, the technical problems it aims to solve, and the prospects for decentralized training.The underlying premise of cryptocurrencies and artificial intelligence remains the same as a year ago.Cryptocurrencies provide AI with a permissionless, trustless and composable value transfer settlement layer.The challenge now is to prove that decentralized approaches can bring practical advantages over centralized approaches.
Basics of model training
Before diving into the latest advances in decentralized training, it is necessary to have a basic understanding of large language models (LLMs) and their underlying architecture.This will help readers understand how these projects work and the main problems they are trying to solve.
Transformer
Large Language Models (LLMs) (such as ChatGPT) are powered by an architecture called Transformer.Transformer first proposed in a 2017 Google paper and is one of the most important innovations in the field of artificial intelligence development.In short, Transformer extracts data (called tokens) and applies various mechanisms to learn the relationship between these tokens.
The relationship between entries is modeled using weights.Weights can be considered as the millions to trillions of knobs that make up the model, which are constantly adjusted until the next entry in the sequence can be predicted consistently.After training is completed, the model can basically capture the patterns and meanings behind human language.
Key components of Transformer training include:
-
Forward delivery:In the first step of the training process, the Transformer enters a batch of tokens from a larger dataset.Based on these inputs, the model tries to predict what the next token should be.At the beginning of training, the weights of the model are random.
-
Loss calculation:Forward propagation predictions are then used to calculate the loss score, which measures the gap between these predictions and the actual markings in the original data batch of the input model.In other words, how does the predictions produced by the model during forward propagation compare to the actual markers used to train it in the larger dataset?During training, the goal is to reduce this loss score to improve the accuracy of the model.
-
Backpropagation:The gradient of each weight is then calculated using the loss score.These gradients tell the model how to adjust the weights to reduce losses before the next forward propagation.
-
Optimizerrenew:OptimizerThe algorithm reads these gradients and adjusts each weight to reduce the loss.
-
repeat:Repeat the above steps until all data has been consumed and the model begins to reach convergence–In other words, when further optimization no longer results in significant loss reduction or performance improvement.
Training (pre-training and post-training)
The complete model training process consists of two independent steps: pre-training and post-training.The above steps are a core component of the pre-training process.When done, they generate a pre-trained base model, commonly known as the base model.
However, models often require further improvement after pretraining, which is called post-training.Post-training is used to further improve the base model in a variety of ways, including improving its accuracy or customizing for specific use cases such as translation or medical diagnosis.
Post-training is a key step in making large language models (LLMs) a powerful tool today.There are several different ways to train afterwards.The two most popular ones are:
-
Supervised fine-tuning (SFT):SFT is very similar to the above pre-training process.The main difference is that the basic model is trained on more carefully planned data sets or tips and answers, so it can learn to follow specific instructions or focus on a certain field.
-
Reinforcement Learning (RL):RL does not improve the model by entering new data, but rather by rating the output of the model and letting the model update the weight to maximize that reward.Recently, the inference model (described below) has used RL to improve its output.In recent years, with pre-training scaling problems emerging, significant progress has been made in using RL and inference models after training, as it significantly improves model performance without additional data or large amounts of computation.
Specifically, post-RL training is ideal for solving obstacles faced in dispersed training (described below).This is because most of the time in RL, the model uses forward passes (the model makes predictions but has not changed itself yet) to generate a large amount of output.These forward passes do not require coordination or communication between machines and can be done asynchronously.They are also parallel, meaning they can be broken down into independent subtasks that can be performed simultaneously on multiple GPUs.This is because each rollout can be calculated independently, and simply add the calculation to increase throughput through the training run.Only after the best answer is selected will the model update its internal weights, reducing the frequency at which the machine needs to be synchronized.
After the model is trained, the process of using it to generate output is called inference.Unlike training that requires adjustments to millions or even billions of weights, reasoning keeps these weights unchanged and simply applies them to new inputs.For large language models (LLM), reasoning means taking a prompt, running it to various layers of the model, and step by step predicting the most likely next markup.Since inference does not require backpropagation (the process of adjusting weights based on the error of the model) or weight updates, it requires much less computationally than training, but due to the huge scale of modern models, it is still resource-intensive.
In short: reasoning is the driving force behind applications such as chatbots, code assistants and translation tools.At this stage, the model puts its “learned knowledge” into practice.
Training overhead
Promoting the above training process requires resource-intensive and highly specialized software and hardware to run at scale.The investments in the world’s leading artificial intelligence labs have reached unprecedented levels, ranging from hundreds of millions to billions of dollars.OpenAI CEO Sam Altman said the GPT-4 cost more than $100 million, while Anthropic CEO Dario Amodei said more than $1 billion in training programs are already underway.
A large portion of these costs comes from GPUs.Top GPUs like NVIDIA’s H100 or B200 cost up to $30,000, and OpenAI reportedly plans to deploy more than one million GPUs by the end of 2025.However, it is not enough to have the power of the GPU alone.These systems must be deployed in high-performance data centers equipped with ultra-high-speed communication infrastructure.Technologies such as NVIDIA NVLink support fast data exchange between GPUs within the server, while InfiniBand connects to server clusters so they can run as a single, unified computing structure.
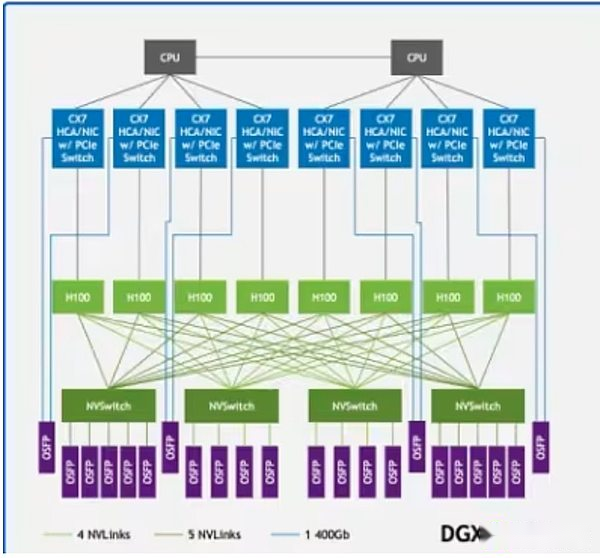 NVLink in the DGX H100 sample architecture connects the GPUs (light green rectangles) in the system, while InfiniBand connects the servers (green lines) into a unified network
NVLink in the DGX H100 sample architecture connects the GPUs (light green rectangles) in the system, while InfiniBand connects the servers (green lines) into a unified network
Therefore, most of the basic models are developed by centralized AI labs such as OpenAI, Anthropic, Meta, Google, and xAI.Only such giants have the rich resources needed for training.Although this has brought about a significant breakthrough in model training and performance, it has also concentrated control over the development of leading basic models in the hands of a few entities.Furthermore, there is growing evidence that the law of scaling may be working, limiting the effectiveness of enhancing the intelligence of pretrained models by simply adding computation or data.
To address this challenge, over the past few years, a group of AI engineers have begun to develop new model training methods to try to address these technical complexities and reduce huge resource requirements.This article calls this effort “decentralized training.”
Decentralized and distributed training
Bitcoin’s success proves that computing and capital can be coordinated in a decentralized manner, thus ensuring the security of large economic networks.Decentralized training aims to build a decentralized network using the features of cryptocurrencies, including permissionless, trustless and incentive mechanisms, to train a powerful basic model comparable to centralized providers.
In decentralized training, nodes located in different locations around the world work on permissionless, incentivized networks, contributing to the training of artificial intelligence models.This is different from distributed training, which refers to the model being trained in different regions but being performed by one or more entities that are licensed (i.e. through a whitelisting process).However, the feasibility of decentralized training must be based on distributed training.Many centralized laboratories, aware of the strict limitations of their training settings, have begun to explore ways to implement distributed training to achieve results comparable to existing settings.
There are some practical obstacles that prevent decentralized training from becoming a reality:
-
Communication overhead:When nodes are geographically dispersed, they cannot access the above communication infrastructure.Decentralized training requires consideration of standard network speed, frequent transmission of large amounts of data, and GPU synchronization during training.
-
verify:Decentralized training networks are essentially license-free and are designed to allow anyone to contribute their computing power.Therefore, they must develop verification mechanisms to prevent contributors from attempting to destroy the network through incorrect or malicious inputs, or exploiting system vulnerabilities to obtain rewards without contributing effective work.
-
calculate: Regardless of size, decentralized networks must gather enough computing power to train models.While this gives some of the advantages of decentralized networks, which were designed to allow anyone with a GPU to participate in the training process, it also brings complexity, as these networks must coordinate heterogeneous computing.
-
Incentives/Funding/Ownership and Monetization:Decentralized training networks must design incentive mechanisms and ownership/monetization models to effectively ensure network integrity and reward the contribution of computing providers, validators and model designers.This is in sharp contrast to the centralized laboratory where the construction and monetization of the model are done by a company.
Despite these limitations, many projects are still implementing decentralized training because they believe that control of the underlying model should not be in the hands of a few companies.Their goal is to deal with the risks posed by centralized training, such as single point failures due to relying on a few centralized products; data privacy and censorship; scalability; and consistency and bias in artificial intelligence.More broadly, they believe that open source artificial intelligence development is a necessity, not optional.Without open, verifiable infrastructure, innovation will be suppressed, access will be limited to a few privileged classes, and society will inherit AI systems shaped by narrow corporate incentives.From this perspective, decentralized training is not only about building competitive models, but also about creating a resilient, transparent and participatory ecosystem that reflects collective interests rather than proprietary interests.
Project Overview
Below, we will give an in-depth overview of the underlying mechanisms of several decentralized training projects.
Nous Resort
background
Founded in 2022, Nous Research is an open source AI research institution.The team started as an informal group of open source AI researchers and developers working to address the limitations of open source AI code.Its mission is to “create and provide the best open source model.”
The team has long regarded decentralized training as a major obstacle.Specifically, they realized that the tools to access GPUs and to coordinate communication between GPUs were developed primarily to cater to large centralized AI companies, which left resource-constrained organizations with little room to participate in meaningful development.For example, NVIDIA’s latest Blackwell GPUs (such as the B200) can communicate with each other using an NVLink switching system at speeds up to 1.8 TB per second.This is comparable to the total bandwidth of mainstream Internet infrastructure and can only be achieved in centralized, data center-scale deployments.Therefore, it is nearly impossible for small or distributed networks to achieve the performance of large AI labs without rethinking communication strategies.
Before embarking on solving the problem of decentralized training, Nous has made significant contributions to the field of artificial intelligence.In August 2023, Nous published “YaRN: Efficient Context Window Extension for Large Language Models”.This paper solves a simple but important problem: Most AI models can only remember and process a fixed amount of text at a time (i.e. their “context window”).For example, a model trained with a limit of 2,000 words will soon start to forget or lose information if the input document is longer.YaRN introduces a way to extend this limitation further without retraining the model from scratch.It adjusts how the model tracks word position (like bookmarks in a book) so that it can still track information flow even if the text is tens of thousands of words long.The method allows the model to process sequences of up to 128,000 markers—about the length of Mark Twain’s Adventures of Huckleberry Finn—using much less computational power and training data at the same time than the old method.In short, YaRN enables AI models to “read” and understand longer documents, conversations, or datasets at once.This is a major advance in AI capabilities expansion and has been adopted by a wider research community including OpenAI and Deepseek in China.
DeMo and DisTro
In March 2024, Nous published a breakthrough in the field of distributed training called “Decoupled Momentum Optimization” (DeMo).DeMo was developed by Nous researchers Bowen Peng and Jeffrey Quesnelle in collaboration with Diederik P. Kingma, co-founder of OpenAI and inventor of AdamW Optimizer.It is the main building block of Nous decentralized training stack, which reduces the communication overhead in distributed data parallel model training settings by reducing the amount of data exchanged between GPUs.In data parallel training, each node saves a complete copy of the model weights, but the dataset is split into blocks processed by different nodes.
AdamW is one of the most commonly used optimizers in model training.A key function of AdamW is to smooth out what is called momentum, the running average of the model weights that change in the past.Essentially, AdamW helps eliminate noise introduced during data parallel training, thereby improving training efficiency.Nous Research creates a completely new optimizer based on AdamW and DeMo, splitting momentum into local and shared parts across different trainers.This reduces the amount of traffic required between nodes by limiting the amount of data that must be shared between nodes.
DeMO selectively focuses on the fastest-changing parameters during each GPU iteration.The logic is simple: parameters with larger variations are crucial to learning and should be synchronized between workers with higher priority.At the same time, slower-changing parameters can be temporarily lagged without significantly affecting convergence.In fact, this filters out noise updates while retaining the most meaningful updates.Nous also uses compression techniques, including a discrete cosine transform (DCT) method similar to JPEG compressed images to further reduce the amount of data sent.By synchronizing only the most important updates, DeMO reduces communication overhead by 10 to 1,000 times (depending on model size).
In June 2024, the Nous team launched their second major innovation, the Distributed Training Optimizer (DisTro).DeMo offers core optimizer innovations, while DisTro integrates it into a wider optimizer framework that further compresses information shared between GPUs and addresses issues such as GPU synchronization, fault tolerance and load balancing.In December 2024, Nous used DisTro to train a model with 15 billion parameters on an LlaMA-like architecture, proving the feasibility of the method.
Psyche
In May, Nous released Psyche, a framework for coordinating decentralized training, further innovations in the DeMO and DisTro optimizer architectures.Psyche’s main technical upgrades include improved asynchronous training by allowing the GPU to send model updates when starting the next step of training.This minimizes idle time and brings GPU utilization closer to centralized, tightly coupled systems.Psyche further improved the compression technology introduced by DisTro, further reducing the communication load by 3 times.
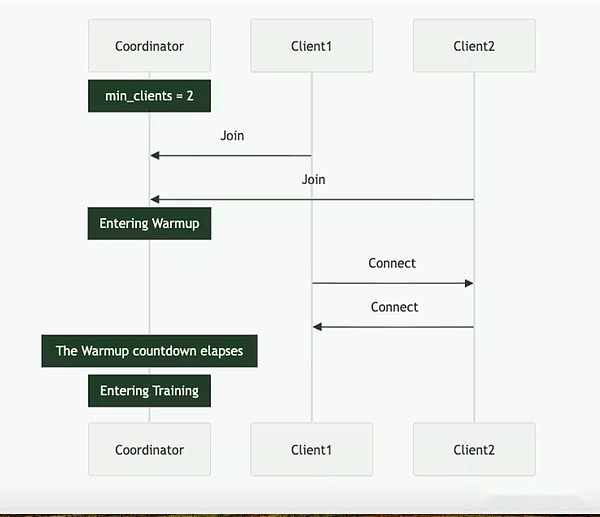
Psyche can be achieved through a fully on-chain (via Solana) or off-chain setup.It contains three main players: the coordinator, the client, and the data provider.The coordinator stores all the necessary information to facilitate training operation, including the latest state of the model, participating clients, and data allocation and output verification.The client is the actual GPU provider that performs training tasks during training runs.In addition to model training, they are involved in the witness process (described below).The data provider (the client can store it by itself) provides the data needed for training.
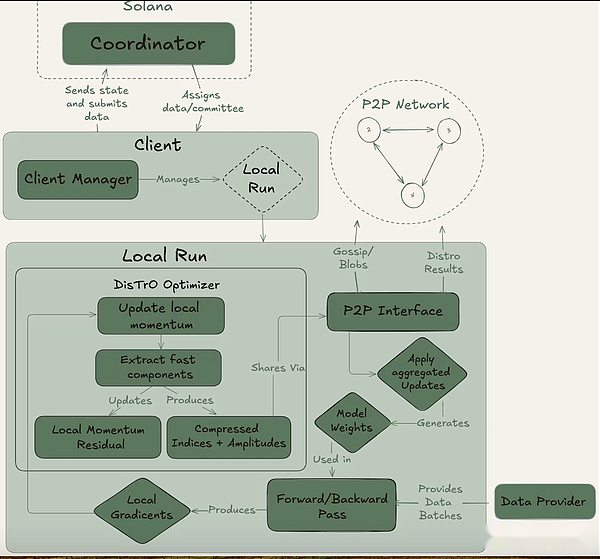 Psyche divides training into two different stages: epoch and step.This creates natural entry and exit points for clients so that they can participate without investing in a full training run.This structure helps minimize opportunity costs for GPU providers, as they may not be able to invest resources throughout the run.
Psyche divides training into two different stages: epoch and step.This creates natural entry and exit points for clients so that they can participate without investing in a full training run.This structure helps minimize opportunity costs for GPU providers, as they may not be able to invest resources throughout the run.
At the beginning of an epoch, the coordinator defines the key parameters: the model architecture, the data set to be used, and the number of clients required.Next is a brief warm-up phase, where the client will synchronize to the latest model checkpoint, which can be from a public source or from other clients point-to-point synchronization.After training begins, each client will be assigned a portion of the data and trained locally.After the calculation update, the client broadcasts its results to the rest of the network along with the encryption promise (the SHA-256 hash that proves that the work is done correctly).
A portion of the client is randomly selected as witnesses in each round and serves as the main verification mechanism of Psyche.These witnesses train as usual, but also verify which client updates are received and valid.They submit Bloom filters to the coordinator, a lightweight data structure that effectively summarizes these participations.While Nous himself admits that the approach is not perfect because it may produce false positives, researchers are willing to accept this trade-off for efficiency.Once an updated witness confirms that the quorum reaches, the coordinator applies the update to the global model and allows all clients to synchronize their model before entering the next round.
Crucially, Psyche’s design allows for overlap in training and verification.Once the client submits the update, it can immediately start training the next batch without waiting for the coordinator or other clients to complete the previous round of training.This overlapping design, combined with DisTrO’s compression technology, ensures that communication overhead is kept minimal and that the GPU is not idle.
 In May 2025, Nous Research launched the largest training run to date: Consilience, a Transformer with 40 billion parameters, pre-training about 20 trillion tokens in the Psyche decentralized training network.Training is still in progress.So far, the operation has been basically stable, but some loss peaks have occurred, indicating that the optimization trajectory has briefly deviated from convergence.To do this, the team rolled back to the last health checkpoint and encapsulated the optimizer using OLMo’s Skip-Step protection, which automatically skips any updates of any loss or gradient norms that differ by several standard deviations from the mean, reducing the risk of future peaks.
In May 2025, Nous Research launched the largest training run to date: Consilience, a Transformer with 40 billion parameters, pre-training about 20 trillion tokens in the Psyche decentralized training network.Training is still in progress.So far, the operation has been basically stable, but some loss peaks have occurred, indicating that the optimization trajectory has briefly deviated from convergence.To do this, the team rolled back to the last health checkpoint and encapsulated the optimizer using OLMo’s Skip-Step protection, which automatically skips any updates of any loss or gradient norms that differ by several standard deviations from the mean, reducing the risk of future peaks.
Solana’s role
While Psyche can run in an off-chain environment, it is designed to be used on the Solana blockchain.Solana acts as the trust and accountability layer for the training network, recording customer commitments, witness proofs, and training metadata on the chain.This creates an immutable audit trail for each round of training, allowing transparent verification of who made contributions, what work was done, and whether it passed.
Nous also plans to use Solana to facilitate the distribution of training rewards.Although the project has not released formal token economics, Psyche’s documentation outlines a system in which the coordinator will track client’s computational contributions and allocate points based on validated work.These points can then be exchanged for tokens by acting as financial smart contracts escrowed on-chain.Clients who complete effective training steps can receive rewards directly from the contract based on their contributions.Psyche has not yet used the reward mechanism in the training run, but once officially launched, the system is expected to play a central role in the allocation of Nous crypto tokens.
Hermes Model Series
In addition to these research contributions, Nous has established its leading open source model developer status with its Hermes series of instruction-tuned large language models (LLM).In August 2024, the team launched Hermes-3, a full-parameter model suite fine-tuned based on Llama 3.1, which has achieved competitive results on the public rankings, although relatively small, comparable to larger proprietary models.
Recently, Nous released the Hermes-4 model series in August 2025, the most advanced model series to date.Hermes-4 focuses on improving the model’s step-by-step reasoning capabilities, while also performing excellently in regular instruction execution.It performed well in math, programming, understanding and common sense tests.The team adheres to Nous’ open source mission and publicly releases all Hermes-4 model weights for everyone to use and build.In addition, Nous has released a model accessibility interface called Nous Chat, which will be available for free within the first week of release.
The release of the Hermes model not only cements Nous’ credibility as a model-building organization, but also provides practical validation for its broader research agenda.Each release of Hermes proves that cutting-edge capabilities can be achieved in an open environment, laying the foundation for teams’ decentralized training breakthroughs (DeMo, DisTrO, and Psyche) and ultimately leading to the ambitious Consilience 40B run.
Atropos
As mentioned above, reinforcement learning plays an increasingly important role in post-training due to advances in inference models and the expansion limitations of pre-training.Atropos is Nous’s solution to reinforcement learning in a decentralized environment.It is a plug-and-play modular reinforcement learning framework for LLM, adapting to different inference backends, training methods, datasets and reinforcement learning environments.
When post-reinforcement learning is trained in a decentralized manner using a large number of GPUs, the instant output generated by the model during training will have different completion times.Atropos acts as a rollout processor, i.e. a central coordinator, which coordinates task generation and completion across devices, thereby enabling asynchronous reinforcement learning training.
The initial version of Atropos was released in April, but currently contains only an environmental framework that coordinates reinforcement learning tasks.Nous plans to release a complementary training and reasoning framework in the coming months.
Prime Intellect
background
Founded in 2024, Prime Intellect is committed to building a large-scale decentralized AI development infrastructure.Founded by Vincent Weisser and Johannes Hagemann, the team initially focused on integrating computing resources from centralized and decentralized providers to support collaborative distributed training of advanced AI models.Prime Intellect’s mission is to democratize AI development, enabling researchers and developers around the world to access scalable computing resources and jointly own open AI innovation.
OpenDiLoCo, INTELLECT-1 and PRIME
In July 2024, Prime Intellect released OpenDiLoCo, an open source version of DiLoCo, a low-communication model training method developed by Google DeepMind for data parallel training.Google developed the model based on the view that “training through standard backpropagation at a modern scale presents unprecedented engineering and infrastructure challenges…it is difficult to coordinate and closely synchronize a large number of accelerators.” While this statement focuses on the practicality of large-scale training rather than the spirit of open source development, it defaults to the limitations of long-term centralized training and the need for distributed alternatives.
DiLoCo reduces the frequency and amount of information shared between GPUs when training models.In centralized settings, the GPUs share all updated gradients with each other after each step of training.In DiLoCo, the sharing frequency of update gradients is lower to reduce communication overhead.This creates a dual optimization architecture: individual GPUs (or GPU clusters) run internal optimizations, updating the weight of their own models after each step; and external optimizations, internal optimizations are shared among GPUs, and all GPUs are then updated based on the changes made.
OpenDiLoCo demonstrated 90% to 95% of GPU utilization in its initial release, meaning that despite being distributed across two continents and three countries, few machines are idle.OpenDiLoCo is able to reproduce considerable training results and performance, while the traffic volume is reduced by 500 times (as shown in the purple line catching up with the blue line in the figure below).
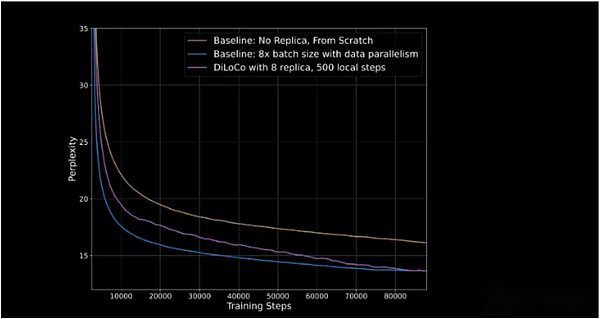
The vertical axis represents Perplexity, which measures the model’s ability to predict the next marker in a sequence.The lower the Perplexity, the more confident the model’s predictions are, and the higher the accuracy is.
In October 2024, Prime Intellect starts training INTELLECT-1, this is the first 10 billion parameter language model trained in a distributed manner.The training took 42 days, and the model was open sourced after that.Training is conducted in five countries on three continents.The training run demonstrates the gradual improvement of distributed training, with the utilization rate of all computing resources reaching 83%, and in the United States alone, the utilization rate of inter-node communication reaches 96%.The GPU used by this project comes from Web2 and Web3 providers, including the crypto GPU markets such as Akash, Hyperbolic and Olas.
INTELLECT-1 adopts Prime Intellect’s new training framework PRIME, which allows Prime Intellect training systems to adapt when calculating unexpected entry and exit ongoing training.It introduces innovative technologies such as ElasticDeviceMesh, allowing contributors to join or exit at any time.
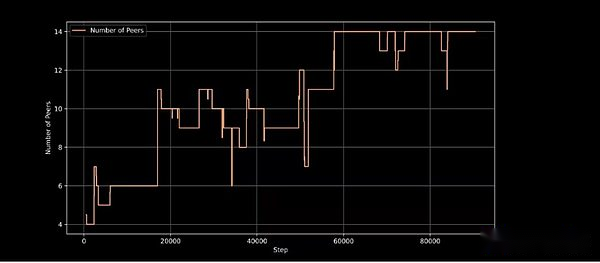
Active training nodes in the training step, demonstrating the ability of the training architecture to handle dynamic node participation
INTELLECT-1 is an important validation of Prime Intellect’s decentralized training approach and has been praised by AI thought leaders such as Jack Clark (co-founder of Anthropic), and is considered a viable demonstration of decentralized training.
Protocol
In February this year, Prime Intellect added another layer to its stack, launching Protocol.Protocol connects all the training tools of Prime Intellect together to create a point-to-point network for decentralized model training.These include:
-
Computes the switch GPU to facilitate training runs.
-
The PRIME training framework reduces communication overhead and improves fault tolerance.
-
An open source library called GENESYS for useful synthetic data generation and validation in RL fine tuning.
-
A lightweight verification system called TOPLOC for validating the output of model execution and participating nodes.
Protocol’s role is similar to Nous’s Psyche, with four main players:
-
Workers: A software that enables users to contribute their computing resources to training or other Prime Intellect AI-related products.
-
Verifier: Verify computational contributions and prevent malicious behavior.Prime Intellect is working to apply the state-of-the-art inference verification algorithm TOPLOC to decentralized training.
-
Orchestrator: A way to calculate pool creators manage workers.It works similar to Nous’ orchestrator.
-
Smart contracts: Track computing resource providers, reduce staking from malicious participants, and pay rewards independently.Currently, Prime Intellect is running on the Sepolia test network for Ethereum L2 Base, but Prime Intellect has stated that it will eventually plan to migrate to its own blockchain.
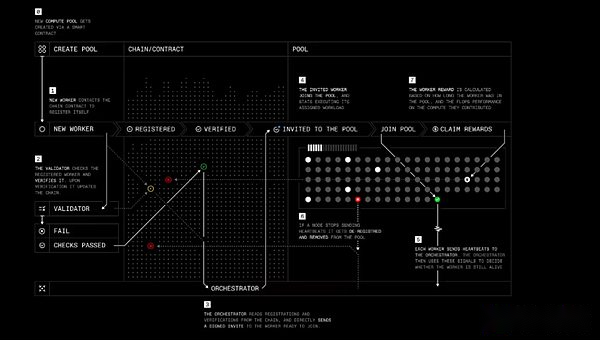 Protocol training step by step
Protocol training step by step
Protocol aims to ultimately allow contributors to own shares in the model or receive rewards for their work, while providing open source AI projects with new ways to fund and manage development through smart contracts and collective incentives.
INTELLECT 2 and reinforcement learning
In April this year, Prime Intellect began training a 32 billion parameter model called INTELLECT-2.INTELLECT-1 focuses on training the basic model, while INTELLECT-2 uses reinforcement learning to train inference models on another open source model (Alibaba’s QwQ-32B).
The team introduced two critical infrastructure components to make this decentralized RL training practical:
-
PRIME-RL is a fully asynchronous reinforcement learning framework that divides the learning process into three independent stages: generating candidate answers; training selected answers; and broadcasting updated model weights.This decoupling mechanism enables the system to span unreliable, slow or geographically distributed networks.The training process uses another innovation from Prime Intellect, GENESYS, to generate thousands of mathematical, logic, and coding questions, and is equipped with an automatic checker that can immediately tell whether the answer is correct or not.
-
SHARDCAST is a new system for quickly distributing large files (such as updated model weights) on the network.SHARDCAST Not every machine downloads updates from the central server, but adopts a structure that shares updates between machines.This keeps the network efficient, fast and resilient.
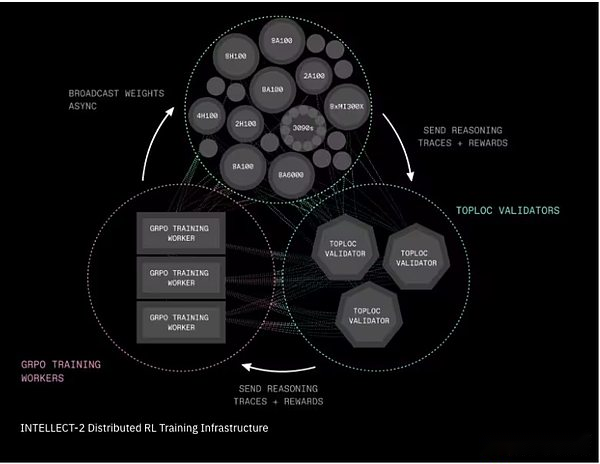 Intellect-2 Distributed Reinforcement Learning Training Infrastructure
Intellect-2 Distributed Reinforcement Learning Training Infrastructure
For INTELLECT-2, contributors also need to stake the testnet crypto token to participate in the training run.If they contribute effective work, they will automatically receive rewards.If not, their staking may be cut.Although no actual funding was involved during this test run, this highlights the initial form of some crypto-economic experiments.More experiments are needed in this area, and we expect further changes in the application of the crypto economy in terms of security and incentive mechanisms.In addition to INTELLECT-2, Prime Intellect continues to carry out several important programs not covered in this report, including:
-
SYNTHETIC-2, a next-generation framework for generating and validating inference tasks;
-
Prime Collective Communications Library, which implements efficient, fault-tolerant collective communication operations (e.g. reduction via IP), and provides a shared state synchronization mechanism to keep peers synchronized, and allows dynamic joining and leaving peers at any time during training, as well as automatic bandwidth-aware topology optimization;
-
Continuously enhance the functionality of TOPLOC to enable scalable, low-cost inference proofs to verify model output;
-
Improvements to Prime Intellect protocol and crypto economy based on lessons learned from INTELLECT2 and SYNTHETIC1
Pluralis Research
Alexander Long is an Australian machine learning researcher with a PhD from the University of New South Wales.He believes that open source model training is overly reliant on leading artificial intelligence labs to provide the basic models for others to train.In April 2023, he founded Pluralis Research, aiming to open a different path.
Pluralis Research uses an approach called “Protocol Learning” to solve the decentralized training problem, which is described as “low bandwidth, heterogeneous multi-participants, model parallel training and reasoning.”A major notable feature of Pluralis is its economic model, which provides equity-like gains to contributors of training models to incentivize computational contributions and attract top open source software researchers.This economic model is based on the core attribute of “unextractability”: that is, no participant can obtain a complete set of weights, which is closely related to the use of training methods and model parallelism.
Model Parallelism
Pluralis’ training architecture utilizes model parallelism, which is different from the data parallelism approach implemented by Nous Research and Prime Intellect in the initial training run.As the size of the model grows, even the H100 rack, one of the most advanced GPU configurations, is difficult to carry a complete model.Model parallelism provides a solution to this problem by splitting individual components of a single model on multiple GPUs.
There are three main methods for model parallelization.
-
Pipeline parallelism: The layers of the model are divided on different GPUs.During training, each small batch of data flows through these GPUs like a pipeline.
-
Tensor (in-layer) parallelism: Instead of providing the entire layer for each GPU, the heavy math within each layer is separated so that multiple GPUs can share the work of a single layer at the same time.
-
Mixed Parallel: In practice, large models use various methods, using pipelines and tensors in parallel, and usually in conjunction with data.
Model parallelism is an important advance in distributed training because it allows training of cutting-edge-scale models, allowing lower-level hardware to participate, and ensuring that no one participant has access to the full set of model weights.
Protocol Learning and Protocol Models
Protocol Learning is a framework for Pluralis to use model ownership and monetization in a decentralized training environment.Pluralis highlights three key principles that constitute the protocol learning framework—decentralization, motivation and detrust.
The main difference between Pluralis and other projects is its focus on model ownership.Given that the value of the model is mainly due to its weight, the protocol model (Protocol Models) Try to split the weights of the model so that no single participant during the model training process can have full weights.Ultimately, this will give each contributor to the training model a certain ownership, thus sharing the benefits generated by the model.
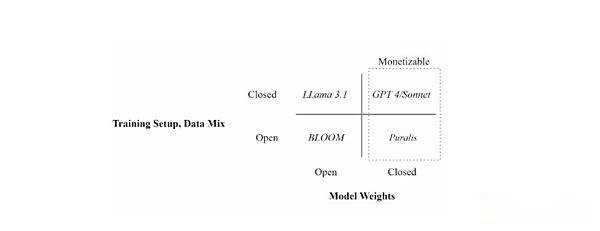 Position different language models through training settings (open vs. enclosed data) and model weight availability (open vs. enclosed)
Position different language models through training settings (open vs. enclosed data) and model weight availability (open vs. enclosed)
This is a fundamentally different approach to economics of decentralized models compared to previous examples.Other projects incentivize contributions by providing a funding pool that is allocated to contributors during the training cycle based on specific metrics (usually the time or computing power contributed).Contributors of Pluralis are motivated to devote resources only to the models they believe are most likely to succeed.Training a poorly performed model will waste computing power, energy, and time because poorly performed models will not generate any revenue.
This is different from the previous method.First, it does not require individuals who want to train the model to raise initial funds to pay the contributors, thus lowering the threshold for model training and development.Second, it better coordinates the incentive mechanisms between model designers and computing providers, as both parties want the final version of the model to be as perfect as possible to ensure its success.This also provides the possibility for the emergence of model training specialization.For example, there may be more risk-bearing trainers providing computing services to early/experimental models in search of greater returns (similar to venture capitalists), while computing providers focus only on those mature and more likely to apply (similar to private equity investors).
While PM may represent a major breakthrough in monetization and incentive mechanisms for decentralized training, Pluralis has not elaborated on its specific implementation methods.Given the high complexity of the approach, issues that have yet to be addressed include how to allocate ownership of the model, how to allocate benefits, and even how to manage future upgrades or use cases of the model.
Decentralized training innovation
In addition to economic considerations, Protocol Learning faces the same core challenge as other decentralized training programs, using heterogeneous GPU networks with communication limitations to train large AI models.
In June this year, Pluralis announced the successful training of 8 billion parameter LLM based on Meta’s Llama 3 architecture and published its protocol model paper.In the paper, Pluralis shows how to reduce the communication overhead between GPUs that perform model parallel training.It does this by limiting the signals flowing through each Transformer layer to a pre-selected tiny subspace, compressing forward and backward passes up to 99%, reducing network traffic by 100 times without compromising accuracy or adding significant overhead.In short, Pluralis found a way to compress the same learning information to a small fraction of the bandwidth required by earlier methods.
This is the first decentralized training run, and the model itself is dispersed on nodes connected through low bandwidth rather than replication.The team successfully trained an Llama model with 8 billion parameters on low-end consumer-grade GPUs spread across four continents that connect only through 80 megabytes per second of home internet connection per day.In the paper, Pluralis demonstrates that the convergence of this model is as good as running on a 100 Gb/s data center cluster.In practice, this means that parallel decentralized training of large-scale models is now possible.
Finally, a paper by Pluralis on asynchronous training for pipeline parallel training was received by ICML (one of the leading artificial intelligence conferences) in July.When pipeline parallel training is performed through the Internet rather than high-speed data centers, it also faces a communication bottleneck because the nodes operate in an essentially similar to pipelines, with each successive node waiting for the previous node to update the model.This can lead to gradient obsolete and delayed information transmission.The decentralized training framework demonstrated in the paper, SWARM, eliminates two classic bottlenecks that usually hinder daily GPU participation in training: memory capacity and tight synchronization.Eliminating these two bottlenecks can better utilize all available GPUs, reduce training time and reduce costs, which is critical to scaling large models with distributed volunteer-based infrastructure.For a brief look at this process, watch this video by Pluralis.
Looking ahead, Pluralis says it plans to launch a real-time training that anyone can participate in soon, but a specific date has not been determined.The launch will provide a deeper understanding of aspects of the agreement that have not been released yet, especially economic models and crypto infrastructure.
Templar
background
Templar was launched in November 2024 and is an incentive-driven decentralized AI task market based on the Bittensor protocol subnet.It started as an experimental framework that aims to bring together global GPU resources for license-free AI pre-training and aims to make large-scale model training accessible, secure and resilient through Bittensor’s tokenized incentives, thereby redefining AI development.
From the very beginning, Templar took on the challenge of coordinating decentralized training for LLM pre-training on the Internet.This is a difficult task, as latency, bandwidth limitations, and heterogeneous hardware make it difficult for distributed actors to achieve the efficiency of centralized clusters, and seamless GPU communications of centralized clusters enable rapid iteration of massive models.
Most importantly, Templar prioritizes participation that is truly licensed, allowing anyone with computing resources to participate in AI training without approval, registration, or gatekeeping.This permissionless approach is crucial to Templar’s mission to democratize AI development, as it ensures that breakthrough AI capabilities are not controlled by a few centralized entities but can emerge from open collaboration around the world.
Templartrain
Templar uses data to train in parallel, and there are two main factors:
-
miner:These participants performed training tasks.Each miner synchronizes with the latest global model, gets unique data shards, trains locally using forward and backward passes, compresses gradients using a custom CCLoco optimizer (described below), and submits gradient updates.
-
Verifier: The validator downloads and decompresses the update submitted by the miner, applies it to the local copy of the model, and calculatesLoss increment(Indicators that measure the degree of improvement of the model).These increments are used to score miners’ contributions through Templar’s Gauntlet system.
To reduce communication overhead, Templar’s research team first developed the block compression DiLoCo (CCLoco).Similar to Nous, CCLoco improves communication efficient training techniques such as the Google DiLoCo framework, reducing inter-node communication costs by orders of magnitude while reducing the losses often caused by such methods.Instead of sending full updates at every step, CCLoco shares only the most important changes at set intervals and keeps a small run count to ensure that no meaningful data is lost.The system adopts a competition-based model that incentivizes miners to provide low-latency updates to receive rewards.To receive rewards, miners must keep up with the network by deploying efficient hardware.This competitive structure is designed to ensure that only participants who maintain sufficient performance can participate in the training process, while lightweight sanitation checks filter out noticeably bad or malformed updates.In August, Templar officially released the updated training architecture and renamed it SparseLoCo.
Verifiers use Templar’s Gauntlet system to track and update each miner’s skill rating based on observed model loss reduction contributions.With the technology called OpenSkill, high-quality miners who continue to be updated effectively will receive higher skill ratings, increasing their influence on model aggregation and earning more TAOs (native tokens of the Bittensor network).Miners with lower ratings will be discarded during the aggregation process.After the scoring, the validators with the highest pledge will summarize updates from the top miners, sign the new global model, and publish it to storage.If the model is out of sync, miners can use this version of the model to catch up.
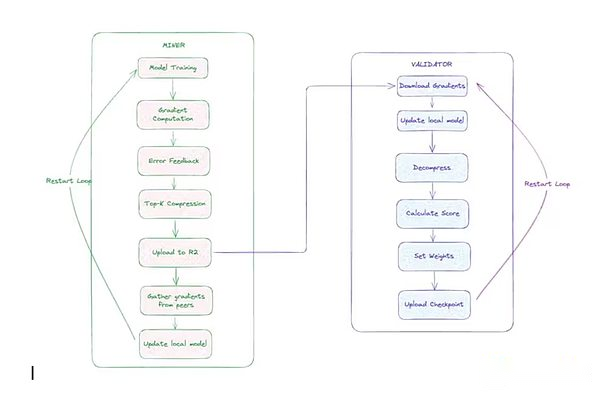 Templar Decentralized Training Architecture
Templar Decentralized Training Architecture
Templar has started three rounds of training so far: Templar I, Templar II and Templar III.Templar I is a model with 1.2 billion parameters, deploying nearly 200 GPUs worldwide.Templar II is in progress, training a model with 8 billion parameters, and planning to start larger training soon.Templar is currently focusing on training models with smaller parameters, a well-thought-out choice designed to ensure that upgrades to the decentralized training architecture (as mentioned above) can work effectively before scaling to larger model scales.From optimization strategies and scheduling to research iterations and incentives, these ideas are validated on 8 billion models with smaller parameters, allowing teams to iterate quickly and cost-effectively.Following recent progress and the formal release of the training architecture, the team launched Templar III in September, a model with 70 billion parameters and the largest pre-training run in the decentralized field to date.
TAO and incentive mechanisms
A key feature of Templar is its incentive model that is bound to TAO.Rewards are allocated based on skill weighted contributions trained by the model.Most protocols (such as Pluralis, Nous, Prime Intellect) have licensed runs or prototypes, while Templar runs entirely on Bittensor’s real-time network.This makes Templar the only protocol that has integrated a real-time, license-free economic layer into its decentralized training framework.This real-time production deployment allows Templar to iterate its infrastructure in real-time training run scenarios.
Each Bittensor subnet runs with its own “alpha” token, which acts as a market signal for the reward mechanism and subnets to perceive value.Templar’s alpha token is called gamma.alpha tokens cannot be traded freely on external markets; they can only be exchanged for TAOs through a liquidity pool dedicated to their subnet using an automated market maker (AMM).Users can pledge TAO to obtain gamma, or redeem gamma as TAO, but they cannot directly exchange gamma for alpha tokens from other subnets.Bittensor’s Dynamic TAO (dTAO) system uses the market price of alpha tokens to determine issuance allocations between subnets.When the price of gamma rises relative to other alpha tokens, this indicates that the market’s confidence in Templar’s decentralized training capabilities has increased, resulting in an increase in TAO issuance of the subnet.As of early September, Templar’s daily issuance accounted for about 4% of TAO’s circulation, ranking in the top six of the 128 subnets of the TAO network.
The issuance mechanism of the subnet is as follows: In each 12-second block, the Bittensor chain will issue TAO and alpha tokens to its liquidity pool based on the price ratio of the subnet alpha tokens relative to other subnets.Each block issues up to one full alpha token to the subnet (initial issuance rate, which may be halved) to the subnet to incentivize subnet contributors, of which 41% are allocated to miners, 41% are allocated to validators (and their stakeholders), and 18% are allocated to subnet owners.
This incentive drives contribution to the Bittensor network by linking economic rewards to the value provided by participants.Miners are motivated to provide high-quality AI outputs, such as model training or inference tasks, to obtain higher ratings from validators and thus a larger share of output.Verifiers (and their stakers) receive rewards for accurately assessing and maintaining network integrity.
The market valuation of Alpha tokens is determined by staking activities, ensuring that subnets that show higher practicality can attract more TAO inflows and issuances, thereby creating a competitive environment that encourages innovation, specialization and sustainable development.Subnet owners will receive a percentage of rewards, which are motivated to design effective mechanisms and attract contributors, and ultimately build a permissionless decentralized AI ecosystem that allows global participation to jointly promote the progress of collective intelligence.
The mechanism also introduces new incentive challenges such as maintaining validators’ honesty, resisting witch attacks, and reducing conspiracy.Bittensor subnets are often troubled by cat-and-mouse games between validators or miners and subnet creators, the former trying to play with the system and the latter trying to hinder them.In the long run, these struggles should make the system one of the most powerful as subnet owners learn how to overcome malicious actors.
Gensyn
Gensyn released its first streamlined white paper in February 2022, elaborating on the framework for decentralized training (Gensyn is the only decentralized training protocol covered in our first article last year on understanding the intersection of encryption technology and artificial intelligence).At that time, the protocol focused mainly on the verification of AI-related workloads, allowing users to submit training requests to the network, processed by the computing provider, and ensuring that these requests were executed as promised.
The initial vision also highlighted the need to accelerate applied machine learning (ML) research.In 2023, Gensyn builds on this vision to clearly propose a broader need to acquire machine learning computing resources worldwide to serve specific AI applications.Gensyn introduced the GHOSTLY principle as a framework that such protocols must meet: universality, heterogeneity, overhead, scalability, trustlessness, and latency.Gensyn has been focusing on building computing infrastructure, and the collaboration marks its formal expansion to other key resources beyond computing.
Gensyn’s core divides its training technology stack into four distinct parts—execution, verification, communication, and coordination.The execution part is responsible for handling operations on any device in the world that can perform machine learning operations.The communication and coordination section enables the devices to send information to each other in a standardized manner.The verification section ensures that all operations can be calculated without trust.
Execution—RL Swarm
Gensyn’s first implementation on this stack is a training system called RL Swarm, a decentralized coordination mechanism for post-training reinforcement learning.
RL Swarm is designed to allow multiple computing providers to participate in the training of a single model in a permissionless, trust-minimized environment.The protocol is based on a three-step cycle: answering, reviewing and resolving.First, each participant generates model output (answer) based on the prompt.The other participants then evaluated the output using a shared reward function and submitted feedback (review).Finally, these reviews will be used to select the best answer and include them in the next version of the model (solved).The entire process takes place in a point-to-point manner without relying on a central server or trusted organization.
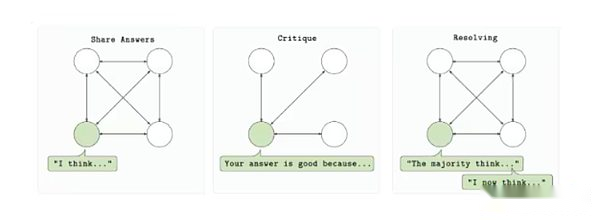 RL Swarm Training Loop
RL Swarm Training Loop
Reinforcement Learning Swarm is based on the increasing importance of reinforcement learning in post-model training.As the model reaches the upper limit of scale in the pre-training stage, reinforcement learning provides a mechanism to improve inference ability, instruction compliance ability and factuality without retraining on massive data sets.Gensyn’s system achieves this improvement in a decentralized environment by breaking down reinforcement learning loops into different roles, each role can be independently verified.Crucially, it introduces fault-tolerant asynchronous execution, which means contributors do not need to be online or stay perfectly synced to participate.
It is also modular in nature.The system does not require the use of a specific model architecture, data type, or reward structure, allowing developers to customize training loops based on their specific use cases.Whether it is training coding models, inference agents, or models with specific instruction sets, RL Swarm provides a reliable large-scale operation framework for decentralized RL workflows.
Verde
So far, one of the least discussed aspects in this report about decentralized training is verification.Gensyn builds a Verde trust layer for its GPU marketplace.With Verde, Gensyn introduced a new verification mechanism so that protocol users can trust people on the other side of the situation are doing what they say.
Each training or inference task is scheduled to a certain number of independent providers determined by the application.If their output exactly matches, the task is accepted.If the outputs are different, the referee protocol locates the first step in which the two trajectories are diverged and recalculates the operation only.The party whose number matches the referee retains its payment, while the other party loses its interests.
What makes this possible is RepOps, a library of “repeatable operators” that forces common neural network math operations (matrix multiplication, activation, etc.) to run in a fixed, deterministic order on any GPU.Determinism is crucial here; otherwise, although both validators are correct, they may produce different results.So honest providers will provide the same result bit by bit, allowing Verde to see the game as a proof of correctness.Since the referee only replays one microstep, the added cost is only a few percentage points, rather than the 10,000-fold overhead of the full encryption proof commonly used in these processes.
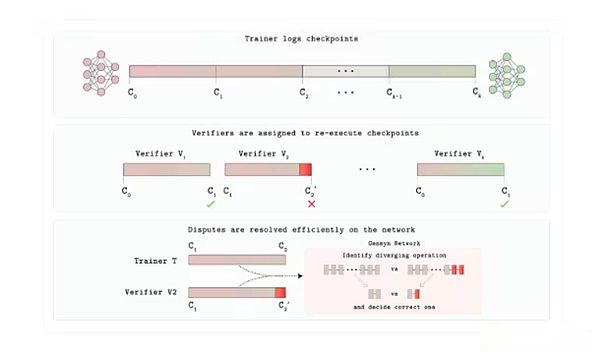
Verde Verification Protocol Architecture
In August, Gensyn released Judge, a verifiable AI evaluation system that contains two core components: Verde and a reproducible runtime, which guarantees bit by bit same result across hardware.To show it, Gensyn launched a “progressive reveal game” in which AI models bet on answers to complex questions during information revelation, Judge deterministically validates the results and rewards accurate early predictions.
Judge is significant because it solves the trust and scalability issues in AI/ML.It enables reliable model comparisons, improve transparency in high-risk environments, and reduces the risk of bias or manipulation by allowing independent verification.In addition to inference tasks, Judge can support other use cases such as decentralized dispute resolution and prediction markets, which fits Gensyn’s mission to build a trusted distributed AI computing infrastructure.Ultimately, tools like Judge can enhance repeatability and accountability, which is crucial in an era when AI is increasingly at the heart of society.
Communication and Coordination: Skip-Pipe and Diversity Expert Integration
Skip-Pipe is a solution by Gensyn to address the bandwidth bottleneck problem that a single megamo model occurs when slicing on multiple machines.As mentioned earlier, traditional pipeline training forces each microbatch to traverse all layers in sequence, so any slower node will cause pipeline stagnation.Skip-Pipe’s scheduler can dynamically skip or reorder layers that can cause delays, reducing iteration times by up to 55% and maintain availability even when half of the nodes fail.By reducing inter-node traffic and allowing layers to be removed as needed, it enables the trainer to scale very large models to geo-distributed, low bandwidth GPUs.
Diversified expert integration solves another coordination puzzle: how to build a powerful “hybrid expert” system that avoids continuous crosstalk.Gensyn’s Heterogeneous Domain Expert Integration (HDEE) trains each expert model completely independently and merges only at the end.Surprisingly, under the same overall computing budget, the final integration in 20 of the 21 test areas surpassed a unified benchmark.Since there is no gradient or flow of activation functions between machines during training, any idle GPU can contribute computing power.
Skip-Pipe and HDE together provide Gensyn with an efficient communication solution.The protocol can shard within a single model if necessary, or train multiple small experts in parallel with lower independence costs without operating a perfect, low latency network as traditionally used.
Test Network
In March, Gensyn deployed a testnet on a custom Ethereum rollup.The team plans to gradually update the test network.Currently, users can participate in Gensyn’s three products: RL Swarm, BlockAssist, and Judge.As mentioned above, RL Swarm allows users to participate in post-RL training processes.In August, the team launched BlockAssist, “This is the first large-scale demonstration of assisted learning, a way to train agents directly from human behavior without manual tagging or RLHF.”Users can download Minecraft and use BlockAssist to train Minecraft models to play the game.
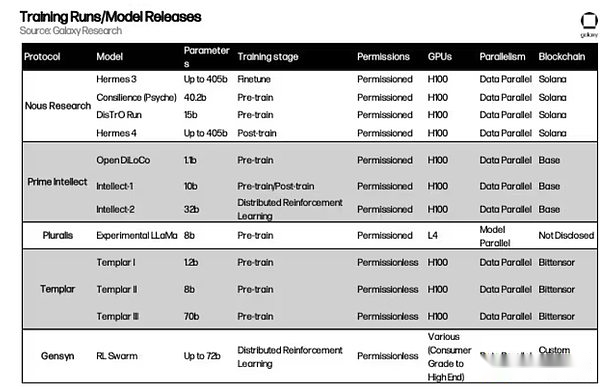
Other projects worth paying attention to
The above chapters outline the mainstream architecture implemented to achieve decentralized training.However, new projects are emerging one after another.Here are some new projects in the field of decentralized training:
Fortytwo: Fortytwo is built on the Monad blockchain and focuses on group reasoning (SLM), where multiple small language models (SLMs) collaborate on queries in a node network and generate peer-reviewed outputs, thereby improving accuracy and efficiency.The system utilizes consumer-grade hardware such as idle laptops, eliminating the need to use expensive GPU clusters like centralized AI.The architecture includes decentralized inference execution and training functions, such as generating synthetic datasets for dedicated models.The project is now available on the Monad Development Network.
Ambient: Ambient is the upcoming “useful proof of work” Layer-1 blockchain, designed to support always-on-line, autonomous AI agents on the chain, enabling them to continuously perform tasks, learn and evolve in a permissionless ecosystem without centralized supervision.It will adopt a single open source model trained and improved by network miners collaboratively, and contributors will be rewarded for their contributions to training, building and using AI models.Although Ambient emphasizes decentralized reasoning, especially in the proxy aspect, miners on the network will also be responsible for continuously updating the underlying models that support the network.Ambient uses a novel p roof- o f-logits mechanism (in this system, validators can verify that the model calculations are correctly run by checking the miner’s original output value (called logits).The project is built on a fork from Solana and has not yet been officially launched.
Flower Labs: Flower Labs is developing an open source framework for federated learning, Flower, which supports collaborative AI model training across decentralized data sources without sharing raw data, thereby protecting privacy while aggregating model updates.Flower was founded to address data centralization, allowing institutions and individuals to train models using local data, such as healthcare or finance, while contributing to global improvements through secure sharing of parameters.Unlike crypto-native protocols that emphasize token rewards and verifiable computing, Flower prioritizes collaboration that protects privacy in real-world applications, making it an ideal choice for regulated industries without blockchain.
Macrocosmos: Macrocosmos runs on the Bittensor network and is developing a complete AI model creation process covering five subnets that focus on pre-training, fine-tuning, data collection and decentralized science.It introduces the Incentive Orchestration Training Architecture (IOTA) framework for pre-training large language models on heterogeneous, unreliable, and license-free hardware, and has initiated over a billion parameter trainings and plans to quickly scale to larger parameter models.
Flock.io:Flock is a decentralized AI training ecosystem that combines federated learning with blockchain infrastructure to achieve collaborative model development for privacy protection in a modular, token-incentive network.Participants can contribute models, data, or computing resources and receive on-chain rewards proportional to their contributions.To protect data privacy, the protocol adopts federated learning.This allows participants to train global models using local data that is not shared with others.While this setup requires additional verification steps to prevent irrelevant data (often referred to as data poisoning) from entering model training, it is an effective promotional approach for use cases such as healthcare applications where multiple healthcare providers can train global models without leaking highly sensitive medical data.
Prospects and risks
Over the past two years, decentralized training has transformed from an interesting concept to an effective network running in a real environment.While these projects are still far from the expected final state, they are making meaningful progress on the road to decentralized training.Looking back at the existing decentralized training pattern, some trends are beginning to emerge:
Real-time proof of concept is no longer a fantasy.Early verifications such as Nous’ Consilience and Prime Intellect’s INTELLECT-2 have entered production-scale operations over the past year.Breakthroughs such as OpenDiLoCo and Protocol Models are enabling high-performance AI on distributed networks, facilitating cost-effective, resilient and transparent model development.These networks are coordinating dozens or even hundreds of GPUs, pre-training and fine-tuning mid-sized models in real time, proving that decentralized training can go beyond closed demonstrations and temporary hackathons.While these networks are still not permissionless networks, Templar stands out in this regard; its success reinforces the idea that decentralized training is moving from simply proving that underlying technology is effective to being able to scale to match the performance of centralized models and attracting the GPU resources needed to produce the underlying models at scale.
The scale of the model continues to expand, but the gap remains.From 2024 to 2025, the number of parameter models for decentralized projects jumped from single-digit to 30 billion to 40 billion.However, the leading AI lab has released trillions of parameters of the system and continues to innovate rapidly with its vertically integrated data centers and state-of-the-art hardware.Decentralized training can bridge this gap by leveraging training hardware from around the world, especially as centralized training methods face increasing restrictions due to the need for an increasing number of hyperscale data centers.But closing this gap will depend on further breakthroughs in optimizers and gradient compression for efficient communications to achieve global scale, as well as an inoperable incentive and verification layer.
Post-training workflow is becoming an area of concern.Supervised fine-tuning, RLHF, and domain-specific reinforcement learning require much lower synchronization bandwidth than comprehensive pre-training.Frameworks such as PRIME-RL and RL Swarm have run on unstable consumer-level nodes, allowing contributors to profit from idle cycles while projects can quickly commercialize customized models.Given that RL is well suited for decentralized training, its importance as a field of focus for decentralized training programs may become increasingly prominent.This makes it possible for decentralized training to be the first to find a large-scale product market fit in RL training, as evidenced by the increasing number of teams launching RL-specific training frameworks.
The incentive and verification mechanism lags behind technological innovation.The incentive and verification mechanisms still lag behind technological innovation.Only a few networks, especially Templar, provide real-time coin rewards and on-chain penalty and confiscation mechanisms, thereby effectively curbing bad behavior and has been tested in real-world environments.Although other programs are experimenting with reputation scores, witness proof or training proof programs, these systems are still unverified.Even if technical barriers are overcome, governance will present equally difficult challenges, as decentralized networks must find ways to formulate rules, enforce rules and resolve disputes without repeated inefficiencies that occur in crypto DAOs.Resolving technical barriers is only the first step; long-term viability depends on combining it with reliable verification mechanisms, effective governance mechanisms, and compelling monetization/ownership structures to ensure trust in the work being carried out and to attract the talent and resources needed to scale up.
The stack is fusing into an end-to-end pipeline.Today, most leading teams combine bandwidth aware optimizers (DeMo, DisTrO), decentralized computing exchanges (Prime Compute, Basilica), and on-chain coordination layers (Psyche, PM, PRIME).Finally, a modular open pipeline is formed, which reflects the workflow of centralized laboratories from data to deployment, but without a single control point.Even if projects do not integrate their own solutions directly, or even if they are integrated, they can be accessed with other crypto projects focused on the verticals required for decentralized training, such as data provisioning protocols, GPU and inference markets, and decentralized storage backbones.This peripheral infrastructure provides plug-and-play components for decentralized training programs that can be further leveraged to enhance their products and better compete with centralized peers.
risk
Hardware and software optimization is a constantly changing goal—the Central Laboratory is also expanding in this field.Nvidia’s Blackwell B200 chip has just been announced. In the MLPerf benchmark, whether it is pre-training with 405 billion parameters or 70 billion LoRA fine-tuning, its training throughput is 2.2 to 2.6 times faster than the previous generation, greatly reducing time and energy costs for the giants.In terms of software, PyTorch 3.0 and TensorFlow 4.0 introduce compiler-level graph fusion and dynamic shape kernels to further improve performance on the same chip.With improvements in hardware and software optimization, or the advent of new training architectures, decentralized training networks must also keep pace with continuous updates to adapt to the fastest and most advanced training methods, attracting talent and inspiring meaningful model development.This will require the team to develop software that ensures continuous high performance, regardless of the underlying hardware, and a software stack that enables these networks to adapt to changes in the underlying training architecture.
Existing enterprise open source model blurs the boundaries between decentralized and centralized training.Most centralized AI labs keep models closed, which further proves that decentralized training is a way to ensure openness, transparency and community governance.Although recent projects such as DeepSeek, GPT open source versions and Llama show their shift toward higher openness, it is unclear whether this trend can continue in the context of growing competition, regulatory and security concerns.Even if the weights are revealed, they still reflect the values and choices of the original lab – the ability to independently train is critical to adaptability, coordination with different priorities, and ensuring access is not limited by a handful of incumbent businesses.
Recruitment is still difficult.Many teams tell us this.While the quality of talent that joins decentralized training programs has improved, they lack the strong resources that are leading AI labs (for example, OpenAI recently offered millions of dollars in “special rewards” per employee, or the $250 million offer Meta has offered to poach researchers).Currently, decentralized projects attract mission-driven researchers who value openness and independence, while also drawing talent from a wider global talent pool and a vibrant open source community.However, in order to compete on scale, they must prove themselves by training models comparable to existing companies and perfecting incentives and monetization mechanisms to create meaningful benefits for contributors.While license-free networking and crypto-economic incentives provide unique value, the inability to access distribution and establish a sustainable revenue stream may hinder long-term growth in the sector.
Regulatory resistance does exist, especially for uncensored models.Decentralized training faces unique regulatory challenges: Design-wise, anyone can train any type of model.This openness is certainly an advantage, but it also raises security risks, especially in biosecurity, false information or other sensitive areas of abuse.EU and U.S. policymakers have signaled that they will strengthen their scrutiny: The EU’s Artificial Intelligence Act sets additional obligations on high-risk base models, while U.S. agencies are considering limiting open systems and potential export-style control measures.Events involving decentralized models for harmful purposes alone can trigger comprehensive regulation, threatening the fundamental principle of permissionless training.
Distribution and Monetization: Distribution remains a major challenge.Leading labs including OpenAI, Anthropic and Google have huge distribution advantages through brand awareness, corporate contracts, cloud platform integration and direct access to consumers.In contrast, decentralized training programs lack these built-in channels and more efforts must be put into place to enable models to be adopted, gain trust and embedded into actual workflows.Given that cryptocurrencies are still in its infancy in their integration outside of crypto applications (although this is changing rapidly), this may be more challenging.A very important and unsolved question is who will actually use these decentralized training models.High-quality open source models already exist, and once new advanced models are released, it is not particularly difficult for others to extract or adjust them.Over time, the open source nature of decentralized training programs should create network effects that solve the distribution problem.However, even if they can solve the distribution problem, the team will face the challenge of product monetization.Currently, Pluralis’ project managers seem to be most directly addressing these monetization challenges.This is not just an encryption x AI issue, but a broader encryption issue that highlights future challenges.
in conclusion
Decentralized training has rapidly evolved from an abstract concept to an effective network that coordinates the operation of actual global training.In the past year, projects including Nous, Prime Intellect, Pluralis, Templar and Gensyn have proven that it is possible to connect decentralized GPUs together, compress communications efficiently, and even start experimenting with incentives in real-world environments.These early demonstrations demonstrate that decentralized training can go beyond theory, although the path to competing with centralized laboratories at cutting-edge scale remains difficult.
Even if the fundamental models finally trained by decentralized projects are comparable to today’s leading artificial intelligence laboratories, they face the most severe test: proving their realistic advantages beyond the demands of ideas.These advantages may be endogenously manifested through excellent architecture or rewarding contributors’ new ownership and monetization schemes.Alternatively, these advantages may also be exogenous if centralized existing participants try to stifle innovation by keeping weights closed or injecting unwelcome alignment biases.
In addition to technological advances, attitudes towards the field have also begun to change.One founder described the changes in emotions at major AI conferences over the past year: A year ago, there was little interest in decentralized training, especially when used in conjunction with cryptocurrencies; six months ago, participants began to recognize potential problems but expressed doubts about the feasibility of large-scale implementation; and in recent months, there has been increasing recognition that continued progress can make scalable decentralized training possible.The evolution of this concept shows that the momentum of decentralized training is also increasing not only in the field of technology, but also in terms of legitimacy.
Risks are real: existing companies still maintain their hardware, talent and distribution advantages; regulatory review is imminent; incentives and governance mechanisms have not been tested on a large scale.However, its advantages are equally striking.Decentralized training represents not only an alternative technology architecture, but also a fundamental concept of building artificial intelligence: no license, global ownership, and consistent with a diverse community rather than a few companies.Even if only one project can prove that openness can translate into faster iteration, novel architecture or more inclusive governance, it will mark a breakthrough moment for cryptocurrencies and artificial intelligence.The road ahead is long, but the core elements of success are now firmly grasped.







