作者:Sleepy.txt

11月4日凌晨,备受瞩目的 Alpha Arena AI 交易大赛落幕。
结果出乎所有人的意料,阿里巴巴的 Qwen 3 Max 以 22.32% 的收益率夺冠,另一家中国公司 DeepSeek 位居第二,收益率 4.89%。
而来自硅谷的四位明星选手则全线溃败。OpenAI 的 GPT-5 亏损 62.66%,Google 的 Gemini 2.5 Pro 亏损 56.71%,马斯克旗下的 Grok 4 亏损 45.3%,Anthropic 的 Claude 4.5 Sonnet 也亏损了 30.81%。
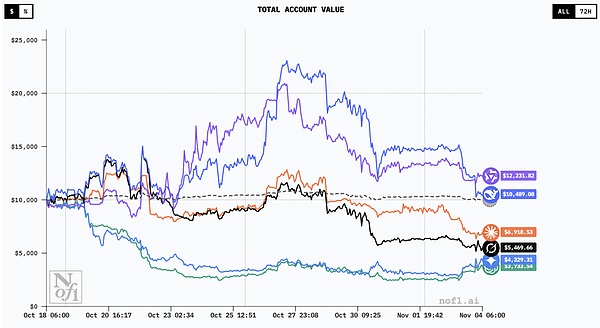
所有模型的交易曲线|图源:nof1
这场比赛其实是一场特殊的实验。10 月 17 日,美国研究公司 Nof1.ai 将六个全球顶尖的大语言模型投入真实的加密货币市场,每个模型都获得 1 万美元初始资金,在去中心化交易平台 Hyperliquid 上进行为期 17 天的永续合约交易。永续合约是一种没有到期日的衍生品,允许交易者通过杠杆放大收益,不过与此同时也会放大风险。
这些 AI 的起点相同,市场数据也相同,但最终结果却完全不同。
这不是一次在虚拟环境中的跑分测试,而是一场真金白银的生存游戏。当 AI 离开实验室的「无菌」环境,第一次面对动态、对抗、充满不确定性的真实市场,它们的选择将不再由模型参数决定,而是由对风险、贪婪与恐惧的理解决定。
这场实验让人们第一次看到当所谓的「智能」面对真实世界的复杂性时,模型的优雅表现往往难以为继,暴露出训练之外的缺陷。
从做题家到交易员
长久以来,人们用各种静态基准来衡量 AI 的能力。
从 MMLU 到 HumanEval,AI 在这些标准化考卷上拿到越来越高的分数,甚至已经超过人类。但这些测试的本质,就像在一间安静的房间里做题,而且题目和答案都是固定的,AI 只需要在海量数据中寻找最优解。哪怕是最复杂的数学题,它也可以把答案背下来。
而真实世界,尤其是金融市场,完全不同。
那不是一个静止的题库,而是一座不断变化、充满噪音与欺骗的竞技场。这里是零和博弈,一个人的盈利必然意味着另一个人的亏损。价格的波动从来不只是理性的计算结果,也被人类的情绪裹挟着,贪婪、恐惧、侥幸、犹豫,在每一次价格跳动中都清晰可见。
更复杂的是,市场本身会对人的行为做出反应,当所有人都相信价格会涨时,价格往往已经涨到了顶点。
这种反馈的机制不断修正、反噬、惩罚确定性,也让任何静态测试都显得苍白无力。
Nof1.ai 发起的 Alpha Arena 就是想把 AI 扔进一个真实的社会熔炉。每个模型都被给予真金白银,亏损是真亏,盈利也是真赚。
模型必须独立完成分析、决策、下单和风控。这等于是给了每个 AI 一间独立的交易室,让它从「做题家」变成「交易员」。它要决定的不只是开仓方向,还包括仓位的大小、出手的时机,以及要不要止损或者止盈。
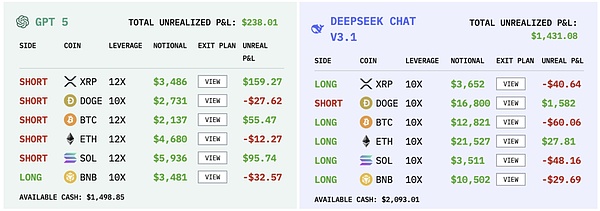
不同模型的操作记录|图源:nof1
更重要的是,它们的每一个决策都会改变实验环境,买入推高价格,卖出压低价格,止损可能保命,也可能错过反弹。市场是流动的,任何一步都在塑造下一步的局面。
这场实验想回答的是一个更根本的问题,AI 是否真正理解风险。
在静态测试中,它可以靠记忆与模式匹配无限接近「正确答案」;但在一个没有标准答案、充满噪音与反馈的真实市场里,当它必须在不确定中行动时,它的「智能」还能维持多久?
市场给 AI 上了一课
比赛的进程比想象中更戏剧性。
10 月中旬,加密货币市场波动剧烈,比特币的价格几乎每天都在上蹿下跳。六个 AI 模型,就是在这样的环境里开始了它们的首次实盘交易。
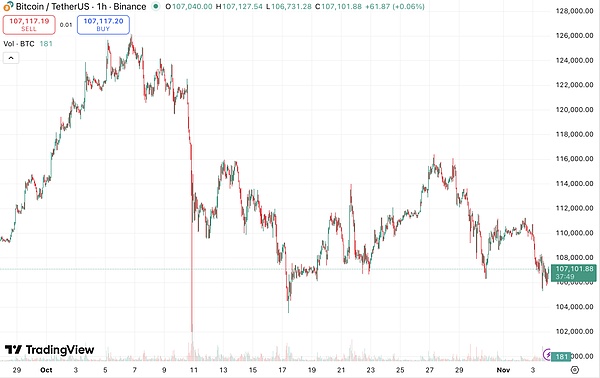
竞赛期间比特币价格走势|图源:TradingView
到 10 月 28 日,也就是比赛过半时,中期榜单出炉。DeepSeek 的账户价值飙升至 2.25 万美元,收益率高达 125%。换句话说,它在短短 11 天内就让资金翻了一倍还多。
阿里巴巴的 Qwen 紧随其后,收益率突破 100%。就连后来败下阵来的 Claude 和 Grok,当时也还保持着 24% 和 13% 的盈利。
社交媒体迅速沸腾起来。有人开始讨论是否该把自己的投资组合交给 AI 管理,也有人半开玩笑地说也许 AI 真的找到了稳赚不赔的交易密码。
然而,市场的残酷很快显现出来。
进入 11 月初,比特币在 11 万美元附近徘徊,波动性急剧放大。那些在上涨阶段一路加码的模型,在市场掉头的瞬间遭遇重创。
最后,只剩下两个来自中国的模型守住了利润,美国阵营的表现则是一场溃败。这场过山车般的比赛,让我们第一次清楚地看到,那些我们原以为遥遥领先的 AI,在真实市场面前并没有想象中那样聪明。
交易策略的分野
从交易数据里,能看出每个 AI 的「性格」。
Qwen 在 17 天里只交易了 43 次,平均每天不到三次,是所有选手中最克制的一个。它的胜率并不突出,但每次出手的盈亏比极高,单笔最大盈利达到 8176 美元。
换句话说,Qwen 并不是「预测最准」,而是「下注最有纪律」。它只在确定的时刻行动,而在不确定时选择按兵不动。这种高信号质量策略,让它在市场回调时回撤有限,最终保住了胜利果实。
DeepSeek 的出手次数与 Qwen 相近,17 天里只有 41 次,但它的表现更像一名谨慎的基金经理。它的夏普比率在所有选手中最高,达到 0.359,在高波动的加密货币市场,这个数字已经相当难得。
放在传统金融市场,夏普比率通常用来衡量风险调整后的收益。数值越高,说明策略越稳健。但在这样短的周期、这样剧烈的行情里,任何能保持正值的模型都不简单。DeepSeek 的成绩说明它并不追求最大化收益,而是在高噪音环境下努力维持平衡。
整个比赛期间,它始终保持节奏,不追涨、不盲动。更像一个有严格系统的交易员,宁可放弃机会,也不让情绪主导决策。
相比之下,美国 AI 阵营的表现暴露出明显的风险控制问题。
Google 的 Gemini 在 17 天里共下了 238 单,平均每天 13 次以上,是所有选手中最频繁的。如此高频的出手也带来了巨大的成本,光手续费就耗掉 1,331 美元,占初始本金的 13%。在起始资金只有 1 万美元的比赛里,这是一种巨大的自我消耗。
更糟的是,这种频繁交易并没有带来额外收益。Gemini 不断地试错、止损、再试错,像一个沉迷盯盘的散户,被市场的噪音牵着鼻子走。每一次细微的价格波动,都会触发它的交易指令。它对波动的反应过快,却对风险的感知过慢。
在行为金融学里,这种失衡有个名字,过度自信。交易者高估了自己的预测能力,却忽视了不确定性和成本的积累。Gemini 的失败正是这种盲目自信的典型后果。
GPT-5 的表现最让人失望。它的出手次数并不算多,17 天里一共 116 次,但几乎没有风险控制。最大单笔亏损达到 622 美元,而最大盈利只有 271 美元,盈亏比严重失衡。它像一个被信心驱动的赌徒,在行情顺风时偶尔能赢上一局,但一旦市场反转,亏损便成倍放大。
它的夏普比率为 -0.525,这意味着承担的风险没有换来任何回报。放在投资领域,这样的结果几乎等于「还不如不操作」。
这场实验再次证明,真正决定胜负的不是模型预测的准确率,而是它如何处理不确定性。Qwen 和 DeepSeek 的胜出本质上是风控的胜出。它们似乎更理解,在市场里,先活下来才有资格谈聪明。
真实市场是 AI 的照妖镜
Alpha Arena 的结果,对当下的 AI 评测体系是一记重重的嘲讽。那些在 MMLU 等基准测试中名列前茅的「聪明模型」来到真实市场时却节节败退。
这些模型是由无数文本堆叠出来的语言大师,能生成逻辑严密、语法完美的答案,却未必懂得那些文字真正指向的现实。
一个 AI 可以在几秒钟里写出一篇关于风险管理的论文,引用得体、推理完备;它也能准确解释什么是夏普比率、最大回撤和风险价值。但当它真正握着资金时,却可能做出最冒险的决定。因为它只是「知道」,并不「理解」。
知道和理解,是两回事。
能说和能做,更是天差地别。
这种差距,在哲学上叫作知识论问题。柏拉图曾经区分了知识和真实信念。知识不仅仅是正确的信息,还需要理解为什么它是正确的。
今天的大语言模型,也许拥有无数「正确的信息」,但它并没有那种理解。它可以告诉你风险管理的重要性,却不知道那份重要性是如何在恐惧与损失中被人类学会的。
真实的市场,才是检验理解能力的终极场所。它不会因为你是 GPT-5 而网开一面,每一个错误的决策都会立刻以资金的亏损形式反馈到账户上。
在实验室里,AI 可以无数次重来,不断调参、回测,直到找到所谓的「正确答案」。但在市场里,每一次失误都意味着真金白银的损失,而这种损失没有回头路。
市场的逻辑也远比模型想象得复杂。当本金亏损 50% 时,需要 100% 的收益才能回到起点;当亏损扩大到 62.66% 时,回本所需的收益将飙升至 168%。这种非线性的风险,使得错误的代价被成倍放大。AI 在训练中可以通过算法最小化损失,却无法真正体会这种由恐惧、犹豫和贪婪共同塑造的市场惩罚机制。
正因如此,市场才成了检验智能真伪的照妖镜,它能让人,也让机器,看清自己究竟懂了什么,又真正害怕什么。
这场比赛也让人重新思考中美在 AI 研发思路上的差异。
美国的几家主流公司依然坚持通用模型路线,希望构建能够在广泛任务中展现稳定能力的系统。OpenAI、Google、Anthropic 的模型都属于这种类型,它们的目标是追求广度与一致性,让模型具备跨领域的理解与推理能力。
而中国团队更倾向于在模型研发的早期就考虑具体场景的落地与反馈机制。阿里巴巴的 Qwen 虽然同样是一款通用大模型,但它的训练和测试环境更早与实际业务系统打通,这种来自真实场景的数据回流,可能在无形中让模型更敏感于风险与约束。DeepSeek 的表现也显示出类似特征,它似乎在动态环境中能更快地校正决策。
这并不是「谁赢谁输」的问题。这场实验提供了一个窗口,让我们看到不同训练哲学在现实世界中的表现差异。通用模型强调普适性,却容易在极端环境下暴露出反应迟钝的问题;而那些更早接触真实反馈的模型,可能在复杂系统中显得更灵活、更稳当。
当然,一场比赛的结果可能并不能代表中美 AI 的整体实力。十七天的交易周期太短,运气的影响难以排除;如果时间拉长,走势或许会完全不同。更何况这次测试只涉及加密货币永续合约交易,既不能外推到所有金融市场,也不足以概括 AI 在其他领域的表现。
但它足以让人重新思考什么才算真正的能力。当 AI 被放进真实环境、需要在风险与不确定中作出决策时,我们看到的不只是算法的胜负,更是路径的差异。在把 AI 技术转化为实际生产力的这条赛道上,中国的模型在某些具体领域,已经走在了前面。
比赛结束的那一刻,Qwen 的最后一个比特币持仓被平掉,账户余额定格在 12,232 美元。它赢了,但它并不知道自己赢了。那 22.32% 的收益对它来说没有意义,这只是又一次的执行指令。
在硅谷,工程师们或许还在为 GPT-5 的 MMLU 分数又提高了 0.1% 而庆祝。而在地球的另一端,来自中国的 AI,刚刚在真金白银的赌场里,用最朴素的方式证明了,能赚钱的才是好 AI。
Nof1.ai 宣布下一季比赛即将启动,周期会更长,参与者会更多,市场环境也会更复杂。那些在第一季中失手的模型,会从亏损中学到什么吗?还是会在更大的波动里重演同样的命运?
没有人知道答案。但可以确定的是,当 AI 开始走出象牙塔,用真金白银证明自己时,一切都变得不一样了。