Author: Sleepy.txt

In the early morning of November 4th, the much-anticipated Alpha Arena AI trading competition came to an end.
The results surprised everyone, with Alibaba’s Qwen 3 Max taking the top spot with a yield of 22.32%, and another Chinese company, DeepSeek, in second place with a yield of 4.89%.
The four star players from Silicon Valley were defeated across the board.OpenAI’s GPT-5 lost 62.66%, Google’s Gemini 2.5 Pro lost 56.71%, Musk’s Grok 4 lost 45.3%, and Anthropic’s Claude 4.5 Sonnet also lost 30.81%.
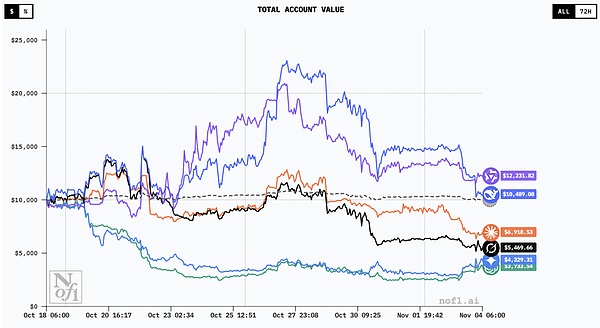
Trading curves of all models|Source: nof1
This game is actually a special experiment.On October 17, the American research company Nof1.ai put six of the world’s top large language models into the real cryptocurrency market. Each model received an initial capital of US$10,000 to conduct 17-day perpetual contract trading on the decentralized trading platform Hyperliquid.Perpetual contracts are derivatives with no expiration date that allow traders to magnify returns through leverage, but at the same time, they also magnify risks.
These AIs start from the same starting point, have the same market data, but end up with completely different results.
This is not a benchmark test in a virtual environment, but a survival game with real money.When AI leaves the “sterile” environment of the laboratory and faces a dynamic, confrontational, and uncertain real market for the first time, their choices will no longer be determined by model parameters, but by their understanding of risk, greed, and fear.
This experiment allowed people to see for the first time that when so-called “intelligence” faces the complexity of the real world, the elegant performance of the model is often unsustainable, exposing flaws beyond training.
From question maker to trader
For a long time, people have used various static benchmarks to measure the capabilities of AI.
From MMLU to HumanEval, AI is getting higher and higher scores on these standardized test papers, even surpassing humans.But the essence of these tests is like doing questions in a quiet room, and the questions and answers are fixed. AI only needs to find the optimal solution in massive data.It can memorize the answers to even the most complex math problems.
The real world, especially financial markets, is completely different.
It is not a static question bank, but an ever-changing arena full of noise and deception.This is a zero-sum game, and one person’s gain must mean another person’s loss.Price fluctuations are never just the result of rational calculations, but are also affected by human emotions. Greed, fear, luck, and hesitation are clearly visible in every price jump.
To make things more complicated, the market itself responds to human behavior. When everyone believes that prices will rise, prices have often reached their peak.
This feedback mechanism constantly corrects, backfires, and punishes certainty, making any static testing pale in comparison.
The Alpha Arena launched by Nof1.ai wants to throw AI into a real social melting pot.Each model is given real money, losses are real losses, and profits are real profits.
The model must independently complete analysis, decision-making, order placement and risk control.This is equivalent to giving each AI an independent trading room, turning it from a “question maker” to a “trader”.It has to decide not only the direction of opening a position, but also the size of the position, the timing of taking action, and whether to stop loss or take profit.
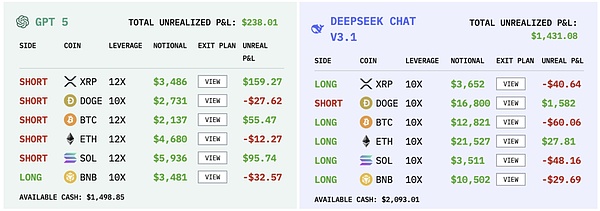
Operation records of different models|Source: nof1
More importantly, every decision they make will change the experimental environment. Buying will push the price up, selling will push the price down. Stop loss may save your life, or you may miss the rebound.The market is fluid, and every step shapes the next step.
What this experiment wants to answer is a more fundamental question, whether AI truly understands risk.
In static tests, it can rely on memory and pattern matching to get infinitely close to the “correct answer”; but in a real market where there is no standard answer and is full of noise and feedback, how long can its “intelligence” last when it must act in uncertainty?
The market teaches AI a lesson
The progress of the game was more dramatic than imagined.
In mid-October, the cryptocurrency market was extremely volatile, with the price of Bitcoin jumping up and down almost daily.It was in this environment that six AI models started their first real trading.
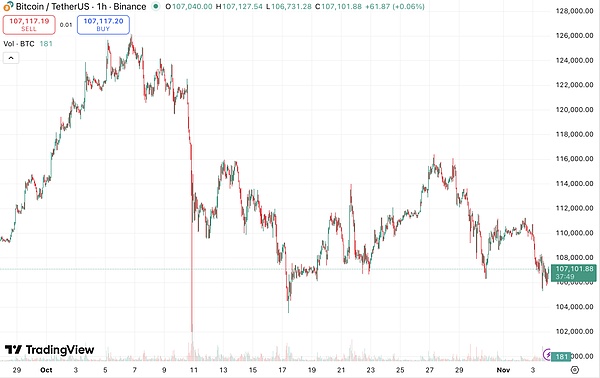
Bitcoin price trend during the competition|Source: TradingView
By October 28, halfway through the tournament, the mid-term rankings were announced.DeepSeek’s account value soared to $22,500, with a 125% return.In other words, it more than doubled its money in just 11 days.
Alibaba’s Qwen followed suit, with yields exceeding 100%.Even Claude and Grok, who were later defeated, still maintained profits of 24% and 13% at the time.
Social media quickly went viral.Some people began to discuss whether they should hand over their investment portfolios to AI management, and some people half-jokingly said that maybe AI has really found a trading code that is sure to make money without losing money.
However, the cruelty of the market soon became apparent.
Entering early November, Bitcoin was hovering near $110,000, with volatility amplifying sharply.Those models that increased their bets all the way during the uptrend suffered heavy losses when the market turned around.
In the end, only two models from China were able to maintain profits, and the performance of the American camp was a rout.This roller-coaster game allowed us to clearly see for the first time that the AIs we thought were far ahead were not as smart as imagined in the real market.
Divide of trading strategies
From the transaction data, the “personality” of each AI can be seen.
Qwen only traded 43 times in 17 days, an average of less than three times a day, and was the most restrained of all players.Its winning rate is not outstanding, but its profit-loss ratio per shot is extremely high, with the maximum profit in a single transaction reaching $8,176.
In other words, Qwen is not “the most accurate in predictions”, but “the most disciplined in betting”.It only acts when it is certain and chooses to stand still when it is uncertain.This high signal quality strategy allowed it to have limited retracements during market corrections and ultimately preserved the fruits of victory.
DeepSeek had a similar number of moves as Qwen, with just 41 in 17 days, but it behaved more like a cautious fund manager.It has the highest Sharpe ratio among all players, reaching 0.359, a number that is already quite rare in the highly volatile cryptocurrency market.
In traditional financial markets, the Sharpe ratio is usually used to measure risk-adjusted returns.The higher the value, the more robust the strategy.But in such a short cycle and such a violent market, any model that can maintain a positive value is not simple.DeepSeek’s results show that it does not pursue maximizing returns, but strives to maintain balance in a high-noise environment.
During the entire game, it always maintained the rhythm and did not chase the increase or move blindly.More like a trader with a strict system, he would rather give up opportunities than let emotions dominate decision-making.
In contrast, the performance of the U.S. AI camp exposes obvious risk control problems.
Google’s Gemini placed a total of 238 orders in 17 days, an average of more than 13 times a day, the most frequent among all players.Such high-frequency transactions also brought huge costs, with handling fees alone costing US$1,331, accounting for 13% of the initial principal.In a tournament with a starting bankroll of only $10,000, this is a huge drain on yourself.
What’s worse is that this frequent trading does not bring additional revenue.Gemini keeps trying and making mistakes, stopping losses, and trying again and again, like a retail investor obsessed with watching the market, being led by the noise of the market.Every slight price fluctuation will trigger its trading order.It reacts too quickly to fluctuations and perceives risk too slowly.
In behavioral finance, this imbalance has a name, overconfidence.Traders overestimate their forecasting abilities but ignore the accumulation of uncertainty and costs.Gemini’s failure is a typical consequence of this blind confidence.
The performance of GPT-5 is most disappointing.It didn’t take many shots, 116 in 17 days, but had little risk control.The largest single loss reached US$622, while the largest profit was only US$271. The profit-loss ratio was seriously imbalanced.It is like a gambler driven by confidence. He can occasionally win when the market goes well, but once the market reverses, the losses will be multiplied.
It has a Sharpe ratio of -0.525, which means it took no risk in exchange for any reward.In the field of investment, this result is almost equivalent to “it is better not to operate.”
This experiment once again proves that what really determines victory or defeat is not the accuracy of the model’s predictions, but how it handles uncertainty.The victory of Qwen and DeepSeek is essentially a victory of risk control.They seem to understand better that in the market, only by surviving first can you be considered smart.
The real market is AI’s mirror
The results of Alpha Arena are a heavy mockery of the current AI evaluation system.Those “smart models” that rank among the best in benchmark tests such as MMLU are losing ground when they come to the real market.
These models are language masters stacked up from countless texts. They can generate answers with strict logic and perfect grammar, but they may not understand the reality that those texts really point to.
An AI can write a paper on risk management in a few seconds, with decent citations and complete reasoning; it can also accurately explain what Sharpe ratio, maximum drawdown and value at risk are.But when it actually holds the money, it can make the riskiest decisions.Because it only “knows” and does not “understand”.
Knowing and understanding are two different things.
There is a huge difference between being able to say it and being able to do it.
This gap is called an epistemological problem in philosophy.Plato once distinguished between knowledge and true belief.Knowledge is not just correct information, but also an understanding of why it is correct.
Today’s big language models may have tons of “correct information,” but they don’t have that kind of understanding.It can tell you the importance of risk management, but it doesn’t know how that importance is learned by humans from fear and loss.
The real market is the ultimate place to test your understanding.It will not be lenient just because you are GPT-5. Every wrong decision will be immediately fed back to the account in the form of a loss of funds.
In the laboratory, AI can be repeated countless times, constantly adjusting parameters and backtesting until it finds the so-called “correct answer.”But in the market, every mistake means a loss of real money, and there is no turning back for this loss.
The logic of the market is also far more complex than the model imagines.When the principal is lost by 50%, a 100% return is required to return to the starting point; when the loss expands to 62.66%, the return required to return the principal will soar to 168%.This nonlinear risk multiplies the cost of errors.AI can minimize losses through algorithms during training, but it cannot truly understand the market punishment mechanism shaped by fear, hesitation and greed.
Because of this, the market has become a mirror to test the authenticity of intelligence. It allows people and machines to see clearly what they really know and what they are really afraid of.
This game also makes people rethink the differences in AI R&D ideas between China and the United States.
Several mainstream companies in the United States still adhere to the common model route, hoping to build systems that can demonstrate stable capabilities in a wide range of tasks.The models of OpenAI, Google, and Anthropic all belong to this type. Their goal is to pursue breadth and consistency, so that the model has cross-domain understanding and reasoning capabilities.
The Chinese team prefers to consider the implementation and feedback mechanism of specific scenarios in the early stages of model development.Although Alibaba’s Qwen is also a general-purpose large model, its training and testing environment has been connected to the actual business system earlier. This data reflow from real scenarios may invisibly make the model more sensitive to risks and constraints.DeepSeek’s performance shows similar characteristics, as it appears to be able to correct decisions faster in dynamic environments.
This is not a question of “who wins and who loses.”This experiment provides a window into how different training philosophies perform in the real world.General-purpose models emphasize universality, but are prone to unresponsiveness in extreme environments; while those models that are exposed to real feedback earlier may appear more flexible and stable in complex systems.
Of course, the results of one game may not represent the overall strength of Chinese and American AI.The seventeen-day trading cycle is too short, and the influence of luck is difficult to rule out; if the time is extended, the trend may be completely different.What’s more, this test only involves cryptocurrency perpetual contract trading, which can neither be extrapolated to all financial markets, nor is it sufficient to generalize the performance of AI in other fields.
But it’s enough to make one rethink what constitutes true ability.When AI is put into a real environment and needs to make decisions amid risks and uncertainties, what we see is not only the success or failure of the algorithm, but also the difference in paths.On the track of transforming AI technology into actual productivity, China’s model has already taken the lead in certain specific areas.
At the moment the game ended, Qwen’s last Bitcoin position was closed, leaving his account balance at $12,232.It won, but it didn’t know it had won.That 22.32% gain means nothing to it, it’s just another execution order.
In Silicon Valley, engineers may still be celebrating another 0.1% improvement in GPT-5’s MMLU score.On the other side of the world, AI from China has just proved in the simplest way in a real money casino that only good AI can make money.
Nof1.ai announced that the next season of competition is about to start. The cycle will be longer, there will be more participants, and the market environment will be more complex.Will the models that failed in the first season learn anything from their losses?Or will the same fate repeat itself with greater fluctuations?
No one knows the answer.But what is certain is that when AI starts to step out of the ivory tower and prove itself with real money, everything will be different.