Original title: Glue and coprocessor architectures
Author: Vitalik, founder of Ethereum; compiled by Deng Tong, Bitchain Vision
Special thanks to Justin Drake, Georgios Konstantopoulos, Andrej Karpathy, Michael Gao, Tarun Chitra and various Flashbots contributors for their feedback and comments.
If you analyze any resource-intensive calculations that are being done in the modern world with moderate detail, one feature you will find over and over again is that the calculation can be divided into two parts:
-
A relatively small amount of complex but not very computationally intensive “business logic”;
-
A lot of intensive but highly structured “expensive jobs”.
These two forms of computing are best handled in different ways: the former, whose architecture may be less efficient but needs to be very versatile; the latter, whose architecture may be less universal but needs to be very versatile..
What are the examples of this different approach in practice?
First, let’s take a look at the environment I’m most familiar with: Ethereum Virtual Machine (EVM).Here is the getth debug tracking for my recent Ethereum transaction: Update the IPFS hash of my blog on ENS.The transaction consumed a total of 46924 gases and can be classified as follows:
-
Basic cost: 21,000
-
Call data: 1,556
-
EVM execution: 24,368
-
SLOAD opcode: 6,400
-
SSTORE opcode: 10,100
-
LOG Opcode: 2,149
-
Others: 6,719

EVM trace for ENS hash update.The penultimate column is gas consumption.
The moral of this story is that most execution (about 73% if you only look at EVM, or about 85% if you include the basic cost part covering the calculation) is concentrated in a very few structured expensive operations: storing read and write, logs and encryption (the basic cost includes 3000 for payment signature verification, and the EVM also includes 272 for payment hash).The rest of the execution is “business logic”: swap the calldata bit to extract the ID of the record I’m trying to set and the hash I set it to, etc.In token transfers, this will include adding and subtracting balances, in more advanced applications, this may include looping, and so on.
In EVM, these two forms of execution are processed in different ways.Advanced business logic is written in more advanced languages, usually Solidity, which can be compiled to EVM.Expensive work is still triggered by EVM opcodes (SLOAD, etc.), but more than 99% of the actual calculations are done in dedicated modules written directly inside client code (or even libraries).
To strengthen our understanding of this pattern, let’s explore it in another context: AI code written in python using torch.
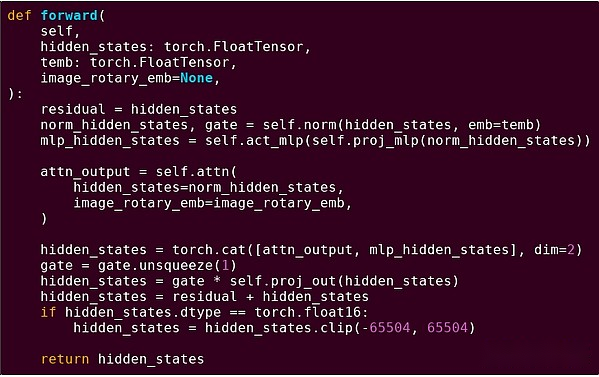
Forward delivery of a block of the transformer model
What did we see here?We see a relatively small amount of “business logic” written in Python that describes the structure of the operations being performed.In practical applications, there is another type of business logic that determines details such as how to get input and what operations are performed on the output.However, if we dig into each individual operation itself (the steps inside self.norm, torch.cat, +, *, self.attn…), we see vectorized calculations: the same operation computes a large number of parallel calculations in a large number of casesvalue.Similar to the first example, a small portion of the calculations are used for business logic, and most are used to perform large structured matrix and vector operations—in fact, most are just matrix multiplication.
Just like in the EVM example, these two types of work are handled in two different ways.Advanced business logic code is written in Python, a highly general and flexible language, but also very slow, and we just accept inefficiency because it only involves a small part of the total computing cost.Meanwhile, intensive operations are written in highly optimized code, usually CUDA code running on the GPU.We are even increasingly beginning to see LLM reasoning happening on ASICs.
Modern programmable cryptography, such as SNARK, once again follows a similar pattern on both levels.First, the prover can be written in a high-level language, where the heavy work is done through vectorization operations, just like the AI example above.My circular STARK code here shows this.Second, programs executed within cryptography can themselves be written in a way that divides between common business logic and highly structured expensive work.
To understand how it works, we can take a look at one of the latest trends STARK proven.For general purpose and ease of use, the team is increasingly building STARK provers for widely adopted minimal virtual machines such as RISC-V.Any program that needs to prove the execution can be compiled into RISC-V, and the proofer can then prove the RISC-V execution of the code.
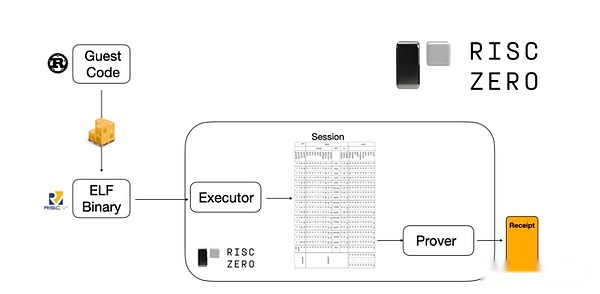
Charts from RiscZero documentation
This is very convenient: it means we only need to write proof logic once, and from then on any program that needs proof can be written in any “traditional” programming language (such as RiskZero supports Rust).However, there is a problem: this approach can incur a lot of overhead.Programmable encryption is already very expensive; adding too much overhead to run code in a RISC-V interpreter.So, developers came up with a trick: identify the specific expensive operations (usually hashing and signatures) that make up most of the calculations, and then create specialized modules to prove them very efficiently.Then you can get the best of both worlds by simply combining the inefficient but universal RISC-V proof system with the efficient but professional proof system.
Programmable encryption other than ZK-SNARK, such as multi-party computing (MPC) and fully homomorphic encryption (FHE), may be optimized using similar methods.
Overall, what is the phenomenon?
Modern computing increasingly follows what I call bonding and coprocessor architecture: you have some central “bonding” components that are highly versatile but inefficient and responsible for one or more coprocessor components.These coprocessor components are low-versatile but highly efficient.
This is a simplification: In practice, the trade-off curve between efficiency and universality is almost always more than two levels.GPUs and other chips commonly referred to as “coprocessors” in the industry are less versatile than CPUs, but more versatile than ASICs.The trade-offs on the degree of specialization are complex, depending on predictions and intuition about which parts of the algorithm will remain unchanged in five years and which parts will change in six months.In the ZK proof architecture, we often see similar multi-layer specializations.But for a broad mindset model, it is enough to consider two levels.There are similar situations in many computing fields:
Judging from the above examples, calculations can of course be divided in this way, which seems to be a natural law.In fact, you can find examples of computational specialization over decades.However, I think this separation is increasing.I think there is a reason for this:
We have only recently reached the limit of CPU clock speed improvement, so further benefits can only be achieved through parallelization.However, parallelization is difficult to reason, so it is often more practical for developers to continue to reason in sequence and have parallelization happen on the backend, and package it in a dedicated module built for a specific operation.
Computing has only recently become so fast that the computational cost of business logic has become truly negligible.In this world, it makes sense to optimize VMs running on business logic to achieve goals other than computing efficiency: developer-friendliness, familiarity, security, and other similar goals.Meanwhile, dedicated “coprocessor” modules can continue to be designed for efficiency and gain their security and developer-friendliness from their relatively simple “interface” with adhesives.
What is the most important and expensive operation is becoming clearer.This is most obvious in cryptography, where the types of specific expensive operations are most likely to be used: modulus operations, linear combination of elliptic curves (also known as multiscalar multiplication), fast Fourier transform, and so on.This situation has also become increasingly obvious in artificial intelligence, with most calculations being “mainly matrix multiplication” (although varying levels of accuracy).Similar trends have emerged in other areas.There are much fewer unknowns in (computation-intensive) calculations than 20 years ago.
what does that mean?
A key point is that the gluer (Glue) should be optimized to be a good glue (Glue), and the coprocessor should also be optimized to be a good coprocessor.We can explore the meaning of this in several key areas.
EVM
Blockchain virtual machines (such as EVMs) do not need to be efficient, they just need to be familiar with them.Just add the correct coprocessor (aka “precompiled”), and the computation in an inefficient VM can be as efficient as the computation in a native efficient VM.For example, the overhead incurred by the 256-bit register of EVM is relatively small, while the familiarity of EVM and the benefits of the existing developer ecosystem are huge and durable.The development teams optimizing EVMs even found that the lack of parallelization is often not a major barrier to scalability.
The best way to improve EVM might be (i) adding better precompiled or dedicated opcodes, such as some combination of EVM-MAX and SIMD, and (ii) improving storage layouts, such as Verkle treeChanges, as a side effect, greatly reduce the cost of accessing adjacent storage slots.
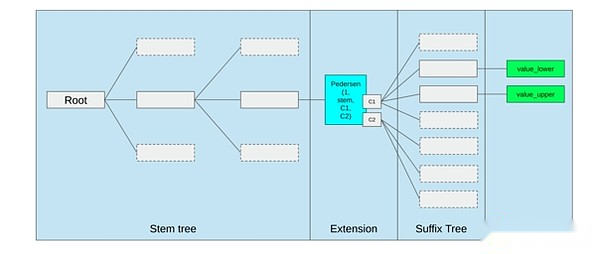
Storage optimization in Ethereum Verkle tree proposal, put adjacent storage keys together and adjust gas costs to reflect this.Optimizations like this, coupled with better precompilation, may be more important than tweaking the EVM itself.
Secure computing and open hardware
One of the challenges in improving modern computing security at the hardware level is its overly complex and proprietary nature: the chip is designed to be efficient, which requires proprietary optimization.The backdoor is easily hidden, and side channel vulnerabilities are constantly discovered.
People continue to work to promote more open and safer alternatives from multiple perspectives.Some computing is increasingly done in a trusted execution environment, including on the user’s phone, which has improved user security.Action to drive more open source consumer hardware continues, with some recent victories like RISC-V laptops running Ubuntu.
RISC-V laptop running Debian
However, efficiency remains a problem.The author of the above-linked article wrote:
Newer open source chip designs such as RISC-V are unlikely to be comparable to processor technology that has existed and has been improved over decades.There is always a starting point for progress.
More paranoid ideas, such as this design for building RISC-V computers on FPGAs, faces greater overhead.But what if the glue and coprocessor architecture means that this overhead isn’t actually important?If we accept open and secure chips will be slower than proprietary chips, if needed, even abandon common optimizations such as speculative execution and branch prediction, but try to compensate for this by adding (proprietary, if needed) ASIC modules that are used for the mostWhat happens to intensive specific types of calculations?Sensitive computing can be done in the “main chip” which will be optimized for security, open source design, and side channel resistance.More intensive computations (e.g., ZK proof, AI) will be done in the ASIC module, which will learn less information about the computation being performed (possibly, through encryption blinding, and in some cases even zero information).
Cryptography
Another key point is that all this is very optimistic about cryptography, especially programmable cryptography, becoming mainstream.We have seen some specific hyper-optimized implementations of highly structured computing in SNARK, MPC, and other settings: some hash functions are only a few hundred times more expensive than running the computing directly, and AI (mainly matrix multiplication)The overhead is also very low.Further improvements such as GKR may further reduce this level.A fully general VM execution, especially when executed in a RISC-V interpreter, may continue to incur approximately ten thousand times the overhead, but for the reasons described in this article, it does not matter: just use efficient and dedicated technologies separatelyTo handle the most intensive parts of the calculation, the total overhead is controllable.
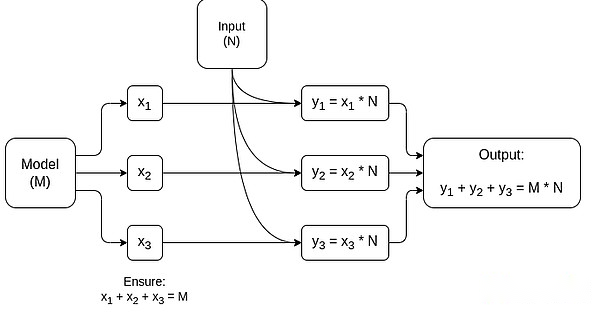
A simplified graph of MPC dedicated to matrix multiplication, which is the largest component in AI model inference.See this article for more details, including how to keep models and inputs private.
One exception to the idea that “glued layers only need to be familiar, not efficient” is latency, and to a lesser extent data bandwidth.If the calculation involves dozens of repeated heavy operations on the same data (like cryptography and artificial intelligence), any delay caused by inefficient glue can become the main bottleneck in runtime.Therefore, the glued layer also has efficiency requirements, although these requirements are more specific.
in conclusion
Overall, I think the above trends are very positive from multiple perspectives.First, it’s a reasonable way to maximize computing efficiency while maintaining developer-friendliness, and being able to get more of both is good for everyone.In particular, by specializing on the client side to improve efficiency, it improves our ability to run sensitive and highly performant computations (e.g., ZK proof, LLM reasoning) locally on user hardware.Second, it creates a huge window of opportunity to ensure that the pursuit of efficiency does not harm other values, most notably security, openness and simplicity: Side channel security and openness in computer hardware, reducing circuit complexity in ZK-SNARK, and reducing complexity in virtual machines.Historically, the pursuit of efficiency has led to these other factors taking a back seat.With the glue and coprocessor architecture, it is no longer needed.Part of the machine optimizes efficiency, and the other part optimizes versatility and other values, and the two work together.
This trend is also very beneficial for cryptography, which is a major example of “expensive structured computing” that has accelerated the development of this trend.This adds another opportunity to improve security.In the blockchain world, security improvements are also possible: we can worry less about the optimization of virtual machines and focus more on optimizing precompilation and other functions of coexisting with virtual machines.
Third, this trend provides opportunities for smaller, newer participants to participate.If the calculations become less single and more modular, this will greatly lower the barrier to entry.Even with one type of computational ASIC, it is possible to make a difference.The same is true in the ZK proof field and in EVM optimization.Writing code with near-frontier efficiency becomes easier and easier to access.Auditing and formal verification of such code becomes easier and easier to access.Finally, as these very different computing fields are converging to some common patterns, there is more room for collaboration and learning between them.







